java-rocketmq
机器学习
神经网络
爱心捐赠
慈善捐赠管理
OD
教育电商
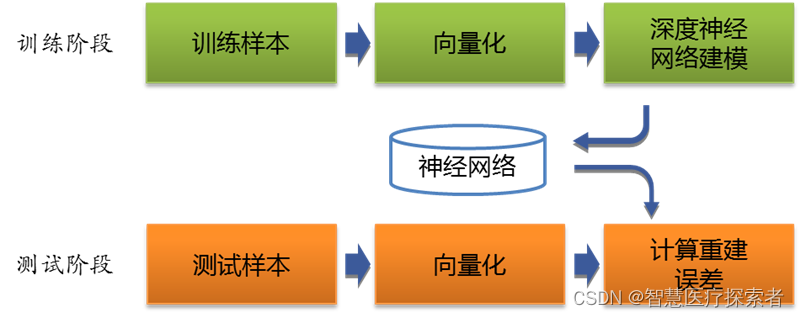
图像阴影消除
智能家居
cdh
makefile
魔百盒刷机
go
bi
跨境电商
433MHz自发电无线控制器
主备
多版本并发控制机制
系统安全
P3C
词向量
2024/4/12 21:30:53
自然语言处理中词嵌入降维方法-Random Fourier Feature
Random Fourier Feature介绍代码测试小结介绍 RandomFourierFeatures(RFF)Random Fourier Features (RFF)RandomFourierFeatures(RFF)是一种用于处理高维数据的技术,它通过将高维输入数据映射到低维的随机特征空间来加速核方法的计算。这种技术特别适用于处理大规模…
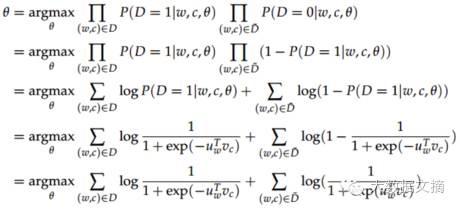
深度学习与自然语言处理(1)_斯坦福cs224d Lecture 1
作者:寒小阳 && 龙心尘 时间:2016年6月 出处: http://blog.csdn.net/han_xiaoyang/article/details/51567822 http://blog.csdn.net/longxinchen_ml/article/details/51567960 声明:版权所有,转载请联系作者并…


word2vec的原理及实现(附github代码)
目录
一、word2vec原理
二、word2vec代码实现
(1)获取文本语料
(2)载入数据,训练并保存模型
① # 输出日志信息
② # 将语料保存在sentence中
③ # 生成词向量空间模型
④ # 保存模型
(3&…
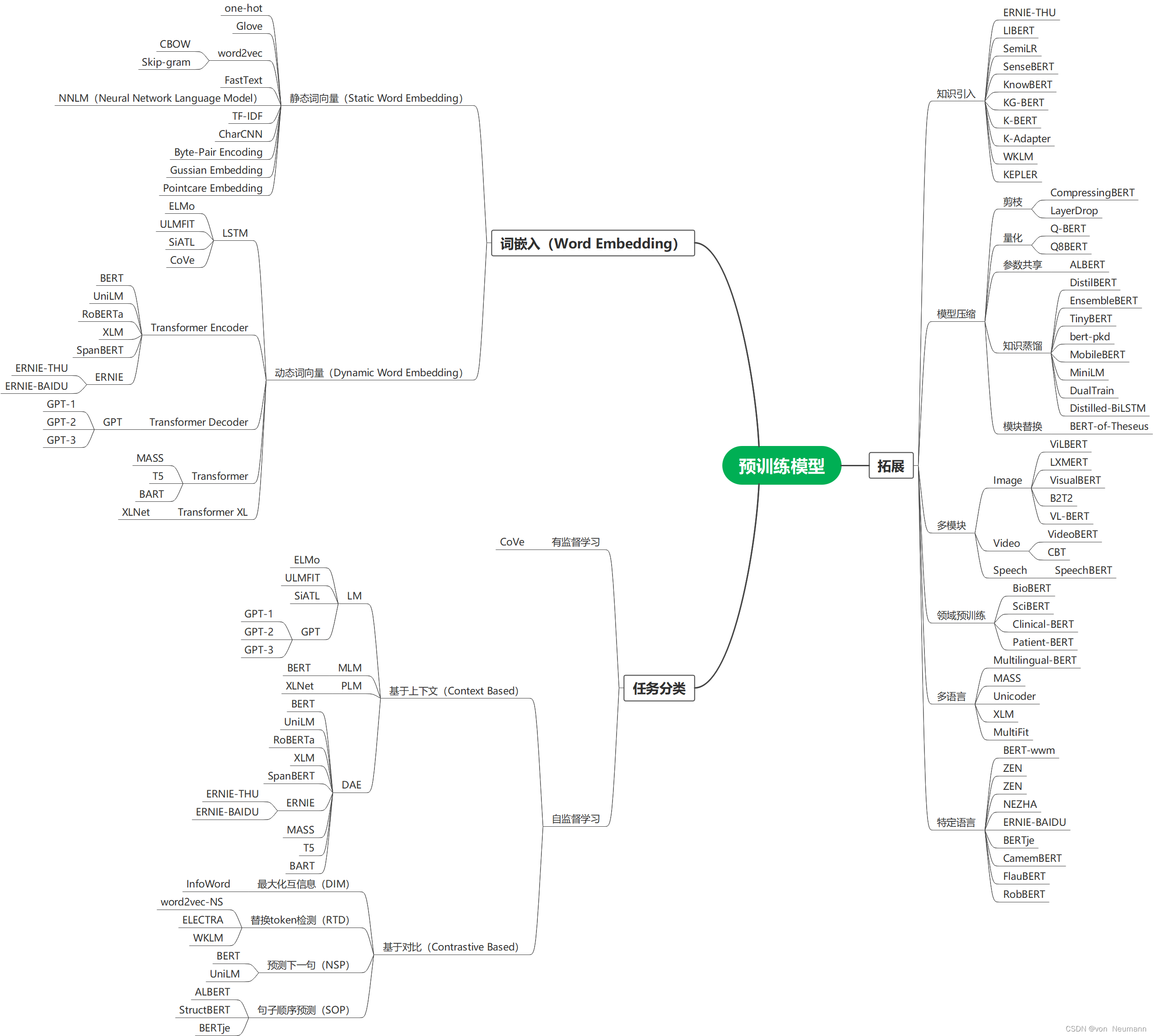
自然语言处理从入门到应用——预训练模型总览:词嵌入的两大范式
分类目录:《自然语言处理从入门到应用》总目录 相关文章: 预训练模型总览:从宏观视角了解预训练模型 预训练模型总览:词嵌入的两大范式 预训练模型总览:两大任务类型 预训练模型总览:预训练模型的拓展 …
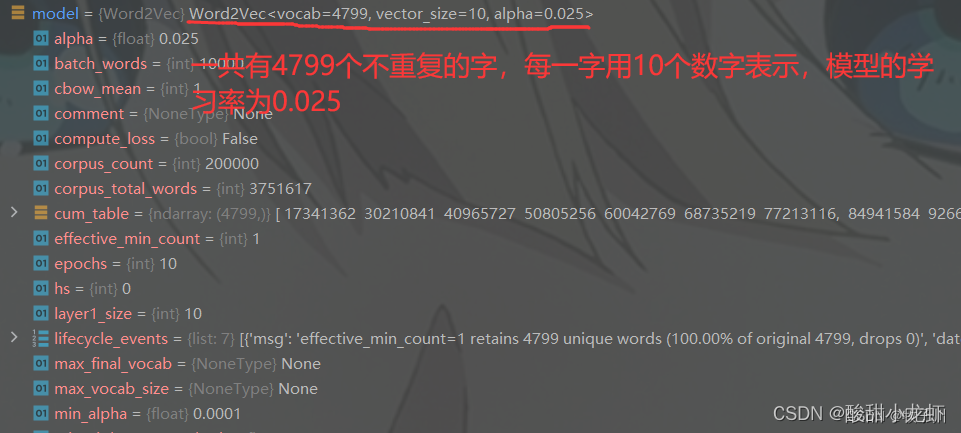
【NLP】如何实现快速加载gensim word2vec的预训练的词向量模型
1 问题
通过以下代码,实现加载word2vec词向量,每次加载都是几分钟,效率特别低。
from gensim.models import Word2Vec,KeyedVectors# 读取中文词向量模型(需要提前下载对应的词向量模型文件)
word2vec_model KeyedV…

NLP----神经网络语言模型(NNLM),词向量生成,词嵌入,python实现
理论主要来自论文A Neural Probabilistic Language Model,可以百度到的
这篇博文对理论方面的介绍挺不错的 链接地址
一下是其中的一些截图,主要是算法步骤部分
算法步骤
前向计算 反向更新 个人实现的代码
import glob
import random
import ma…
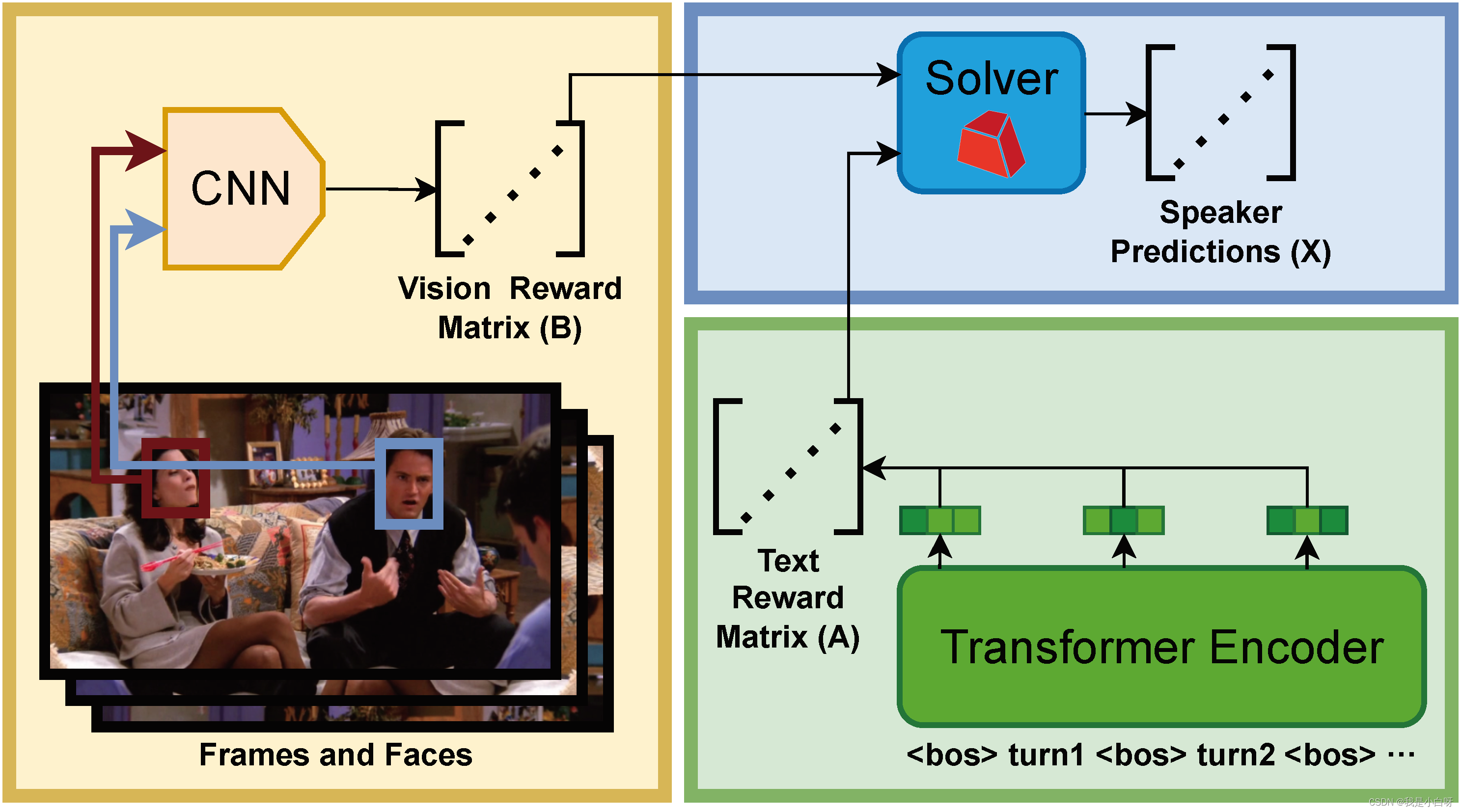
【CCF BDCI 2023】多模态多方对话场景下的发言人识别 Baseline 0.71 NLP 部分
【CCF BDCI 2023】多模态多方对话场景下的发言人识别 Baseline 0.71 NLP 部分 概述NLP 简介文本处理词嵌入上下文理解 文本数据加载to_device 函数构造数据加载样本数量 len获取样本 getitem 分词构造函数调用函数轮次嵌入 RobertaRoberta 创新点NSP (Next Sentence Prediction…
使用sklearn生成TF-IDF词向量
写一个使用sklearn生成TF-IDF词向量的模板函数:
from sklearn import feature_extraction # 导入sklearn库, 以获取文本的tf-idf值
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.feature_extraction.text import CountVectorizerde…
pytorch nn.Embedding 读取gensim训练好的词/字向量(有例子)
最近在跑深度学习模型,发现Embedding随机性太强导致模型结果有出入,因此考虑固定初始随机向量,既提前训练好词/字向量,不多说上代码!!
1、利用gensim训练字向量(词向量自行修改)
#…
深度学习文本预处理利器:Tokenizer详解
目录 1 Tokenizer 介绍
1.1 Tokenizer定义 1.2 Tokenizer方法 1.3 Tokenizer属性
2 Tokenizer文本向量化
2.1 英文文本向量化
2.2 中文文本向量化
3 总结 1 Tokenizer 介绍
Tokenizer是一个用于向量化文本,将文本转换为序列的类。计算机在处理语言文字时&…
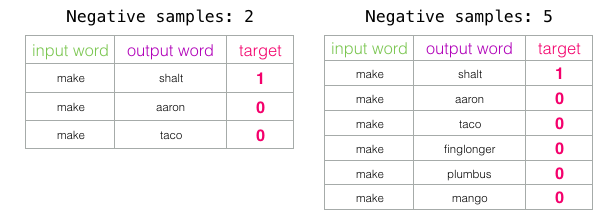
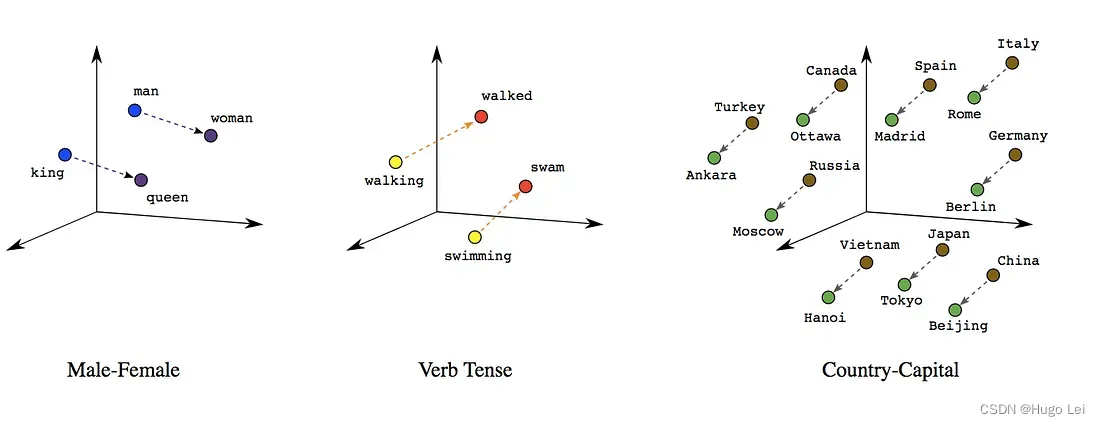
图解Word2vec
作者: 龙心尘 时间:2019年4月 出处:https://blog.csdn.net/longxinchen_ml/article/details/89077048
审校:龙心尘 作者:Jay Alammar 编译:张秋玥、毅航、高延 嵌入(embedding)是机…
![集成多元算法,打造高效字面文本相似度计算与匹配搜索解决方案,助力文本匹配冷启动[BM25、词向量、SimHash、Tfidf、SequenceMatcher]](https://img-blog.csdnimg.cn/d553c7dadca54bdb82a3a234befb74d8.png#pic_center)
集成多元算法,打造高效字面文本相似度计算与匹配搜索解决方案,助力文本匹配冷启动[BM25、词向量、SimHash、Tfidf、SequenceMatcher]
搜索推荐系统专栏简介:搜索推荐全流程讲解(召回粗排精排重排混排)、系统架构、常见问题、算法项目实战总结、技术细节以及项目实战(含码源) 专栏详细介绍:搜索推荐系统专栏简介:搜索推荐全流程讲解(召回粗排精排重排混排)、系统架构、常见问题、算法项目实战总结、技术…
LLM资料:中文embedding库
Highlight(重点提示)
理解LLM,就要理解Transformer,但其实最基础的还是要从词的embedding讲起。
毕竟计算机能处理的只有数字,所以万事开头的第一步就是将要处理的任务转换为数字。 面向中文的开源embedding库在自然…
深度学习(二):详解Word2Vec,从统计语言模型,神经网络语言模型(NNLM)到Hierarchical Softmax、Negative Sampling的CBOW和Skip gram
首先计算机只认识01数字,要对文本进行处理就需要将单词进行向量化
单词的向量化表示方法 独热表示one-hot
最早对于单词向量化使用的是独热表示。每个单词对应一个向量,这个向量维度等于词汇表的大小,也就是说我有一个词汇表,里…
解决fasttext内存不足无法读取模型的问题
fasttext是个好东西,是由facebook在2016年推出的一个训练词向量的模型。相比于之前Google的word2vec,fasttext可以解决out of vocabulary的问题。fasttext还能够用于有监督的文本分类。更赞的是,facebook提供了200多种语言的预训练模型和词向…
深度学习:pytorch nn.Embedding详解
目录 1 nn.Embedding介绍
1.1 nn.Embedding作用
1.2 nn.Embedding函数描述
1.3 nn.Embedding词向量转化
2 nn.Embedding实战
2.1 embedding如何处理文本
2.2 embedding使用示例
2.3 nn.Embedding的可学习性 1 nn.Embedding介绍
1.1 nn.Embedding作用
nn.Embedding是Py…
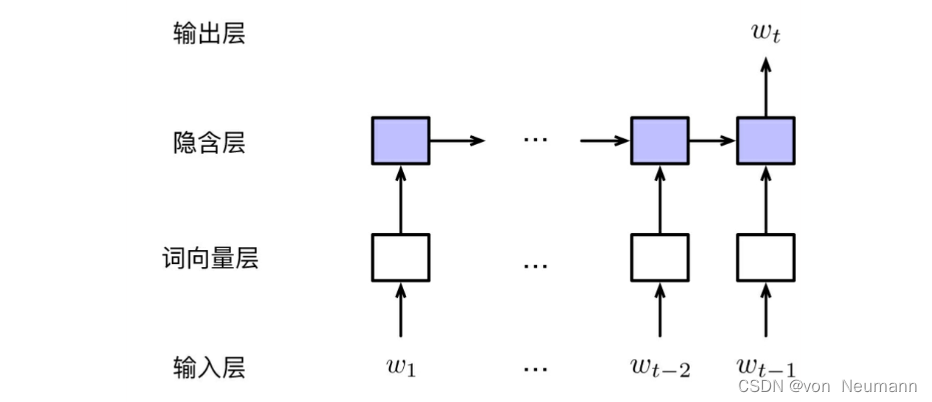
自然语言处理从入门到应用——静态词向量预训练模型:神经网络语言模型(Neural Network Language Model)
分类目录:《自然语言处理从入门到应用》总目录 《自然语言处理从入门到应用——自然语言处理的语言模型(Language Model,LM)》中介绍了语言模型的基本概念,以及经典的基于离散符号表示的N元语言模型(N-gram…
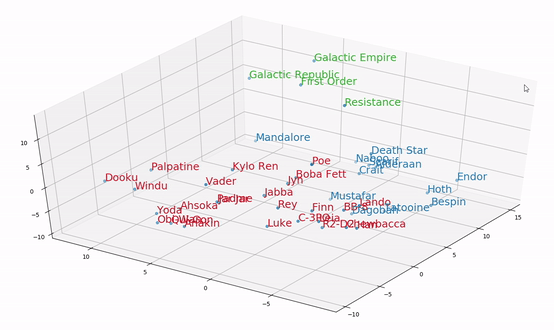
AI小百科 - 什么是词向量?
如何表示一个单词的意义?对人来说,一般用解释法,用一段话来解释词的含义。如“太阳”在新华字典中的释义是“太阳系的中心天体。银河系的一颗普通恒星。”然而,这样的解释计算机是听不懂的,必须用更简洁的方式来对词义…
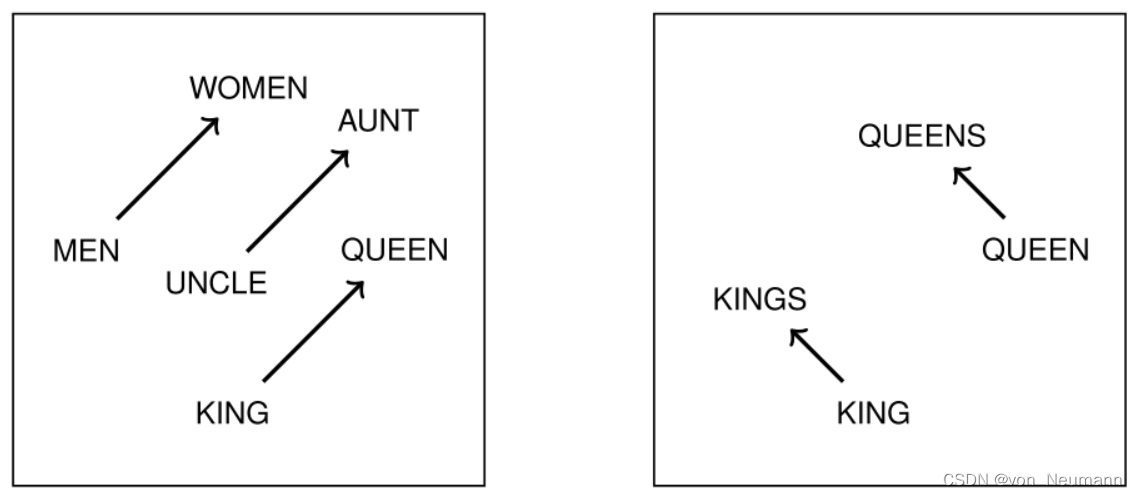
自然语言处理从入门到应用——词向量的评价方法
分类目录:《自然语言处理从入门到应用》总目录 对于不同的学习方法得到的词向量,通常可以根据其对词义相关性或者类比推理性的表达能力进行评价,这种方式属于内部任务评价方法(Intrinsic Evaluation)。在实际任务中&am…

NLP文本分类--词向量
1.基于规则,对于要提取的分类维护一个dict,在dict里面保存需要提取的关键词,存在关键词的对应标记为分类;(缺点,不断的去维护词典) 2.基于机器学习:HMM(分词最常用的),CRF,SVM,LDA,C…
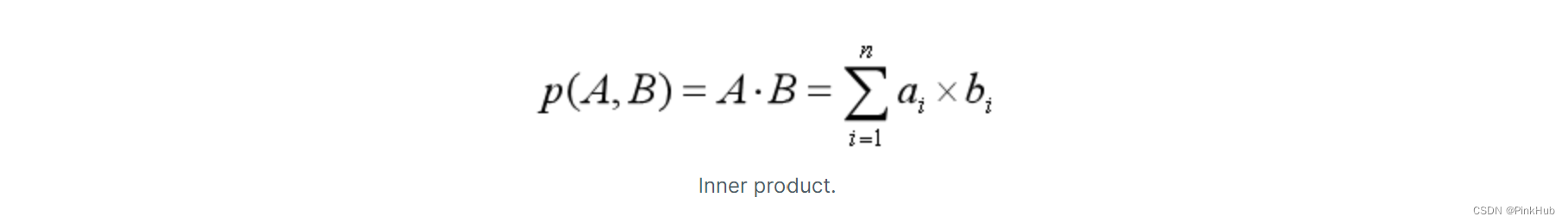
Milvus向量数据库
Milvus vector database
第一章 Milvus概述
Milvus创建于2019年,唯一的目标是:存储、索引和管理由深度神经网络和其他机器学习(ML)模型生成的大量嵌入向量embedding vectors。
存储对象:向量
NOTE:embedding vectors是对非结构…
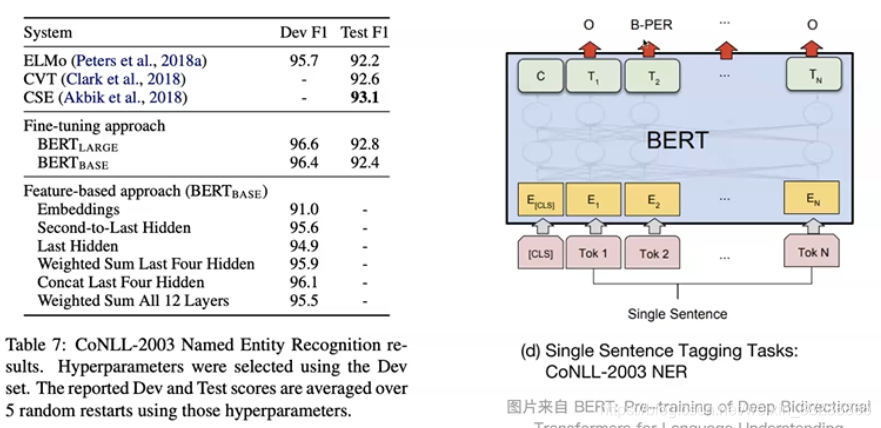
bert简单介绍和实践
bert模型是Google在2018年10月发布的语言表示模型,在NLP领域横扫了11项任务的最优结果,可以说是现今最近NLP中最重要的突破。Bert模型的全称是Bidirectional Encoder Representations from Transformers,是通过训练Masked Language Model和预…