CMake
网络图
项目管理
layui
漏洞
毛球修剪器方案
springmvc
相机参数
标准库与HAL库实现
人手检测
产品经理常犯的错误
四大分析工具
征信报告
端口转发
Revit二次开发
网页设计与制作
仿抖音APP
torch
dalvik
开发
DataFrame
2024/4/12 20:48:11
2.pandas统计分析基础(读取数据、dataframe、索引)
笔记说明:本文是我的学习笔记,大部分内容整理自 黄红梅,张良均等.Python数据分析与应用[M].北京:人民邮电出版社,2018,80-130. 还有部分片断知识来自网络搜索补充。
推荐 这个博客帖子https://blog.csdn.net/hhtnan/article/details/80080240 文章目录1…
【Spark SQL】5、DataFrameDataSet的简单使用
DataFrame与RDD的互操作
/*** DataFrame和RDD的互操作*/
object DataFrameRDDApp {def main(args: Array[String]) {val spark SparkSession.builder().appName("DataFrameRDDApp").master("local[2]").getOrCreate()//inferReflection(spark)program(sp…
df寻找nan空值TypeError: ufunc 'isnan' not supported for the input types,...错误解决方案
不要用numpy 的 isnan 用pd.isna
index df[A].index[pd.isna(df[A])]
即可找出index
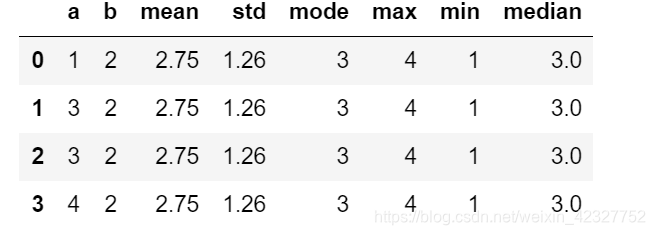
python dataframe列计算众数、中位数、平均值、极值、标准差等统计量
b pd.DataFrame({a:[1,3,3,4],b:[2,2,2,2]})
a pd.DataFrame()# 分别计算均值,标准差、众数、最值、中位数
a[mean][b[a].mean() for i in range(len(b)) ]
a[std][round(b[a].std(),2) for i in range(len(b)) ]
a[mode] [b[a].mode()[0] for i in range(len(b…
保存带 numpy.ndarray 的 dataframe
# 创建 DataFrame
texts ["hi", "hello", "you"]
embeddings [np.random.randn(10,) for i in range(3)]
df pd.DataFrame({"text":texts, "embedding":embeddings})type(df.embedding.values[0]) # numpy.ndarray# 保存…

Spark - RDD / ROW / sql.DataFrame 互转
一.引言 SparkSql 相比较 HiveSql 具有更快的运行速度和更高的灵活性,平常使用中经常需要进行数据转换,常见的有 RDD[T] -> DataFrame,DataFrame -> RDD[T] 还有 RDD[row] -> sql.dataFrame,下面简单介绍下常用用法。
初…
Gradio Dataframe 学习笔记
Gradio Dataframe 学习笔记 0. 简介1. 使用场景2. 测试数据3. 学习代码4. 更多功能5. 学习资源6. 总结 0. 简介
Gradio是一个用于构建交互式机器学习界面的Python库。它可以轻松创建各种类型的界面,包括用于数据可视化和探索的界面。
Gradio Dataframe 组件是 Gra…
Python学习笔记(7):数据框
前一篇文章提到了序列,可以理解为Excel里没有列名的一列数据,那么Excel里的由行列组成的表数据是如何对应到Python中的呢?就是今天要说的数据框:DataFrame。
它是由一组数据和一对索引(行索引和列索引)组成的二维数据结构&#x…
Pandas 数据清洗和处理
Pandas 数据清洗和处理 文章目录Pandas 数据清洗和处理1 DataFrame 选取奇\偶行1 DataFrame 选取奇\偶行
生成数据:
import pandas as pd
import numpy as np
np.random.seed(1071)
df pd.DataFrame(np.random.randint(1, 30, (7, 2)), columnslist(AB), indexra…
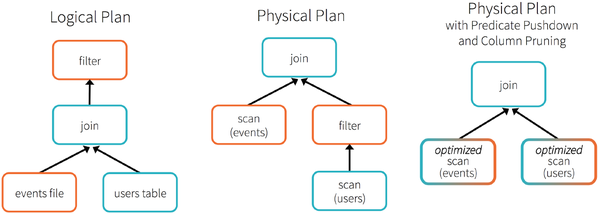
RDD 、 DataFrame 和 DataSet 详解
RDD、DataFrame和DataSet的区别 RDD、DataFrame和DataSet是容易产生混淆的概念,必须对其相互之间对比,才可以知道其中异同。 RDD和DataFrame RDD-DataFrame上图直观地体现了DataFrame和RDD的区别。左侧的RDD[Person]虽然以Person为类型参数,但…
Spark将DataFrame写入MySQL时遇到的问题
DataFrame如何写入MySQL
val host "localhost"
val port "3306"
val user "user"
val password "password"
val database "test"
val table "test"
val saveMode SaveMode.Overwrite // 支持4中写入方式…
【Spark SQL】6、常用API的学习
所有功能的入口点都是SparkSession类。要创建基本的SparkSession,只需使用SparkSession.builder()
import org.apache.spark.sql.SparkSessionval spark SparkSession.builder().appName("Spark SQL basic example").config("spark.some.config.op…
Dataframe学习笔记:记录一下工作上使用的几种示例
Dataframe学习笔记:记录一下工作上使用的几种示例 0. 引言1. Dataframe 简介2. Dataframe 使用场景3. 创建测试数据4. 示例学习5. 总结 0. 引言
最近工作上开发 AI 应用,经常使用到 Dataframe,所以整理和记录一下工作上使用的几种示例。
1.…
Python Pandas处理csv文件常用操作代码
常识
使用pandas.read_csv从csv文件中读取数据,对于csv中缺失的空值,读进dataframe会自动补为numpy.nan,且数据类型为float 操作
读取csv文件,存储为dataframe数据类型
df pandas.read_csv(csv_path)查看csv文件的dataframe的…
Python访问ElasticSearch
ElasticSearch是广受欢迎的NoSQL数据库,其分布式架构提供了极佳的数据空间的水平扩展能力,同时保障了数据的可靠性;反向索引技术使得数据检索和查询速度非常快。更多功能参见官网介绍 https://www.elastic.co/cn/elasticsearch/ 下面简单罗列…

Python Pandas DataFrame:筛选和删除含特定值的行与列
Python Pandas DataFrame:挑选和删除含特定值的行与列 🌈 个人主页:高斯小哥 🔥 高质量专栏:Matplotlib之旅:零基础精通数据可视化、Python基础【高质量合集】、PyTorch零基础入门教程 👈 希望得…

pandas中的Series和DataFrame的区别与转化
1.series数据类型
1. Series相当于数组numpy.array类似
Series 它是有索引,如果我们未指定索引,则是以数字自动生成。
objSeries([4,7,-5,3])print obj
#输出结果如下:
0 4
1 7
2 -5
3 3如果数据被存在一个python字典中&#x…
Python DataFrame 操作笔记
Python 中的pandas库是一个好用的数据处理库。使用最多的是DataFrame这个数据结构。
新建空DataFrame:
lsit[]
datapd.DataFrame(list)
新建指定列名的DataFrame:
datapd.DataFrame({"name":"","age":"",&q…
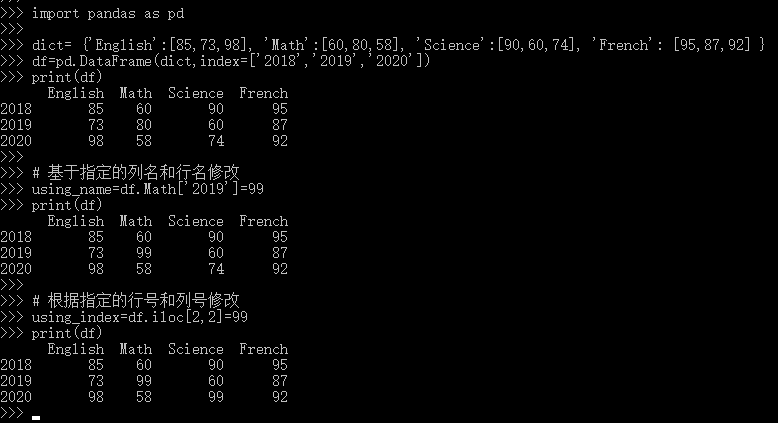
pandas修改DataFrame行/列/字段值
增加/修改一列 有如下几种方法增加一列:
增加具有相同值的一列
import pandas as pd dict {English:[85,73,98], Math:[60,80,58], Science:[90,60,74], French: [95,87,92] } dfpd.DataFrame(dict,index[2018,2019,2020])
print(df)
print(\n) …
数据分析-Pandas如何选择数据子集
数据分析-Pandas如何选择数据子集
Dataframe的数据中,选择某一列,某一行,或者某个子区域,该怎么办呢?
python数据分析-数据表读写到pandas
经典算法-遗传算法的python实现
经典算法-遗传算法的一个简单例子
大模型…
Spark SQL, DataFrames and Datasets指南
spark 2.4.4
Spark SQL是用于处理结构化数据的Spark模块。不同于基本的Spark RDD API,Spark SQL提供的接口为Spark提供了关于数据和正在执行的计算更多的信息。Spark SQL可以利用这些额外的信息在内部执行额外的优化。与Spark SQL交互的方式有多种例如SQL和Dataset API。无论…

尚硅谷大数据技术Spark教程-笔记08【SparkSQL(介绍、特点、数据模型、核心编程、案例实操、总结)】
尚硅谷大数据技术-教程-学习路线-笔记汇总表【课程资料下载】视频地址:尚硅谷大数据Spark教程从入门到精通_哔哩哔哩_bilibili 尚硅谷大数据技术Spark教程-笔记01【SparkCore(概述、快速上手、运行环境、运行架构)】尚硅谷大数据技术Spark教程…

SparkSQL基础解析(三)
1、 Spark SQL概述
1.1什么是Spark SQL
Spark SQL是Spark用来处理结构化数据的一个模块,它提供了2个编程抽象:DataFrame和 DataSet,并且作为分布式SQL查询引擎的作用。 我们已经学习了Hive,它是将Hive SQL转换成MapReduce然后提…
DataFrame入门
文章目录 1. 数据集合加载2. 使用常用的属性/方法查看数据情况type()shapecolumnsdtypesinfo() 3. 查看部分数据获取一列数据获取多列数据按行加载数据同时取出行列数据切片语法 4. 简单数据分析5. 数据可视化总结 1. 数据集合加载
pd.read_csv()方法不仅可以加载CSV文件&…
python的dataframe转换为多维矩阵
python的dataframe转换为多维矩阵有两种方法:
一种利用as_matrix()属性一种利用values
import pandas as pd import numpy as np df pd.DataFrame(np.random.rand(3,4),columnslist(abcd),indexlist(ABC)) print(df) print(values) print(df.values) pr…
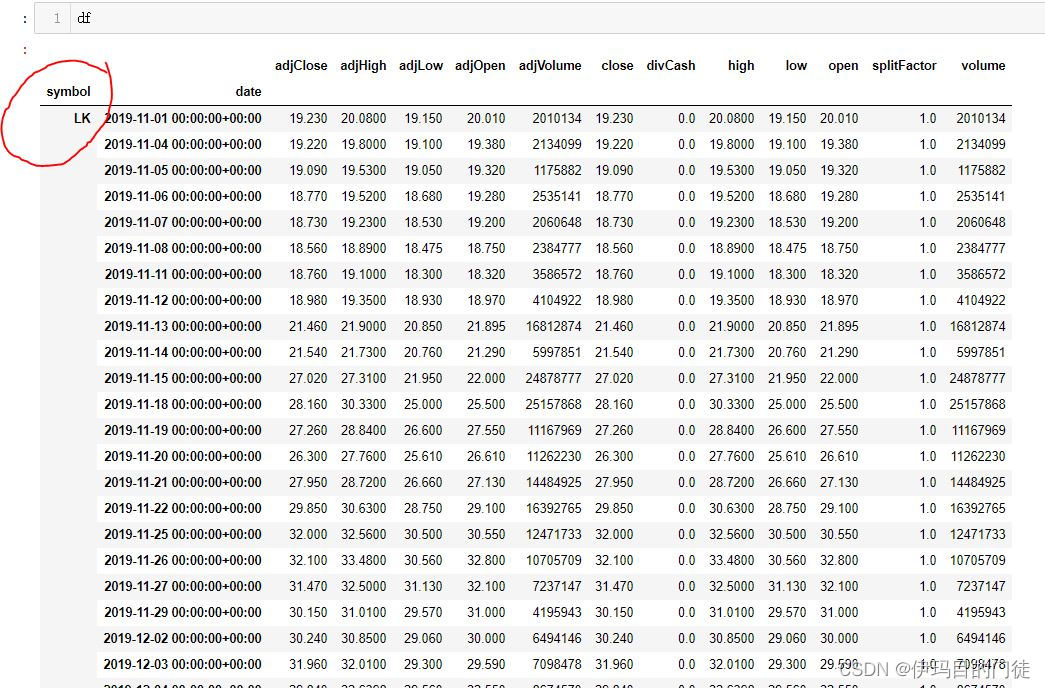
Pandas DataFrame的多重索引 MultiIndex 切片取单个df
#轴向转化函数 解决分组索引问题df1df.stack(0)
df1df1[LK].unstack()
找了好久的资料,也没有发现相关办法,我想要从一个多重索引下取到需要单独的小dataframe。就用这个土办法可以实现。
我大概浪费了一个半小时在这上面,希望把知识传递在…
python dataframe
dataframe为pandas中的数据格式,通常用来存储时间序列数据,比如K线数据,这在量化分析时通常用到。
1、创建dataframe
import pandas as pd
df0 pd.DataFrame([[1,2,3,4],[5,6,7,8]], columns[a, b, c, d])
2、读取csv文件为dataframe格式…
Python常用Dataframe语句
删除列S# 方法1
df df.drop(S, axis1)
# 方法2
df.drop(S, axis1, inplaceTrue)删除列K中包含字符a的行df df[~df[K].str.contains(a)]删除列S中值不为1的行df df[df[S] ! 1]删除列S中值不为1,2,3的行df df[(df[S] ! 1) & (df[S] ! 2) & (df…
Pandas学习笔记 Series DataFrame
Series
import numpy as np
import pandas as pd
import sys
from pandas import Series,DataFrameobjSeries([4,7,-5,3],index[d,b,a,c])
objobj[[d,c]]obj[b]6
obj
obj*2obj[obj>2]np.exp(obj)sdata{hi:35,mi:49,ji:59,ki:89} #由字典创建序列
obj1Series(sdata)
obj1sta…
Dataframe 常用操作手册
官方文档:https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.dtypes.html 文章目录1 df的构造1.1 读取excel.csv1.2 字典/series转df1.3 多个df操作1.4 df 属性值df.info()df.head(5)df.indexdf.columnsdf.shapedf.describe()df.items(…

pandas之DataFrame基础
pandas之DataFrame基础1. DataFrame定义2. DataFrame的创建形式3. DataFrame的属性4. DataFrame的运算5. pandas访问相关操作5.1 使用 loc[]显示访问5.2 iloc[] 隐式访问5.3 总结6. 单层索引和多层级索引6.1 索引种类与使用6.2 索引相关设置6.3 索引构造6.4 索引访问6.5 索引变…
1.python3数据读取、新建sheet写入数据
笔记说明:超链接加不进来!!!一加进来就卡死,真是崩溃!openpyxl这块不是我写的,是从一个人的博客上摘下来的。 就是下面这个。 https://blog.csdn.net/weixin_43094965/article/details/82226263…
dataframe 查找的isin()用法
import pandas as pddf pd.read_excel(分类标准-新.xlsx)#list0[7662,7667,7672,7677,7682,7688,7693,7698,7704,7662,7709,7714,7719,7725,7730,7735,7741,7709,7746,7751,7756,7762,7767,7772,7778,7746,7783,7783]
list0[7664,7669,7674,7679,7684,7690,7695,7700,7706,766…

Pandas中DataFrame和array相互转化(DataFrame数据直接水平合并)
Pandas中DataFrame和array相互转化(DataFrame数据合并,非concat)
最近在写一个案例处理数据的时候,总是遇到DataFrame和array相互转化的问题,特此记录下来!
先说好本文章不是指DataFrame中的merge、join、…
Pandas:DataFrame对象的基础操作
DataFrame对象的创建,修改,合并 import pandas as pd
import numpy as np
创建DataFrame对象
# 创建DataFrame对象
df pd.DataFrame([1, 2, 3, 4, 5], columns[cols], index[a,b,c,d,e])
print df cols
a 1
b 2
c 3
d 4
e 5df2 …
29 Python的pandas模块
概述 在上一节,我们介绍了Python的numpy模块,包括:多维数组、数组索引、数组操作、数学函数、线性代数、随机数生成等内容。在这一节,我们将介绍Python的pandas模块。pandas模块是Python编程语言中用于数据处理和分析的强大模块&a…
pandas教程:Data Transformation 数据变换、删除和替换
文章目录 7.2 Data Transformation(数据变换)1 删除重复值2 Transforming Data Using a Function or Mapping(用函数和映射来转换数据)3 Replacing Values(替换值)4 Renaming Axis Indexes(重命…

python之pandas.concat()连接函数
文章目录1 函数原型2 常用的参数含义3 举例1 函数原型
pd.concat(objs, axis0, joinouter, join_axesNone, ignore_indexFalse,keysNone, levelsNone, namesNone, verify_integrityFalse,copyTrue)2 常用的参数含义
obj:为Series、DataFrame、Pannel对象的序列或映…

pandas 如何获取dataframe的行的数量
pandas的dataframe提供了多种方法获取其中数据的行的数量,本偏文章就是介绍几种获取dataframe行和列出量的方法。
为了能够详细说明如何通过代码获取dataframe的行数和列数,需要先创建一个dataframe如下:
import pandas as pdtechnologies …
数据分析系列 之python中拓展库SciPy的使用
1 概述: SciPy中的数据结构: ndarray(N维数组) Series(变长字典) DataFrame(数据框)
常用的库: NumPy:强大的ndarray对象和ufunc函数,比较适合线性代数和随机数处理等科学计算,具有有效的通用多维数据&…
Pandas Dataframe 的学习笔记
Pandas Dataframe 的学习笔记 0. Pandas 简介1. 为什么要用 Pandas?2. Series3. DataFrame3-1. 创建 DataFrame3-2. 选择数据3-3. 数据过滤3-4. 修改 DataFrame3-5. 数据清洗3-6. 数据合并3-7. info()3-8. head()3-9. tail()3-10. fillna() 0. Pandas 简介
想象一下…
pandas dataframe 中 explode()函数用法及效果
最近在使用pyspark处理数据,需要连接各种各样的表和字段,因此记录相关函数的使用情况。今天介绍explode().
1. explode()函数简介 explode 函数是 pandas.DataFrame 类的一个方法,能够通过pyspark间接调用。 它可以将一个包含list或者其它可…

Python3 df.loc和df.iloc函数用法及提取指定行列位置处数值
关于pandas.dataframe.loc与pandas.dataframe.iloc用法官方说明,见官网。 df.loc和df.iloc函数用法的df,由pandas.read_csv()函数读取文件而来。
1. DataFrame.loc
Access a group of rows and columns by label(s) or a boolean array. .loc[] is pri…

PySpark中DataFrame的join操作
内容导航
类别内容导航机器学习机器学习算法应用场景与评价指标机器学习算法—分类机器学习算法—回归机器学习算法—聚类机器学习算法—异常检测机器学习算法—时间序列数据可视化数据可视化—折线图数据可视化—箱线图数据可视化—柱状图数据可视化—饼图、环形图、雷达图统…
Pandas中DataFrame的属性、方法、常用操作以及使用示例
前言 系列文章目录 [Python]目录 视频及资料和课件 链接:https://pan.baidu.com/s/1LCv_qyWslwB-MYw56fjbDg?pwd1234 提取码:1234 文章目录前言1. DataFrame 对象创建1.1 通过列表创建 DataFrame 对象1.2 通过元组创建 DataFrame 对象1.3 通过集合创建 …
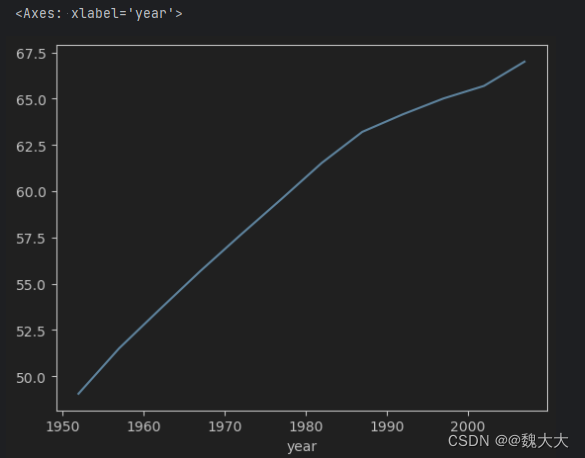
数据分析-Pandas如何轻松处理时间序列数据
Pandas-如何轻松处理时间序列数据
时间序列数据在数据分析建模中很常见,例如天气预报,空气状态监测,股票交易等金融场景。此处选择巴黎、伦敦欧洲城市空气质量监测 N O 2 NO_2 NO2数据作为样例。
python数据分析-数据表读写到pandas
经典…
Pandas学习笔记(DataFrame基本操作)
对于生成的dDataFrame,下一步进行的是对他的基本操作,增、减、改、查。
一. 数据选取 从已有的DataFrame中取出其中一列或几列,并对其进行操作。 Pandas取出DataFrame的列有两种方式,两个方式没有好与坏之分,还是看个…

Pandas-DataFrame构造
一. DataFrame的构造方式
1. 通过list或numpy数组构造DF # -*- coding:utf-8 -*-
import pandas as pddf pd.DataFrame([data [a, b, c], [d, e, f],[g, h, i]],columns [field1, field2, field3]) 这是最简单的创建形式,传入的list一般是多维度的,且…
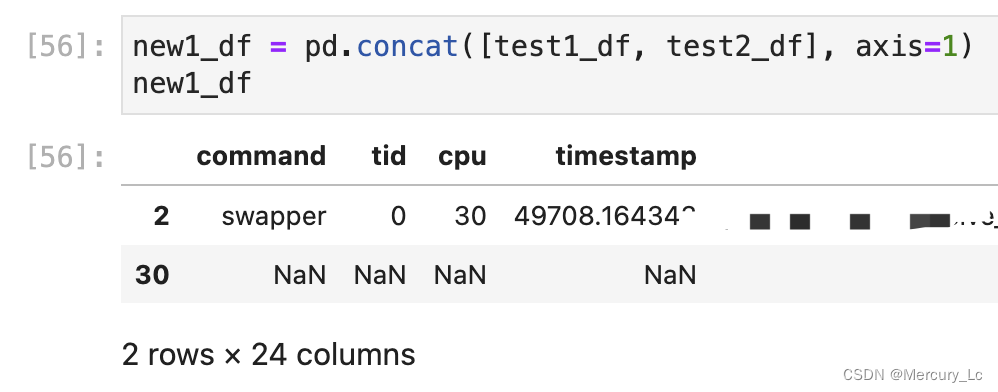
【Python】DataFrame 使用 concat 横向拼接出现两行问题
问题
在使用 DataFrame 中 concat 横向拼接两个只有一行的 DataFrame 时,最终的结果有两行。
如下图:
原始的 df 分别为: 指定横向合并后是: 这里可以看到是横向拼接了,但是并没有真正意义的横向拼接,而…

Python pandas 各类 操作 备忘
>>> import pandas as pd
>>> factors{2021:36.45,2020:35.43,2019:34.65,2018:33.9,2017:33.14}
# 必须加index,index中是列表,列表个数,即为记录数。 # 下面是以关键字为列名,共5列 >>> df pd.DataFrame(fac…