地图
英语
集合
自定义Toast
spring cloud
Debezium报错处理系列
人手检测
hevc
函数模板
程序员35
内联函数
几何
Pascal
零售
PCB设计
symbol
LIME
性能
微信扫码登录
ceph
图像生成
2024/4/12 3:21:56
【AI视野·今日CV 计算机视觉论文速览 第257期】Fri, 29 Sep 2023
AI视野今日CS.CV 计算机视觉论文速览 Fri, 29 Sep 2023 Totally 99 papers 👉上期速览✈更多精彩请移步主页 Daily Computer Vision Papers
Learning to Transform for Generalizable Instance-wise Invariance Authors Utkarsh Singhal, Carlos Esteves, Ameesh M…

ControlNet原理及应用
《Adding Conditional Control to Text-to-Image Diffusion Models》 目录
1.背景介绍
2.原理详解
2.1 Controlnet
2.2 用于Stable Diffusion的ControlNet
2.3 训练
2.4 推理
3.实验结果
3.1 定性结果
3.2 消融实验
3.3 和之前结果比较
3.4 数据集大小的影响
4.结…

APISpace 带你一起走进西湖美景
俗话说:“上有天堂,下有苏杭”。
“欲把西湖比西子,浓妆艳抹总相宜”
今天我就带大家走进杭州的西湖美景。自古以来,文人歌者面对西湖美景留下千古绝句,还以西湖为背景书写了一段段动人的爱情传说。
天生自带浪漫色…

论文阅读 - Understanding Diffusion Models: A Unified Perspective
文章目录 1 概述2 背景知识2.1 直观的例子2.2 Evidence Lower Bound(ELBO)2.3 Variational Autoencoders(VAE)2.4 Hierachical Variational Autoencoders(HVAE) 3 Variational Diffusion Models(VDM)4 三个等价的解释4.1 预测图片4.2 预测噪声4.3 预测分数 5 Guidance5.1 Class…

AIGC系列之:GroundingDNIO原理解读及在Stable Diffusion中使用
目录
1.前言
2.方法概括
3.算法介绍
3.1图像-文本特征提取与增强
3.2基于文本引导的目标检测
3.3跨模态解码器
3.4文本prompt特征提取
4.应用场景
4.1结合生成模型完成目标区域生成
4.2结合stable diffusion完成图像编辑
4.3结合分割模型完成任意图像分割
1.前言
…

浅析扩散模型与图像生成【应用篇】(四)——Palette
4. Palette: Image-to-Image Diffusion Models 该文提出一种基于扩散模型的通用图像转换(Image-to-Image Translation)模型——Palette,可用于图像着色,图像修复,图像补全和JPEG图像恢复等多种转换任务。Palette是一种…

No module named ‘pytorch_lightning.utilities.distributed‘
在按照stable- diffusion中,需要安装很多依赖。如果版本不对,则不能成功运行,标题的问题就是如此。
相关参考:stable- diffusion V1效果咋样呢?V2呢?安装成功记录。
解决方案: pip install py…

什么?30秒生成一个logo
logo 是徽标或者商标的英文说法。logo 承载着企业的无形资产,是企业综合信息传递的媒介。标志作为企业CIS战略的最主要部分,在企业形象传递过程中,是应用最广泛、出现频率最高,同时也是最关键的元素。通过形象的 logo 可以让消费者…

图像生成论文阅读:GLIDE算法笔记
标题:GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models 会议:ICML2022 论文地址:https://proceedings.mlr.press/v162/nichol22a.html 官方代码:https://github.com/openai/glide-…

StreamMultiDiffusion:可实现用户指定的区域文本提示来生成实时、交互式、多文本到图像的功能
StreamMultiDiffusion 是根据用户指定的区域文本提示生成实时 交互式 多文本到图像的功能。
该视频意味着该项目最终可以让你通过细粒度的区域提示控制来生成大尺寸图像。以前,这是根本不可行的。每次试验花费一个小时意味着你无法多次采样来选择你想要的最佳生成或…
![[PMLR 2021] Zero-Shot Text-to-Image Generation:零样本文本到图像生成](https://img-blog.csdnimg.cn/img_convert/eae8c832d9fd3e9b696a3f02bb50b96a.png)
[PMLR 2021] Zero-Shot Text-to-Image Generation:零样本文本到图像生成
[PMLR 2021]Zero-Shot Text-to-Image Generation:零样本文本到图像生成 Fig 1. 原始图像(上)和离散VAE重建图像(下)的比较。编码器对空间分辨率进行8倍的下采样。虽然细节(例如,猫毛的纹理、店面上的文字和插图中的细线)有时会丢失或扭曲,但图…

Midjourney入门:AI绘画真的能替代人类的丹青妙笔吗?
名人说:一花独放不是春,百花齐放花满园。——《增广贤文》 作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 目录 一、简要介绍1、Midjourney2、使用方法 二、绘画1、动物类2、风景类3、动漫类4、艺…
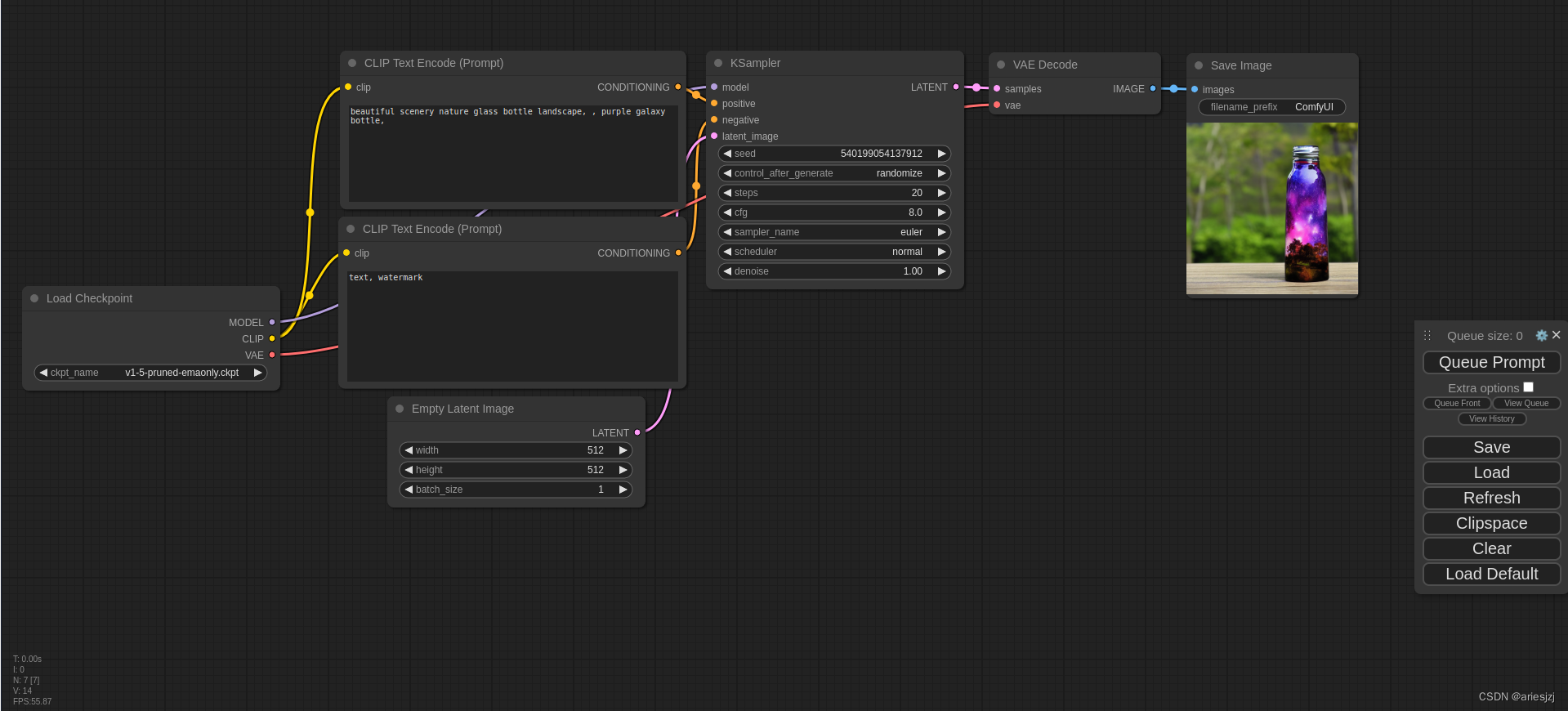
本地用AIGC生成图像与视频
最近AI界最火的话题,当属Sora了。遗憾的是,Sora目前还没开源或提供模型下载,所以没法在本地跑起来。但是,业界有一些开源的图像与视频生成模型。虽然效果上还没那么惊艳,但还是值得我们体验与学习下的。
Stable Diffu…
CVPR2024|AIGC(图像生成,视频生成等)相关论文汇总(附论文链接/开源代码/解析)【持续更新】
CVPR2024|AIGC相关论文汇总(如果觉得有帮助,欢迎点赞和收藏) Awesome-CVPR2024-AIGC1.图像生成(Image Generation/Image Synthesis)ECLIPSE: A Resource-Efficient Text-to-Image Prior for Image GenerationsInstanceDiffusion: …
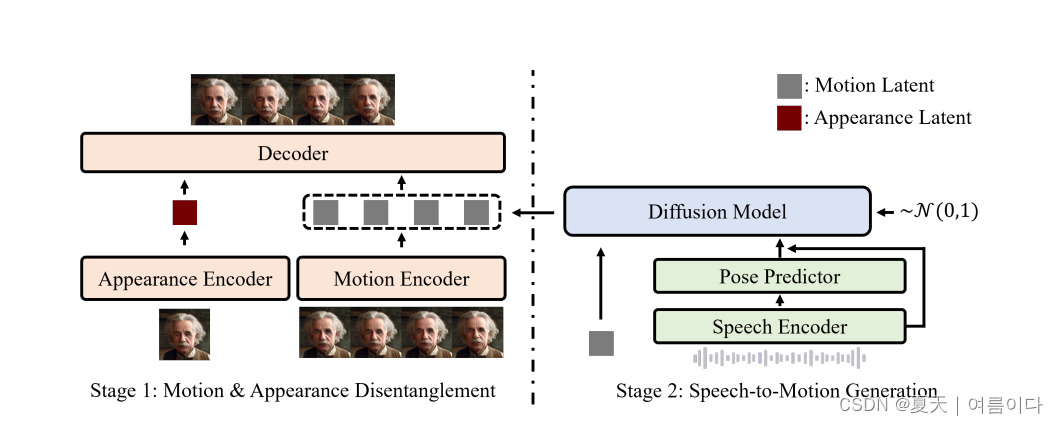
生成模型 | 数字人类的三维重建(3D reconstruction)调研及总结【20231210更新版】
本文主要集中于图片到三维重建的算法模型,其中包含人体重建,人脸重建等
1.三维人体重建
1.1.2015_SMPL: A Skinned Multi-Person Linear Model 论文地址:SMPL2015.pdf (mpg.de) 代码地址:CalciferZh/SMPL: NumPy, TensorFlow an…
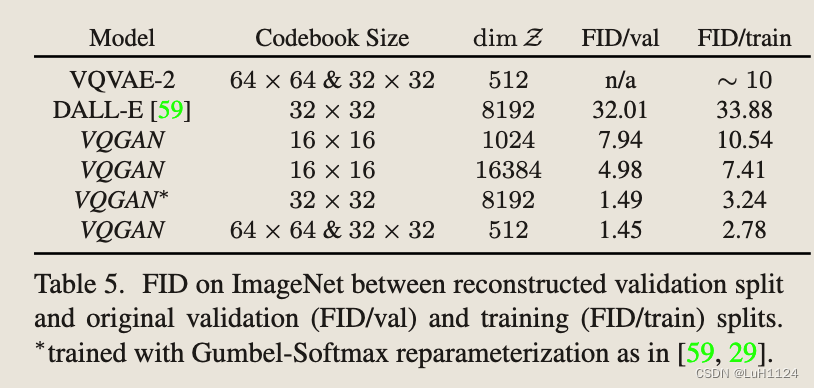
【论文阅读笔记】Taming Transformers for High-Resolution Image Synthesis
Taming Transformers for High-Resolution Image Synthesis 记录前置知识AbstractIntroductionRelated WorkMethodLearning an Effective Codebook of Image Constituents for Use in TransformersLearning the Composition of Images with Transformers条件合成合成高分辨率图…
controlnet前向代码解析
ControlNet|使用教程 各模型算法说明以及使用解析 - openAI本本介绍了如何在Stable Diffusion中使用ControlNet生成高质量图片的方法,包括骨骼提取、边缘线处理、引导设置、语义分割、涂鸦等功能的详细介绍,帮助用户快速上手使用ControlNet。…

AIGC系列之:Vision Transformer原理及论文解读
目录
相关资料
模型概述
Patch to Token
Embedding
Token Embedding
Position Embedding
ViT总结 相关资料
论文链接:https://arxiv.org/pdf/2010.11929.pdf
论文源码:https://github.com/google-research/vision_transformer
PyTorch实现代码…
跟李沐学AI-深度学习课程00-03【预告、课程安排、深度学习介绍、安装】
目录
00 预告
01 课程安排
02 深度学习介绍
03 安装
本地安装
04 数据操作数据预处理
数据操作
数据类型
创建数组
访问元素
数据操作实现
入门
运算符
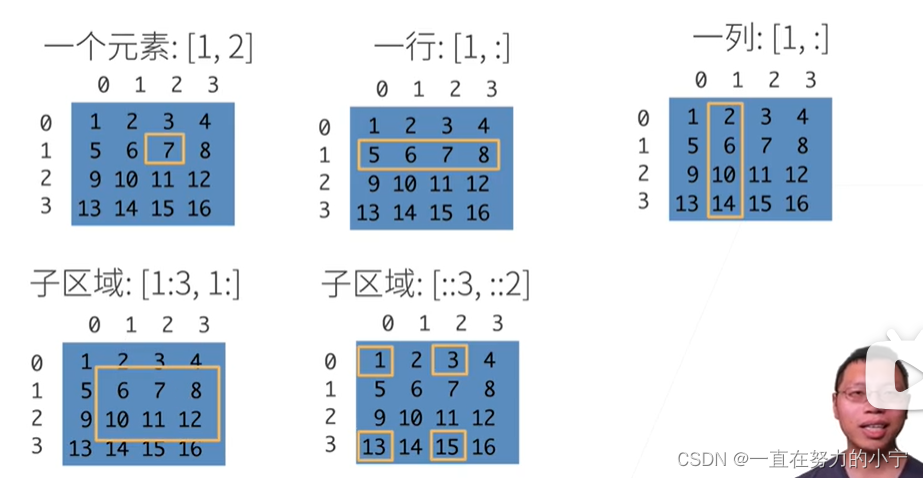
广播机制
索引和切片
节省内存
转换为其他Python对象
数据预处理实现
读取数据集
处理缺失值
转换为张…
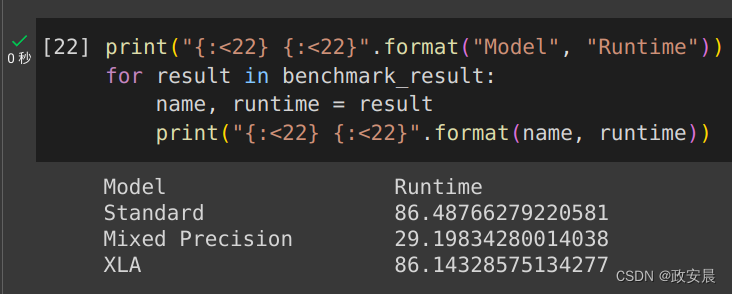
政安晨:演绎在KerasCV中使用Stable Diffusion进行高性能图像生成
小伙伴们好,咱们今天演绎一个使用KerasCV的StableDiffusion模型生成新的图像的示例。
考虑计算机性能的因素,这次咱们在Colab上进行,Colab您可以理解为在线版的Jupyter Notebook,还不熟悉Jupyter的的小伙伴可以去看一下我以前的文…
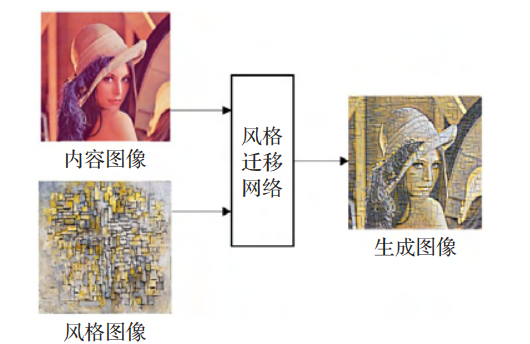
AI:136-基于深度学习的图像生成与风格迁移
🚀点击这里跳转到本专栏,可查阅专栏顶置最新的指南宝典~
🎉🎊🎉 你的技术旅程将在这里启航! 从基础到实践,深入学习。无论你是初学者还是经验丰富的老手,对于本专栏案例和项目实践都有参考学习意义。 ✨✨✨ 每一个案例都附带关键代码,详细讲解供大家学习,希望…
06.GPT-4+图像生成
文章目录 GPT-4摘要技术细节亮点:可识图亮点:性能好多样性少多语言处理能力强可解Inverse Scaling Prize任务Calibration很好输入图像的方式(猜测) 图像生成模型速览图像生成各个击破一次到位 常用的图像生成模型VAEFlow-based Ge…

Latent Diffusion(CVPR2022 oral)-论文阅读
文章目录摘要背景算法3.1. Perceptual Image Compression3.2. Latent Diffusion Models3.3. Conditioning Mechanisms实验4.1. On Perceptual Compression Tradeoffs4.2. Image Generation with Latent Diffusion4.3. Conditional Latent Diffusion4.4. Super-Resolution with …
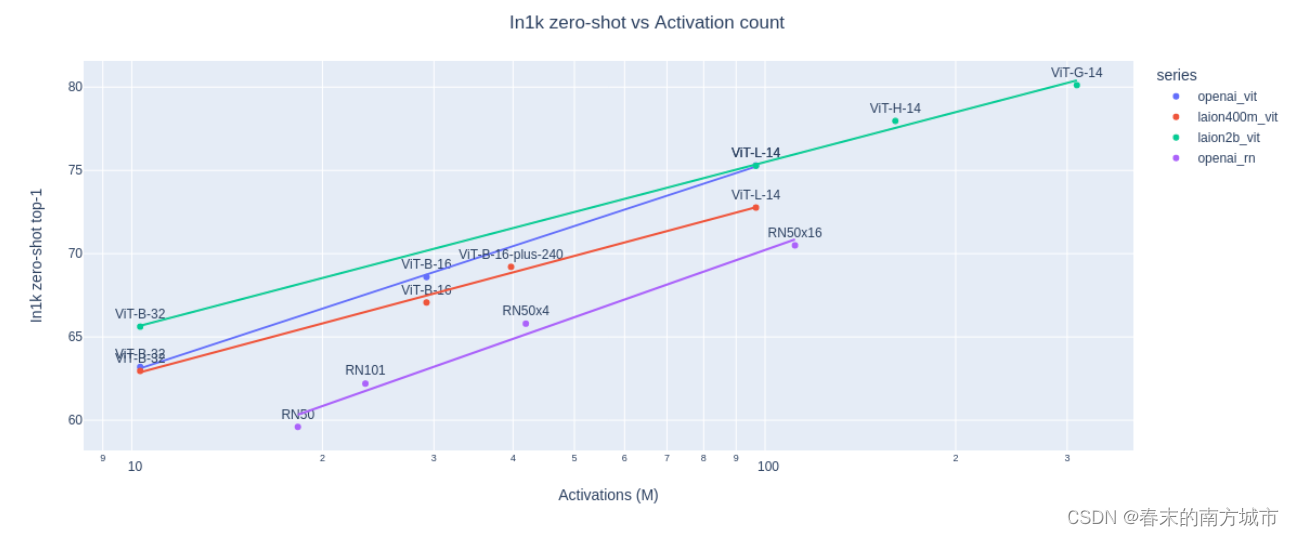
AIGC系列之:CLIP和OpenCLIP
目录
模型背景
CLIP模型介绍
相关资料
原理和方法
Image Encoder
Text Encoder
对比学习
预训练
Zero Shot预测
优势和劣势
总结
OpenClip模型介绍
相关资料
原理
结果
用法
模型总结 模型背景
Stable Diffusion主要由三个核心模块组成: Text Enc…
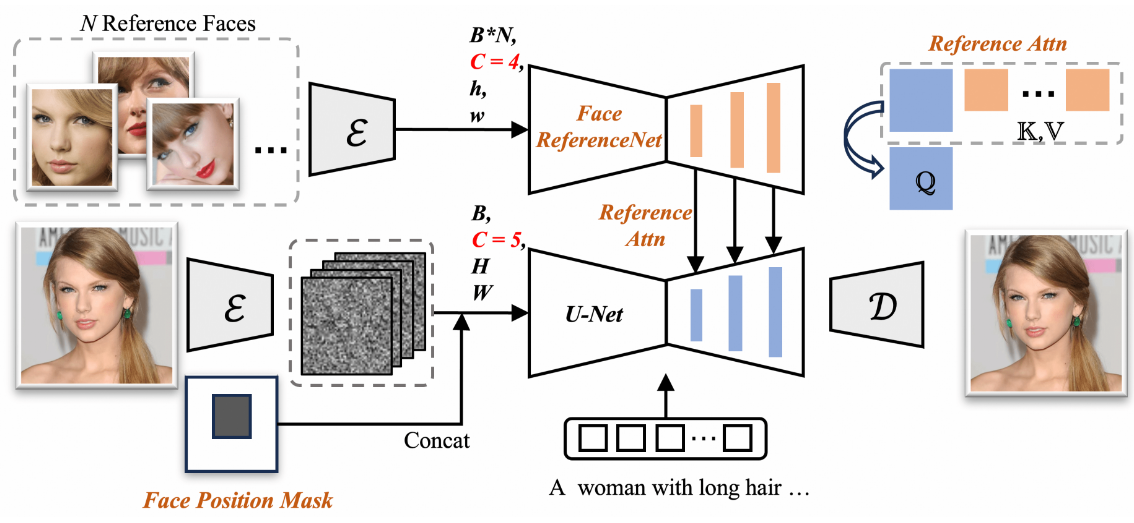
FlashFace:一种高保真身份保存的人类形象个性化方法
FlashFace技术是由香港大学、阿里巴巴集团、蚂蚁集团共同研发的一项实用工具,用户可以通过提供一张或几张参考面部图像和文本提示,就可以轻松地即时个性化自己的相片。
与现有的人像定制方法相比,FlashFace方法具有更高保真度的身份保留xi性…

AIGC系列之:Variational Auto Encoder-VAE模块
目录
1.VAE 概述
2.概率分布
3.损失函数
4.重参数技巧
5.维度对 VAE 的影响
6.损失函数对VAE的影响
7.总结 VAE原始https://arxiv.org/abs/1312.6114
论文解读:https://mp.weixin.qq.com/MzI1MjQ2O
1.VAE 概述 变分自动编码器(Variational auto…

08.Diffusion Model数学原理分析(下)
文章目录 denoising matching term σ t z \sigma_tz σtz的猜想Diffusion Model for SpeechDiffusion Model for TextMask-Predict 部分截图来自原课程视频《2023李宏毅最新生成式AI教程》,B站自行搜索。 书接上文。
denoising matching term E q ( x t ∣ x 0 …

【DDPM论文解读】Denoising Diffusion Probabilistic Models
0 摘要
本文使用扩散概率模型合成了高质量的图像结果,扩散概率模型是一类受非平衡热力学启发的潜变量模型。本文最佳结果是通过根据扩散概率模型和朗之万动力学的去噪分数匹配之间的新颖联系设计的加权变分界进行训练来获得的,并且本文的模型自然地承认…

InstantID: Zero-shot Identity-Preserving Generation in Seconds
文章目录 IntroductionMainReference 记录由国内首创的一个好玩的小项目,图像生成领域的新进展。但我希望现阶段计算机视觉领域的研究能更聚焦在 语义分割 和 三维视觉 上,这样能更方便与机器人等产品和工业实体结合。 Introduction
InstantID 是一个基…

【Image】GAN的超详细解释(以及奇怪的问题)
GAN原理
工作流程
下面是生成对抗网络(GAN)的基本工作原理 在GAN的架构中,有两个关键的组件:生成器(Generator)和鉴别器(Discriminator)。 生成器(Generator࿰…
Open AI 的 Sora 是什么?它是如何工作的?应用场景、风险、替代方案、未来意义等
Open AI 的 Sora 是什么?它是如何工作的?应用场景、风险、替代方案、未来意义等 探索 OpenAI 的 Sora:一种突破性的文本到视频 AI,将在 2024 年彻底改变多模态人工智能。探索其功能、创新和潜在影响。 OpenAI 最近宣布了其最新的突…

数字时代的自我呈现:探索个人形象打造的创新工具——FaceChain深度学习模型工具
数字时代的自我呈现:探索个人形象打造的创新工具——FaceChain深度学习模型工具
1.介绍
FaceChain是一个可以用来打造个人数字形象的深度学习模型工具。用户仅需要提供最低一张照片即可获得独属于自己的个人形象数字替身。FaceChain支持在gradio的界面中使用模型训…

图像生成模型【自编码器、RNN、VAE、GAN、Diffusion、AIGC等】
目录
监督学习 与 无监督学习
生成模型
自编码器
从线性维度压缩角度: 2D->1D
线性维度压缩: 3D->2D
推广线性维度压缩
流形
自编码器:流形数据的维度压缩
全图像空间
自然图像流形
自编码器的去噪效果
自编码器的问题
图像预测 (“结构化预测”…
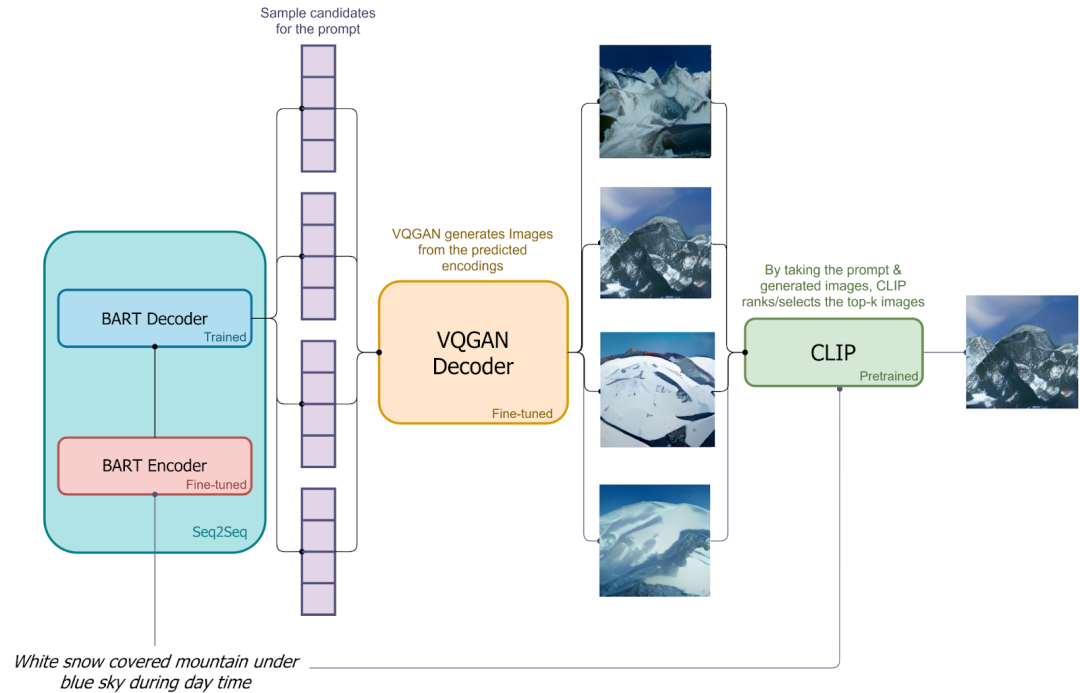
文生图:AE/VAE/VQVAE/VQGAN/DALLE模型
文生图模型演进:AE、VAE、VQ-VAE、VQ-GAN、DALL-E 等 8 模型本文中我们回顾了 AE、VAE、VQ-VAE、VQ-VAE-2 以及 VQ-GAN、DALL-E、DALL-E mini 和 CLIP-VQ-GAN 等 8 中模型,以介绍文生图模型的演进。https://mp.weixin.qq.com/s/iFrCEpAJ3WMhB-01lZ_qIA 1…
styleGAN记录
前言
最近需要看一些gan相关的工作,所以写个博客记录一下开个坑。
由于也不知道啥时候能写完,这里看到一篇写的还可以的博文,着急的朋友可以移步 从零带你入门stylegan~stylegan3的技术细节 styleGAN v1 styleGAN v2
styleGANv2-tiny 实践…

图像生成论文阅读:Latent Diffusion算法笔记
标题:High-Resolution Image Synthesis with Latent Diffusion Models 会议:CVPR2022 论文地址:https://ieeexplore.ieee.org/document/9878449/ 官方代码:https://github.com/CompVis/latent-diffusion 作者单位:慕尼…
图像生成简单介绍并给出相应的示例代码
文章目录 图像生成简单介绍并给出相应的TensorFlow示例代码1. 介绍2. 准备工具和库3. 数据集准备4. 创建生成对抗网络(GAN)模型5. 训练模型6. 生成新图像7. 总结 图像生成简单介绍并给出相应的TensorFlow示例代码
图像生成是计算机视觉中的一个重要任务…

Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks 论文阅读笔记
Paper: Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks
Author: Alec Radford, et al。
Publication: arXiv, 2015。文章目录1 背景2 创新点3 核心方法3.1 为稳定DCGAN的训练作出的选择3.2 实验经验的参数选择3.3 数据集的选…