导航
智能合约
贪心算法
华为机试
最优假彩色合成
node
https
insert into
paas
Setup 函数的使用
流媒体
在线聊天系统
信号完整性
P3C
可视化
3D建模
SpaceEngineer
kylin
天际线启发式
电力
预训练模型
2024/4/11 17:01:17
Talk | 微软亚洲研究院宋恺涛南大余博涛:面向文本/音乐序列任务的Transformer注意力机制设计
本期为TechBeat人工智能社区第456期线上Talk! 北京时间11月22日(周二)20:00,微软亚洲研究院研究员——宋恺涛与南京大学硕士研究生——余博涛的Talk将准时在TechBeat人工智能社区开播! 他们与大家分享的主题是: “面向文本/音乐序列任务的Tra…
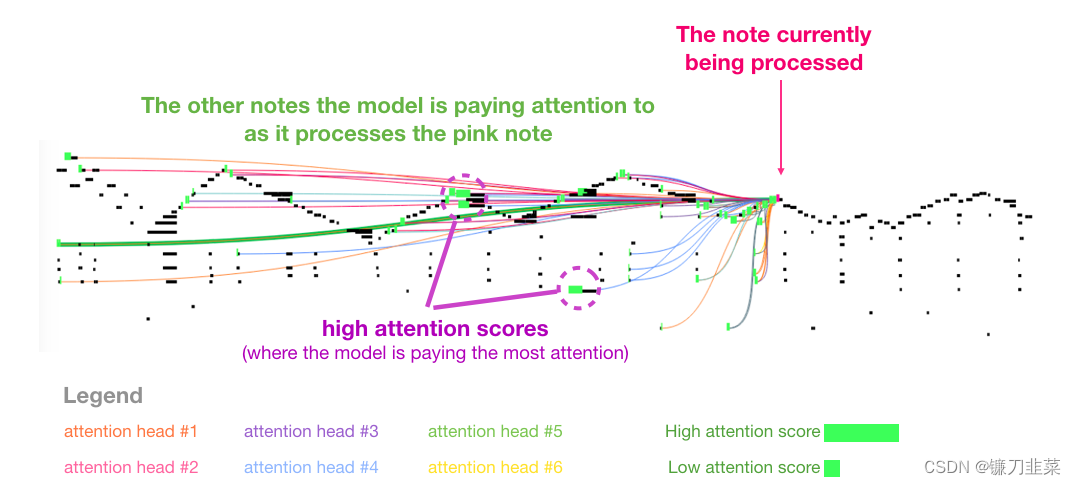
【AI理论学习】语言模型:深入理解GPT-2计算掩码自注意力过程,了解GPT-3工作原理
深入理解GPT-2计算掩码自注意力过程,了解GPT-3工作原理 图解Self-Attention图解 Self-Attention(without masking)1. 创建Query、Key和Value向量2. 计算分数3. 计算和 图解 Masked Self-AttentionGPT-2 Masked Self-Attention评价模型&#x…
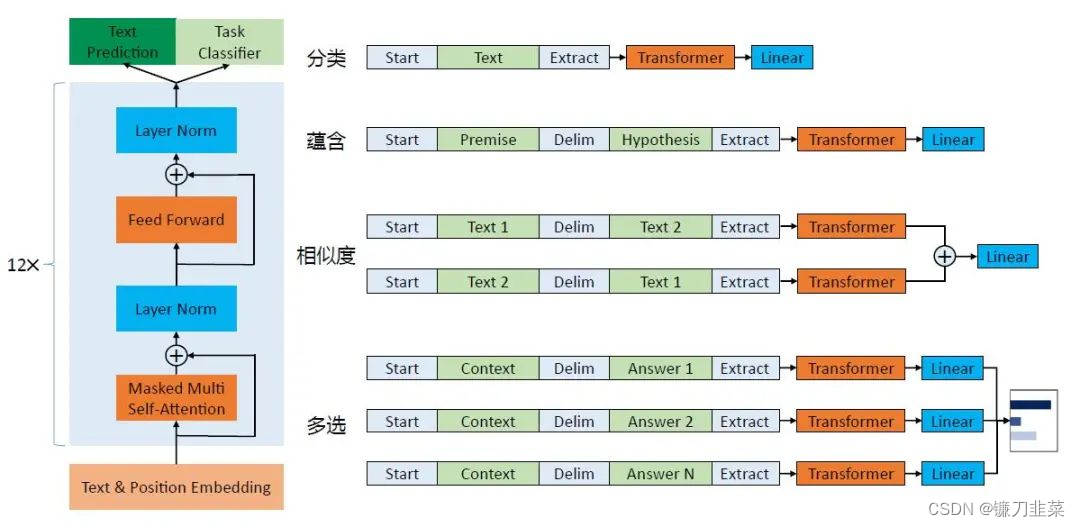
【AI理论学习】语言模型:掌握BERT和GPT模型
语言模型:掌握BERT和GPT模型 BERT模型BERT的基本原理BERT的整体架构BERT的输入BERT的输出 BERT的预训练掩码语言模型预测下一个句子 BERT的微调BERT的特征提取使用PyTorch实现BERT GPT模型GPT模型的整体架构GPT的模型结构GPT-2的Multi-Head与BERT的Multi-Head之间的…

Amazon Generative AI | 基于 Amazon 扩散模型原理的代码实践之采样篇
以前通过论文介绍 Amazon 生成式 AI 和大语言模型(LLMs)的主要原理之外,在代码实践环节主要还是局限于是引入预训练模型、在预训练模型基础上做微调、使用 API 等等。很多开发人员觉得还不过瘾,希望内容可以更加深入。因此&#x…

获取token i 都 token j 的影响力
文章目录Perturbed MaskingPerturbed Masking
Perturbed Masking 是港大和华为ACL20提出的。 重复上述操作,会得到一个每一对token的影响度的矩阵。
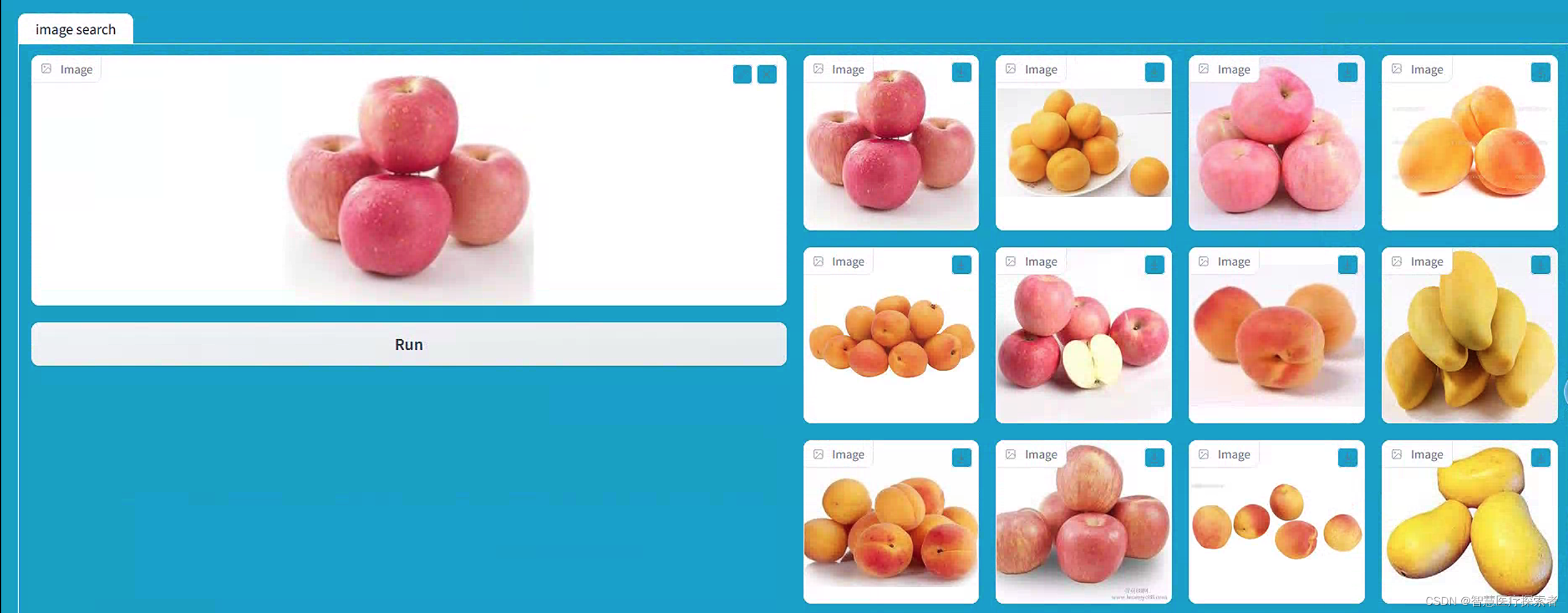
向量检索:基于ResNet预训练模型构建以图搜图系统
1 项目背景介绍
以图搜图是一种向量检索技术,通过上传一张图像来搜索并找到与之相关的其他图像或相关信息。以图搜图技术提供了一种更直观、更高效的信息检索方式。这种技术应用场景和价值非常广泛,经常会用在商品检索及购物、动植物识别、食品识别、知…

BERT模型结构可视化与模块维度转换剖析
大家好,我是herosunly。985院校硕士毕业,现担任算法研究员一职,热衷于机器学习算法研究与应用。曾获得阿里云天池比赛第一名,科大讯飞比赛第三名,CCF比赛第四名。拥有多项发明专利。对机器学习和深度学习拥有自己独到的见解。曾经辅导过若干个非计算机专业的学生进入到算法…

BERT模型的若干问题整理记录 思考
1.BERT的基本原理是什么?
BERT来自Google的论文Pre-training of Deep Bidirectional Transformers for Language Understanding,BERT是”Bidirectional Encoder Representations from Transformers”的首字母缩写,整体是一个自编码语言模型&…
GPT和BERT优缺点比较
GPT(Generative Pre-Training)和BERT(Bidirectional Encoder Representation from Transformers)都是以Transformer为主题架构的预训练语言模型,都是通过“预训练fine tuning”的模式下完成下游任务的搭建
从模型的角度上
1) GPT是单向模型,…
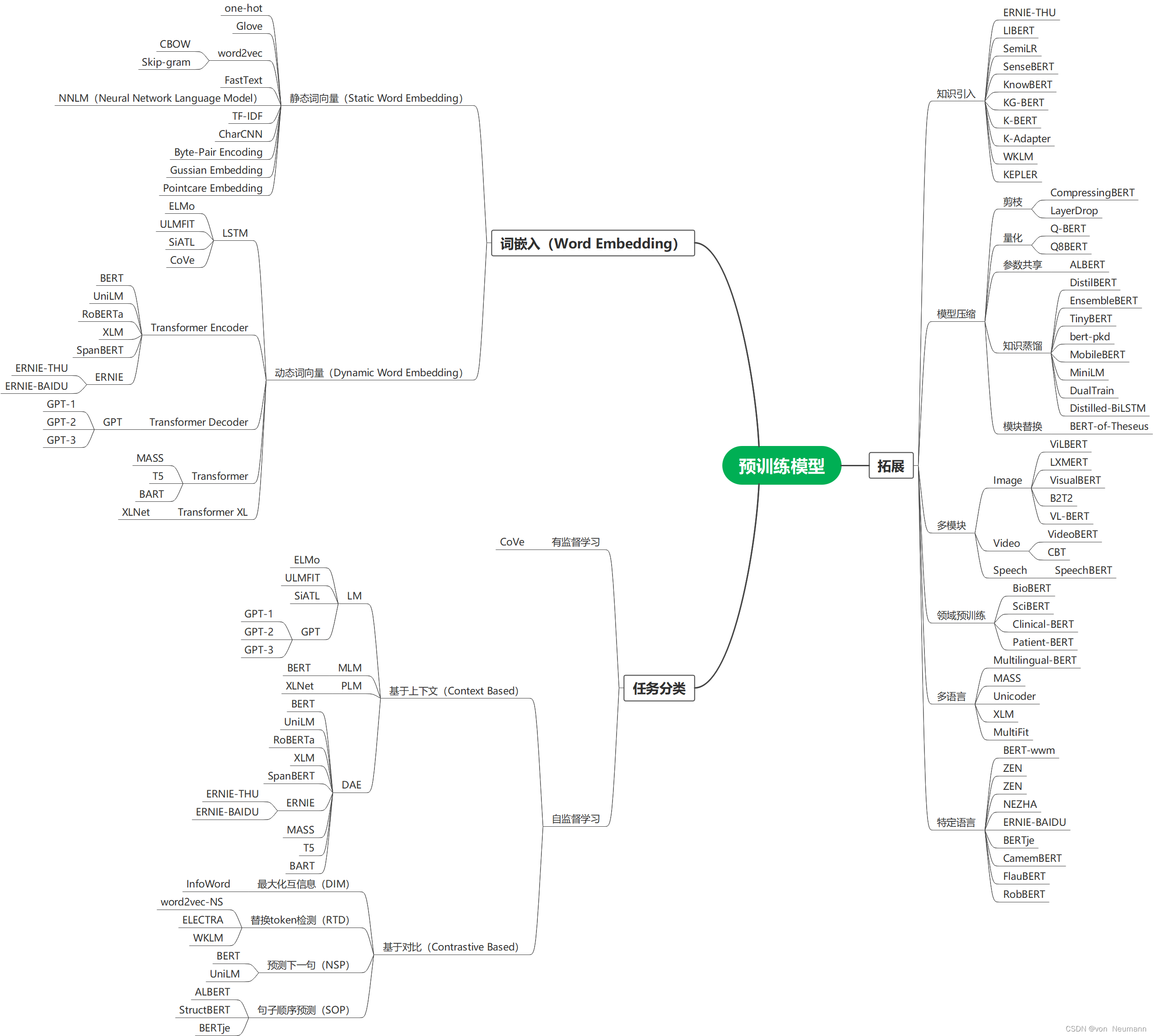
自然语言处理从入门到应用——预训练模型总览:预训练模型存在的问题
分类目录:《自然语言处理从入门到应用》总目录 相关文章: 预训练模型总览:从宏观视角了解预训练模型 预训练模型总览:词嵌入的两大范式 预训练模型总览:两大任务类型 预训练模型总览:预训练模型的拓展 …

DeBERTaV3: Improving DeBERTa using ELECTRA-Style Pre-Training with Gradient-Disentangled Embedding解读
一、概述
二、详细内容
abstract a. deberataV3, debearta的改进版本 b. 方法1(改进mlm):通过使用RTD来替换原始的MLM任务,一个更有效的简单的预训练方法 c. 方法2(改进electra): ⅰ. 原因&a…
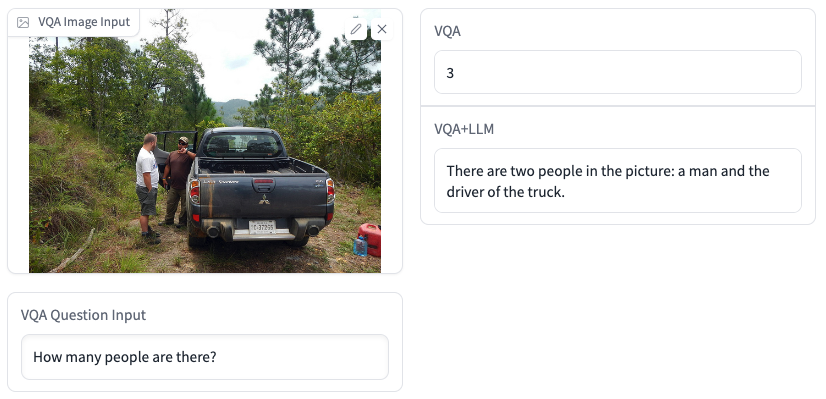
VLE基于预训练文本和图像编码器的图像-文本多模态理解模型:支持视觉问答、图文匹配、图片分类、常识推理等
项目设计集合(人工智能方向):助力新人快速实战掌握技能、自主完成项目设计升级,提升自身的硬实力(不仅限NLP、知识图谱、计算机视觉等领域):汇总有意义的项目设计集合,助力新人快速实…
Amazon Generative AI 新世界 | 基于 Amazon 扩散模型原理的代码实践之采样篇
以前通过论文介绍 Amazon 生成式 AI 和大语言模型(LLMs)的主要原理之外,在代码实践环节主要还是局限于是引入预训练模型、在预训练模型基础上做微调、使用 API 等等。很多开发人员觉得还不过瘾,希望内容可以更加深入。因此&#x…

文献阅读:Should You Mask 15% in Masked Language Modeling?
文献阅读:Should You Mask 15% in Masked Language Modeling? 1. 内容简介2. 实验考察 1. mask比例考察2. corruption & prediction3. 80-10-10原则考察4. mask选择考察 3. 结论 & 思考 文献链接:https://arxiv.org/pdf/2202.08005.pdf
1. 内…
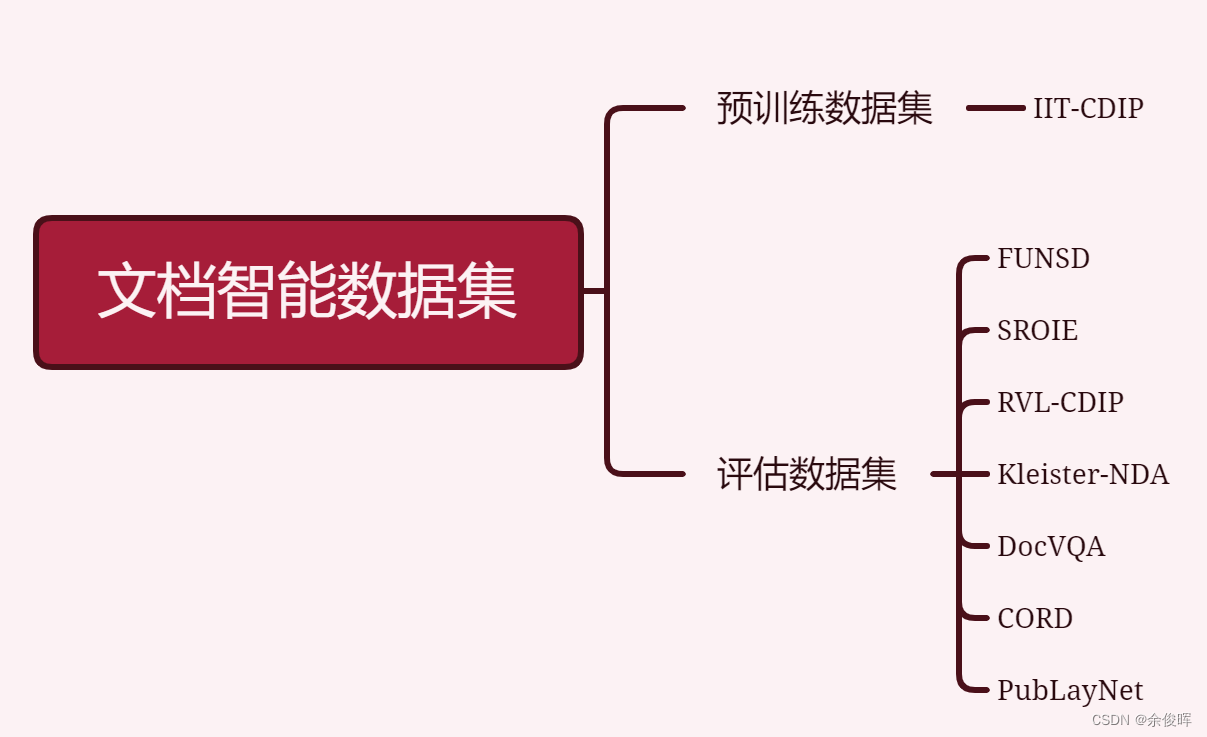
【文档智能】多模态预训练模型及相关数据集汇总
前言
大模型时代,在现实场景中或者企业私域数据中,大多数数据都以文档的形式存在,如何更好的解析获取文档数据显得尤为重要。文档智能也从以前的目标检测(版面分析)阶段转向多模态预训练阶段,本文将介绍目…

使用预训练模型自动续写文本的四种方法
作者:皮皮雷 来源:投稿 编辑:学姐 这篇文章以中文通用领域文本生成为例,介绍四种常用的模型调用方法。在中文文本生成领域,huggingface上主要有以下比较热门的pytorch-based预训练模型: 本文用到了其中的ue…
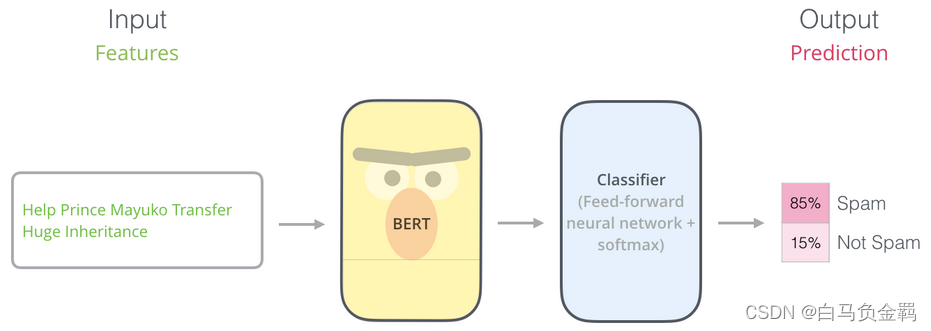
BERT(从理论到实践): Bidirectional Encoder Representations from Transformers【3】
这是本系列文章中的第3弹,请确保你已经读过并了解之前文章所讲的内容,因为对于已经解释过的概念或API,本文不会再赘述。
本文要利用BERT实现一个“垃圾邮件分类”的任务,这也是NLP中一个很常见的任务:Text Classification。我们的实验环境仍然是Python3+Tensorflow/Keras…
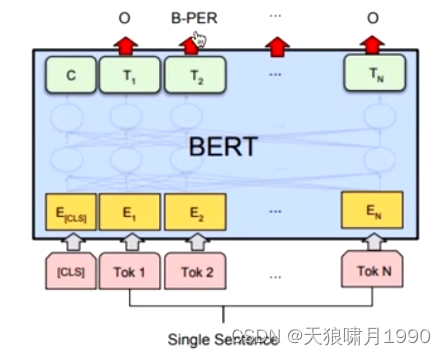
预训练机制(3)~GPT、BERT
目录
1. BERT、GPT 核心思想
1.1 word2vec和ELMo区别 2 GPT编辑
3. Bert
3.1 Bert集大成者
extension:单向编码--双向编码区别
3.2 Bert和GPT、EMLo区别
3.3 Bert Architecture
3.3.1 explanation:是否参数多、数据量大,是否过拟…
![深度学习进阶篇-国内预训练模型[6]:ERNIE-Doc、THU-ERNIE、K-Encoder融合文本信息和KG知识;原理和模型结构详解。](https://img-blog.csdnimg.cn/img_convert/eafad84b81b8503e6075273425866556.png)
深度学习进阶篇-国内预训练模型[6]:ERNIE-Doc、THU-ERNIE、K-Encoder融合文本信息和KG知识;原理和模型结构详解。
【深度学习入门到进阶】必看系列,含激活函数、优化策略、损失函数、模型调优、归一化算法、卷积模型、序列模型、预训练模型、对抗神经网络等 专栏详细介绍:【深度学习入门到进阶】必看系列,含激活函数、优化策略、损失函数、模型调优、归一化…
深度学习:UserWarning: The parameter ‘pretrained‘ is deprecated since 0.13..解决办法
深度学习:UserWarning: The parameter ‘pretrained’ is deprecated since 0.13 and may be removed in the future, please use ‘weights’ instead. 解决办法
1 报错警告:
pytorch版本:0.14.1 在利用pytorch中的预训练模型时࿰…
![深度学习进阶篇[7]:Transformer模型长输入序列、广义注意力、FAVOR+快速注意力、蛋白质序列建模实操。](https://img-blog.csdnimg.cn/img_convert/15d0de3275239031b89367901bf89247.jpeg)
深度学习进阶篇[7]:Transformer模型长输入序列、广义注意力、FAVOR+快速注意力、蛋白质序列建模实操。
【深度学习入门到进阶】必看系列,含激活函数、优化策略、损失函数、模型调优、归一化算法、卷积模型、序列模型、预训练模型、对抗神经网络等 专栏详细介绍:【深度学习入门到进阶】必看系列,含激活函数、优化策略、损失函数、模型调优、归一化…
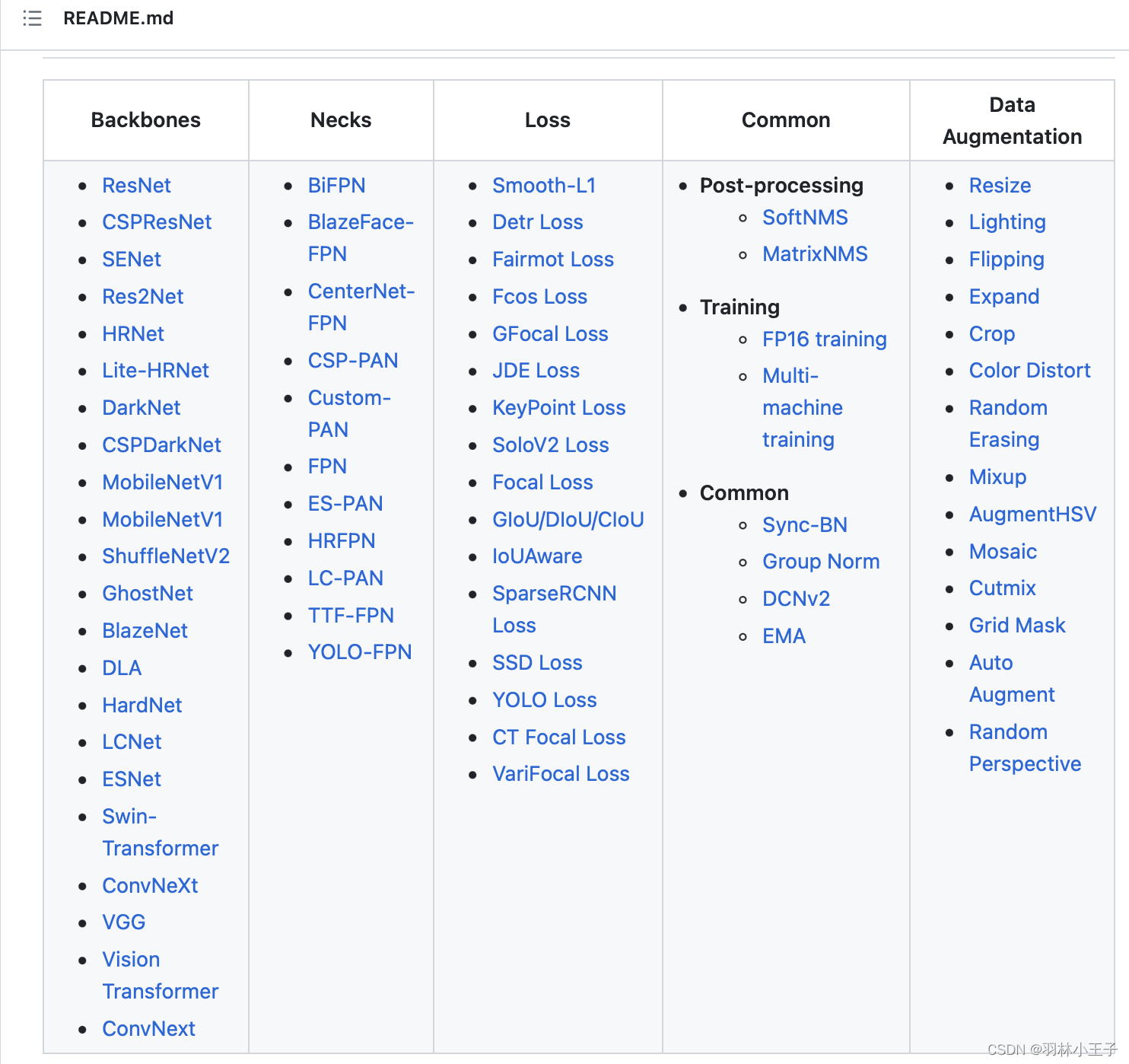
如何使用配置文件参数 - 实现预训练模型训练
如何使用配置文件参数 - 实现预训练模型训练 引言为什么使用配置文件来预训练模型呢 配置文件结构举例实现通过配置文件训练模型如何微调配置文件训练出优秀的模型呢数据集特征模型架构先前研究和经验超参数调优迭代实验和评估 引言
预训练模型在各个领域的应用取得了显著的成…
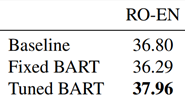
ACL2020论文阅读笔记:BART
背景
题目: BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension 机构:Facebook AI 作者:Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Moha…

【AI视野·今日NLP 自然语言处理论文速览 第八十二期】Tue, 5 Mar 2024
AI视野今日CS.NLP 自然语言处理论文速览 Tue, 5 Mar 2024 (showing first 100 of 175 entries) Totally 100 papers 👉上期速览✈更多精彩请移步主页 Daily Computation and Language Papers
Key-Point-Driven Data Synthesis with its Enhancement on Mathematica…
【视频】超越BERT的最强中文NLP预训练模型艾尼ERNIE官方揭秘
分章节视频链接:http://abcxueyuan.cloud.baidu.com/#/course_detail?id15076&courseId15076完整视频链接:http://play.itdks.com/watch/8591895
艾尼(ERNIE)是目前NLP领域的最强中文预训练模型。
百度资深研发工程师龙老师…