c语言
导航
论文阅读
IMX6ULL
shell
青少年编程
电气
插件的定义和使用
民商法
kafka
镜像复制
iVX低代码平台
训练数据
网页设计与制作
fastapi
TestStand
shellcode
.Net6
go mod init
替换-删除-格式化
Diffusion
2024/4/12 16:27:33
大模型之SORA技术学习
文章目录 sora的技术原理文字生成视频过程sora的技术优势量大质优的视频预训练库算力多,采样步骤多,更精细。GPT解释力更强,提示词(Prompt)表现更好 使用场景参考 Sora改变AI认知方式,开启走向【世界模拟器】的史诗级的…
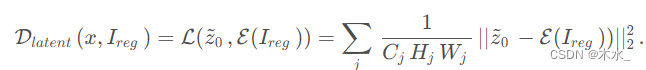
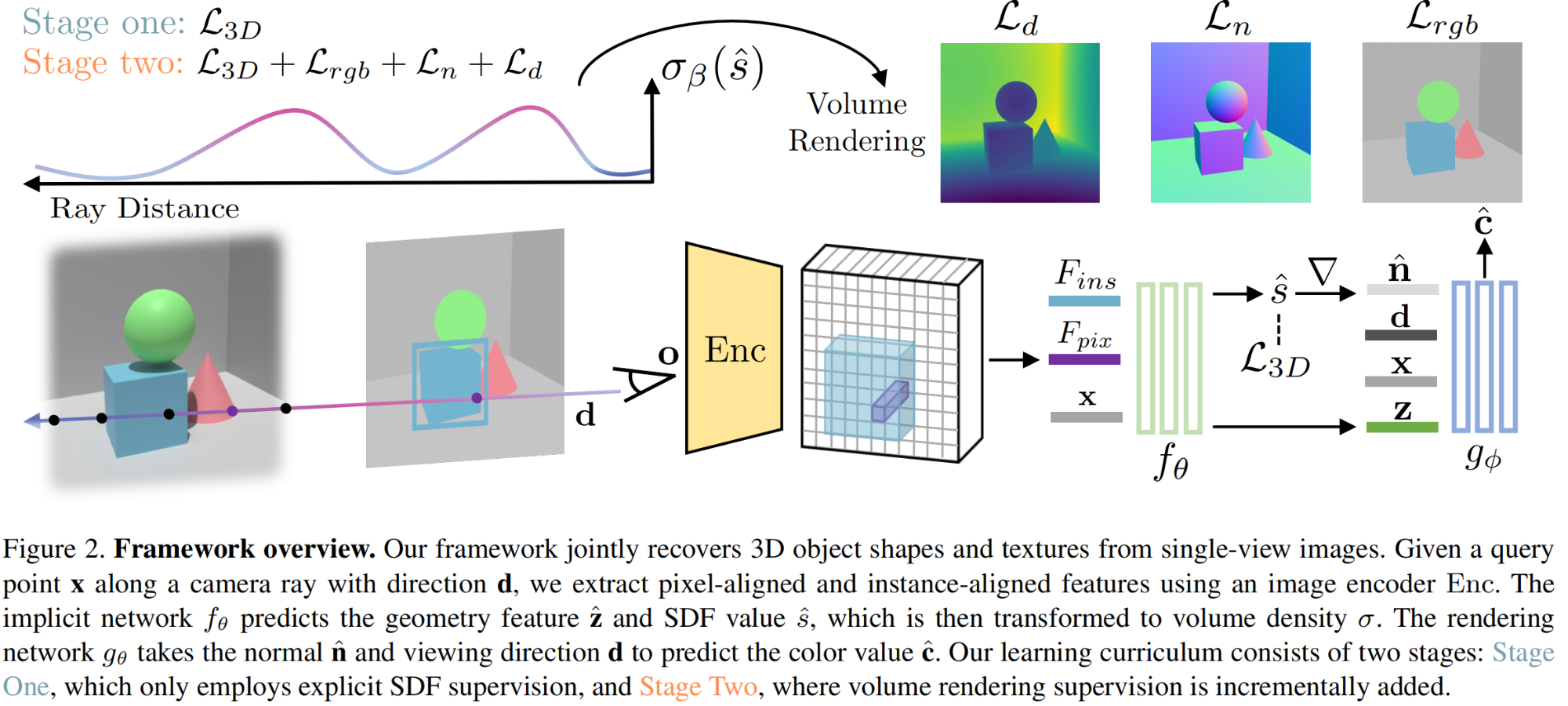
读论文:DiffBIR: Towards Blind Image Restoration with Generative Diffusion Prior
DiffBIR 发表于2023年的ICCV,是一种基于生成扩散先验的盲图像恢复模型。它通过两个阶段的处理来去除图像的退化,并细化图像的细节。DiffBIR 的优势在于提供高质量的图像恢复结果,并且具有灵活的参数设置,可以在保真度和质量之间进…
CV计算机视觉每日开源代码Paper with code速览-2023.11.2
精华置顶 墙裂推荐!小白如何1个月系统学习CV核心知识:链接 点击CV计算机视觉,关注更多CV干货
论文已打包,点击进入—>下载界面
点击加入—>CV计算机视觉交流群
1.【目标检测】Re-Scoring Using Image-Language Similarit…

如何在手机端部署大型扩散模型?
Diffusion Models专栏文章汇总:入门与实战 前言:部署扩散模型面临着两个棘手的挑战:参数过大和推理时间过长,因此目前想在手机端用上扩散模型看似“奢不可求”。最近谷歌研究院的最新一项研究研究了如何把端侧部署大型扩散模型的梦想变成现实,这篇博客就和大家一起学习一下…
本地用AIGC生成图像与视频
最近AI界最火的话题,当属Sora了。遗憾的是,Sora目前还没开源或提供模型下载,所以没法在本地跑起来。但是,业界有一些开源的图像与视频生成模型。虽然效果上还没那么惊艳,但还是值得我们体验与学习下的。
Stable Diffu…

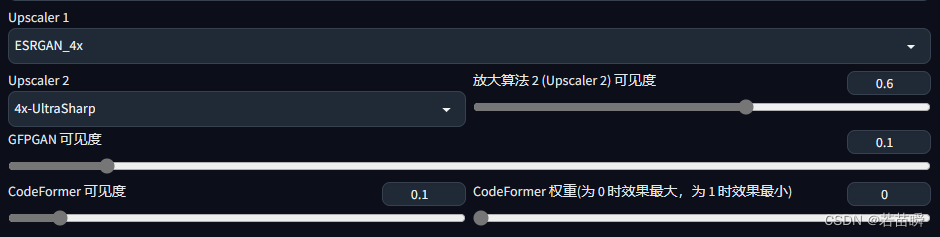
关于【SD-WEBUI】的LoRA模型训练:怎样才算训练好了?
文章目录 (零)前言(一)模型(LoRA)训练(1.1)数据准备(1.1.1)筛选照片(1.1.2)预处理照片(1.1.3)提示词(tags)处理(1.1.4&…

【SVD生成视频+可本地部署】ComfyUI使用(二)——使用Stable Video Diffusion生成视频 (2023.11开源)
SVD官方主页 : Huggingface | | Stability.ai || 论文地址 huggingface在线运行demo : https://huggingface.co/spaces/multimodalart/stable-video-diffusion SVD开源代码:Github(含其他项目) || Huggingface 在Comfyui使用&…
继续Stable-Diffusion WEBUI方方面面研究(内容索引)
文章目录(零)前言(一)绘图(1.1)模型(1.1.1)基础模型(Stable-diffusion模型)(1.1.2)人物模型(LoRA模型)&#x…

Diffusion:通过扩散和逆扩散过程生成图像的生成式模型
在当今人工智能大火的时代,AIGC 可以帮助用户完成各种任务。作为 AIGC 主流模型的 DDPM,也时常在各种论文中被提起。DDPM 本质就是一种扩散模型,可以用来生成图片或者为图片去噪。
扩散模型定义了一个扩散的马尔科夫过程,每一步逐…

深入浅出 diffusion(2):pytorch 实现 diffusion 加噪过程
我在上篇博客深入浅出 diffusion(1):白话 diffusion 原理(无公式)中介绍了 diffusion 的一些基本原理,其中谈到了 diffusion 的加噪过程,本文用pytorch 实现下到底是怎么加噪的。
import torch…

【AI视野·今日CV 计算机视觉论文速览 第262期】Fri, 6 Oct 2023
AI视野今日CS.CV 计算机视觉论文速览 Fri, 6 Oct 2023 Totally 73 papers 👉上期速览✈更多精彩请移步主页 Daily Computer Vision Papers
Improved Baselines with Visual Instruction Tuning Authors Haotian Liu, Chunyuan Li, Yuheng Li, Yong Jae Lee大型多模…
diffusion 和 gan 的优缺点对比
sample速度GAN更快,Diffusion需要迭代更多次。 训练难度GAN 的训练可能是不稳定的,容易出现模式崩溃和训练振荡等问题。Diffusion 训练loss收敛性好,比较平稳。 模拟分布连续性Diffusion相较于GAN可以模拟更加复杂,更加非线性的分…
深入浅出 diffusion(3):pytorch 实现 diffusion 中的 U-Net
导入python包
import mathimport torch
import torch.nn as nn
import torch.nn.functional as F silu激活函数
class SiLU(nn.Module): # SiLU激活函数staticmethoddef forward(x):return x * torch.sigmoid(x)
归一化设置
def get_norm(norm, num_channels, num_groups)…

Stable diffusion 简介
Stable diffusion 是 CompVis、Stability AI、LAION、Runway 等公司研发的一个文生图模型,将 AI 图像生成提高到了全新高度,其效果和影响不亚于 Open AI 发布 ChatGPT。Stable diffusion 没有单独发布论文,而是基于 CVPR 2022 Oral —— 潜扩…
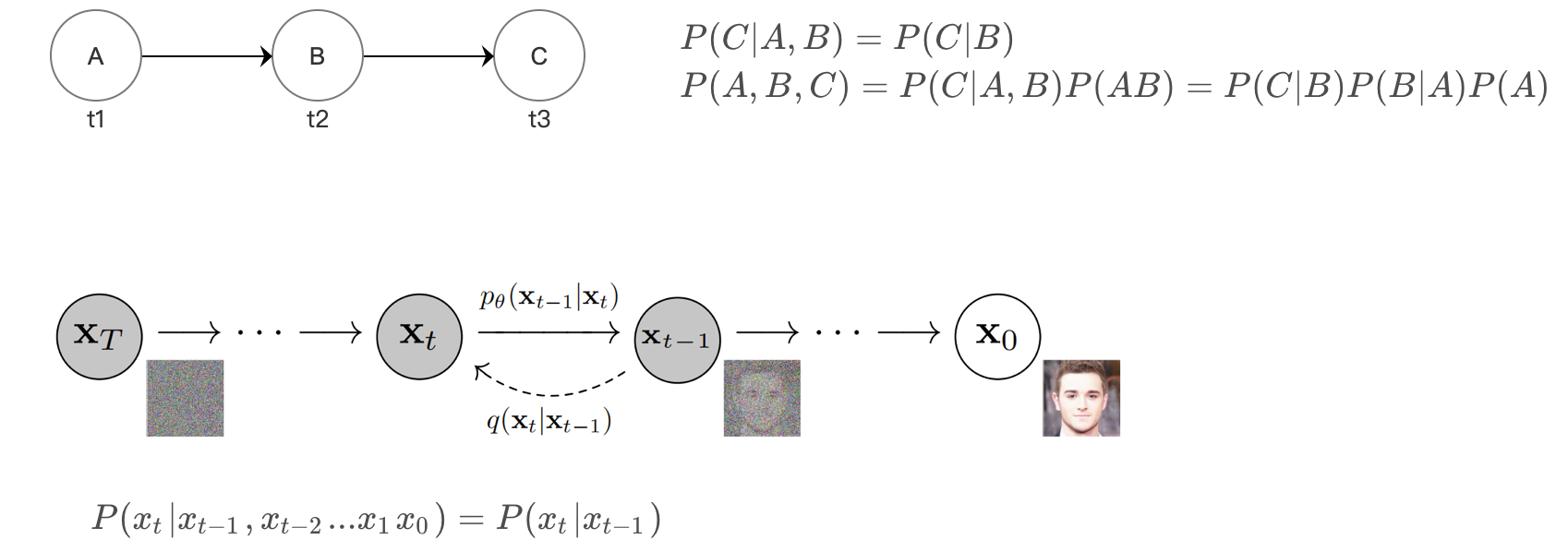
【Diffusion】DDPM - (1)预备基础知识
预备基础知识
1、概率 - 条件独立
A 和 B 是两个独立事件 ⇒ P ( A ∣ B ) = P ( A ) \; \Rightarrow \; P(A|B) = P(A) ⇒P(A∣B)=P(A), P ( B ∣ A ) = P ( B ) \quad P(B|A) = P(B) P(B∣A)=P(B) ⇒ P ( A , B ∣ C ) = P ( A ∣ C ) P ( B ∣ C ) \quad\quad…

Vox-E: Text-guided Voxel Editing of 3D Objects(3D目标的文本引导体素编辑)
Vox-E: Text-guided Voxel Editing of 3D Objects (3D目标的文本引导体素编辑) Paper:https://readpaper.com/paper/1705264952657440000
Code:http://vox-e.github.io/
原文链接:Vox-E: 3D目标的文本引导体素编辑 &…
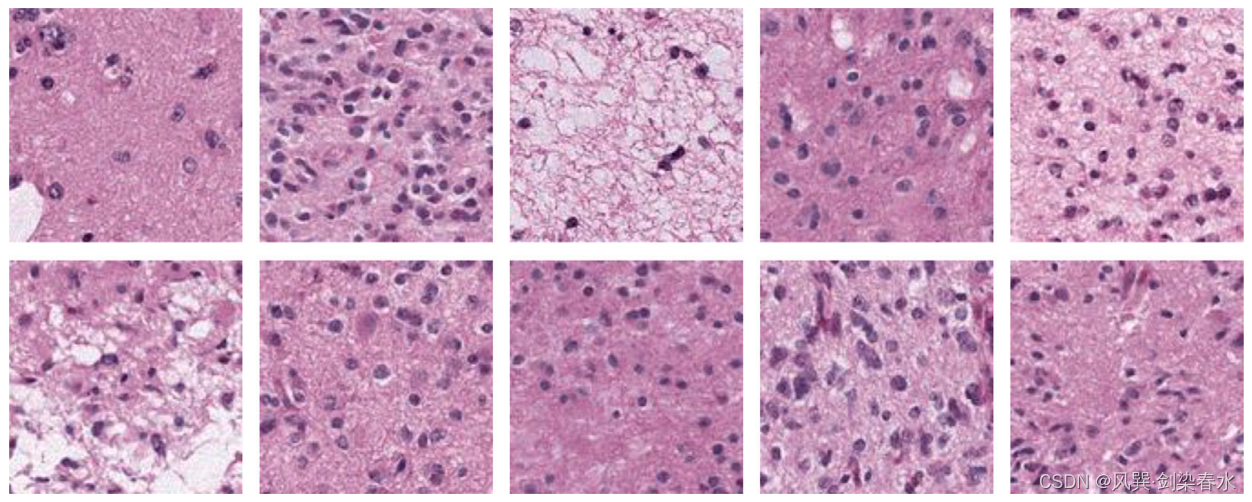
【Diffusion综述】医学图像分析中的扩散模型(一)
这两天了解了一下扩散模型,想知道在医学影像中,扩散模型有哪些用途,翻译记录一篇扩散模型的综述。 原文传递:Diffusion Models for Medical Image Analysis: A Comprehensive Survey 其他综述篇: 【SAM综述】医学图…

深入浅出 diffusion(4):pytorch 实现简单 diffusion
1. 训练和采样流程 2. 无条件实现
import torch, time, os
import numpy as np
import torch.nn as nn
import torch.optim as optim
from torchvision.datasets import MNIST
from torchvision import transforms
from torch.utils.data import DataLoader
from torchvision.…
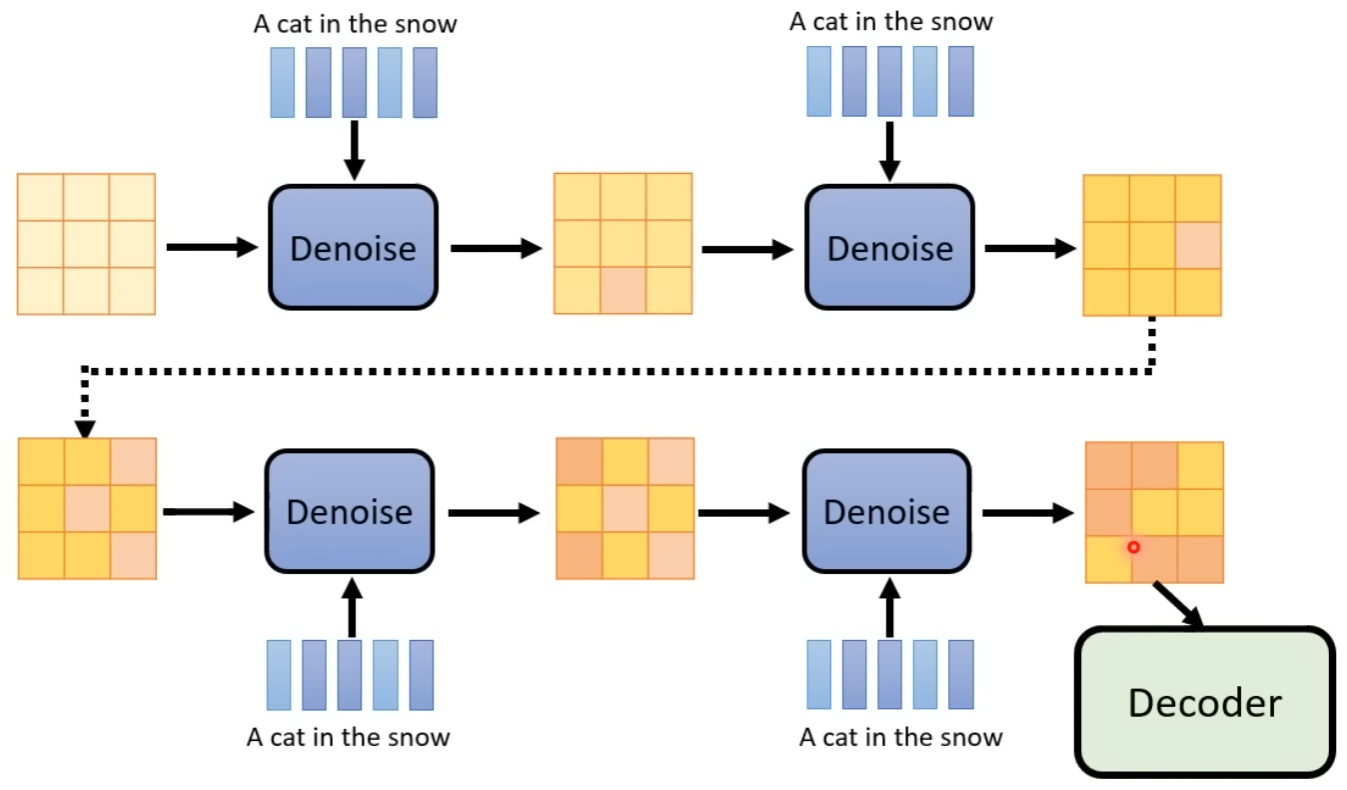
生成式 AI 背后的共同框架:Stable Diffusion、DALL-E、Imagen
前言
如果你对这篇文章感兴趣,可以点击「【访客必读 - 指引页】一文囊括主页内所有高质量博客」,查看完整博客分类与对应链接。 框架
这些生成式 AI 的整体功能为:输入「文字」,返回「图像」,即 Text-to-image Gener…

在Kaggle上使用Stable Diffusion进行AI绘图
前言
因为使用Stable Diffusion进行AI绘图需要GPU,这让其应用得到了限制本文介绍如何在Kaggle中部署Stable Diffusion,并使用免费的P100 GPU进行推理(每周可免费使用30小时),部署好后可以在任意移动端使用。本项目在s…
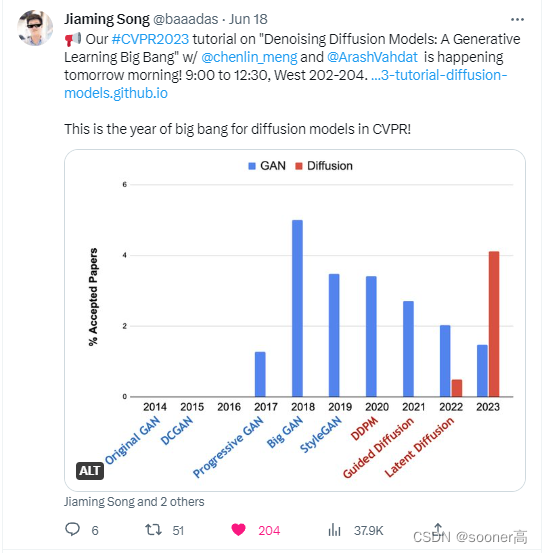
【Diffusion模型系列1】DDPM: Denoising Diffusion Probabilistic Models
0. 楔子
Diffusion Models(扩散模型)是在过去几年最受关注的生成模型。2020年后,几篇开创性论文就向世界展示了扩散模型的能力和强大:
Diffusion Models Beat GANs on Image Synthesis(NeurIPS 2021 Spotlight, OpenAI团队, 该团队也是DALLE-2的作者)[1] Various…
Text2Video-Zero:Text-to-Image扩散模型是Zero-Shot视频生成器
Text2Video-Zero: Text-to-Image Diffusion Models are Zero-Shot Video Generators Paper: https://arxiv.org/abs/2303.13439 Project: https://github.com/Picsart-AI-Research/Text2Video-Zero 原文链接:Text2Video-Zero:Text-to-Image扩散模型是Zero-Shot视频…
![[PMLR 2021] Zero-Shot Text-to-Image Generation:零样本文本到图像生成](https://img-blog.csdnimg.cn/img_convert/eae8c832d9fd3e9b696a3f02bb50b96a.png)
[PMLR 2021] Zero-Shot Text-to-Image Generation:零样本文本到图像生成
[PMLR 2021]Zero-Shot Text-to-Image Generation:零样本文本到图像生成 Fig 1. 原始图像(上)和离散VAE重建图像(下)的比较。编码器对空间分辨率进行8倍的下采样。虽然细节(例如,猫毛的纹理、店面上的文字和插图中的细线)有时会丢失或扭曲,但图…

CVPR 2023 | 用户可控的条件图像到视频生成方法(基于Diffusion)
注1:本文系“计算机视觉/三维重建论文速递”系列之一,致力于简洁清晰完整地介绍、解读计算机视觉,特别是三维重建领域最新的顶会/顶刊论文(包括但不限于 Nature/Science及其子刊; CVPR, ICCV, ECCV, NeurIPS, ICLR, ICML, TPAMI, IJCV 等)。 本次介绍的论…
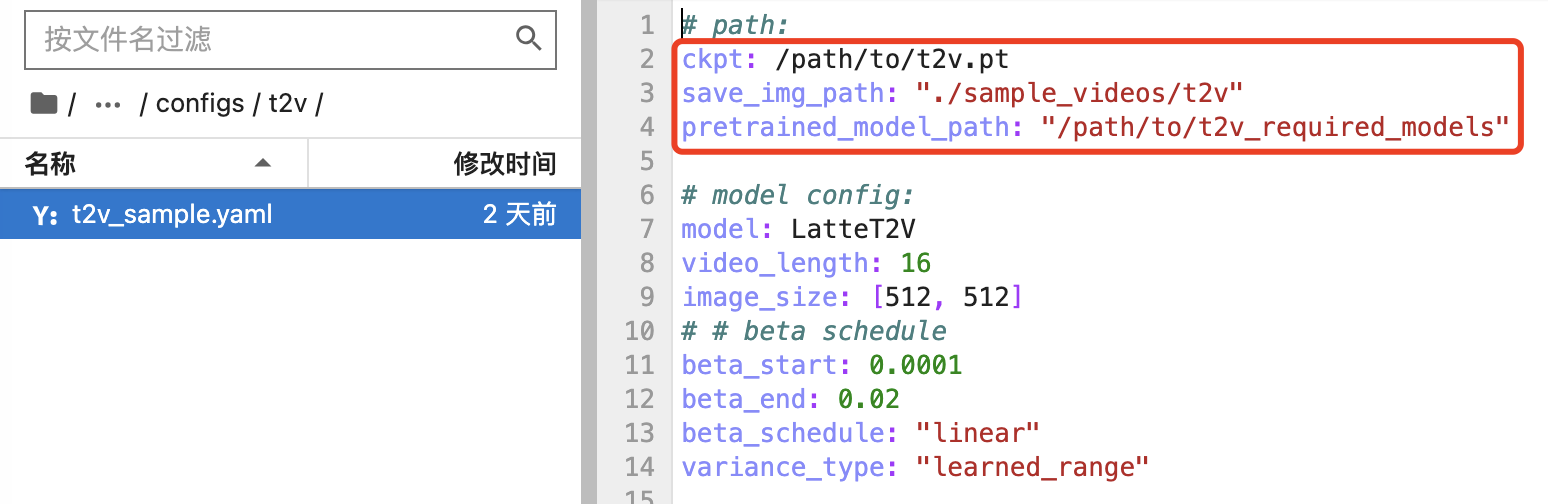
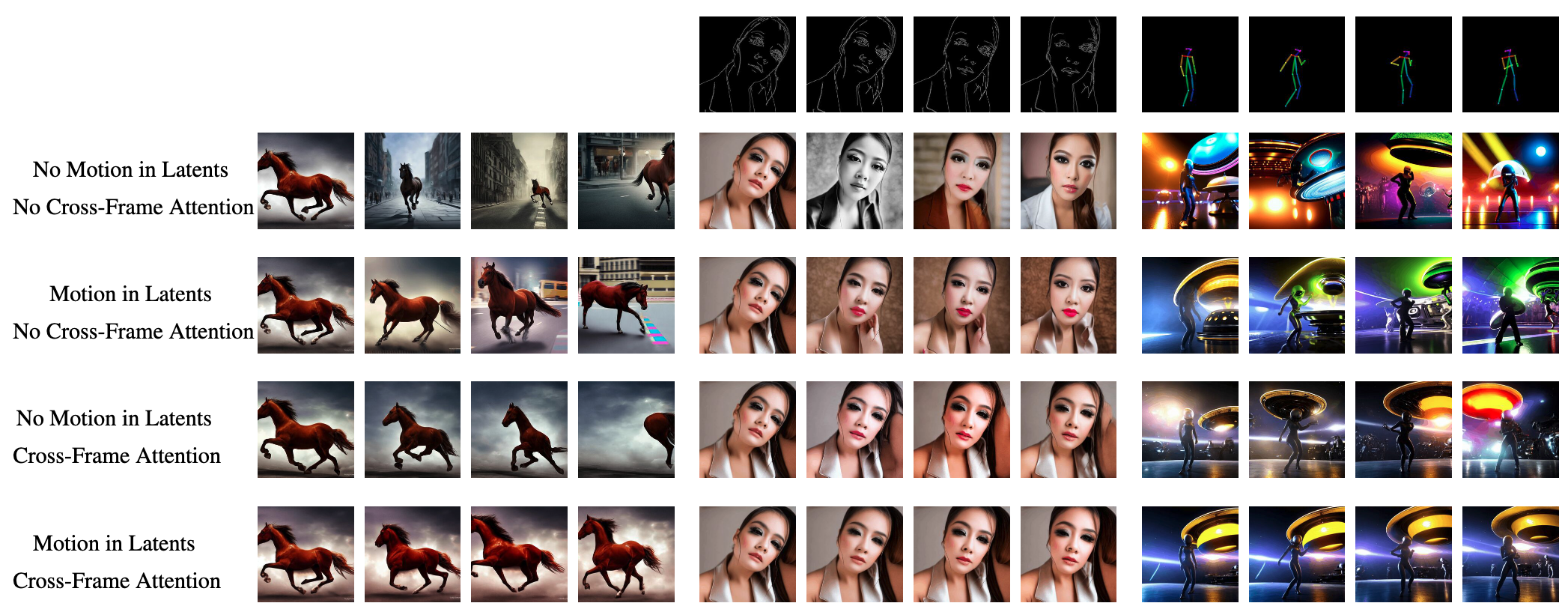
Latte:一个类似Sora的开源视频生成项目
前段时间OpenAI发布的Sora引起了巨大的轰动,最长可达1分钟的高清连贯视频生成能力秒杀了一众视频生成玩家。因为Sora没有公开发布,网上对Sora的解读翻来覆去就那么多,我也不想像复读机一样再重复一遍了。
本文给大家介绍一个类似Sora的视频生…
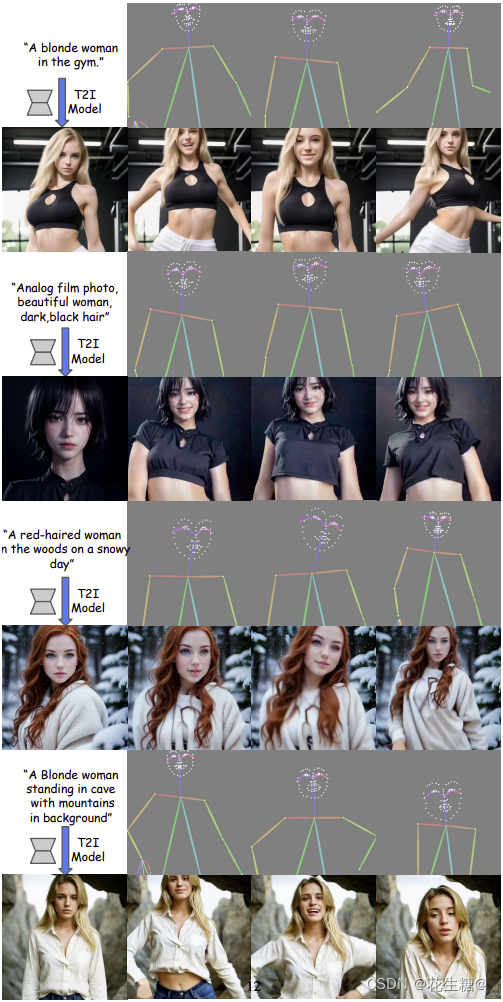
OpenAI Sora引领AI跳舞视频新浪潮:字节跳动发布创新舞蹈视频生成框架
OpenAI的Sora已经引起广泛关注,预计今年AI跳舞视频将在抖音平台上大放异彩。下面将为您详细介绍一款字节跳动发布的AI视频动画框架。
技术定位:这款框架采用先进的diffusion技术,专注于生成人类舞蹈视频。它不仅能够实现人体动作和表情的迁移…


InstructDiffusion-多种视觉任务统一框架
论文:《InstructDiffusion: A Generalist Modeling Interface for Vision Tasks》 github:https://github.com/cientgu/InstructDiffusion InstructPix2Pix:参考 文章目录 摘要引言算法视觉任务统一引导训练集重构统一框架 实验训练集关键点检测分割图像…