Abstract
在本文中,我们采用了一种仅限变压器的车道检测方法,因此它可以受益于
vision transformer
的蓬勃发展,并通过微调在大数据集上完全预训练的权重,在CULane和TuSimple基准上实现了最先进的(SOTA)性能。
更重要的是,本文提出了一种新颖的通用框架PriorLane,该框架通过引入低成本的局部先验知识来提高全视觉转换器的分割性能。
知识嵌入对齐(KEA)模块可以通过对齐知识嵌入来提高融合性能。
本文采用带有分层编码器的纯视觉Transformer对图像中的车道标记进行分割,称为混合Transforme(MiT)
提出了一种称为PriorLane的通用融合框架,利用先验知识来提高MiT块的性能。
局部先验知识数据用鸟瞰视图(BEV)中的网格图表示,然后PriorLane将网格图切割成patches,然后用可训练的线性投影进行映射
设计了一个相应的知识嵌入对齐(KEA)模块,对嵌入进行空间对齐。
Contributions
采用一种新型的融合变压器(FT),将通过MiT块提取的图像特征与先验知识数据的嵌入进行融合。
采用多层感知器(MLP)块,将融合后的特征与纯MiT特征进行合并,并输出分割预测的像素级结果。
据我们所知,我们首次采用了只有Transformer的架构来进行车道检测,它可以受益于Transformer预训练的发展,
提出了一种新的通用框架PriorLane,通过将图像特征与低成本的局部先验知识相结合,提高了车道分割的性能
KEA块进一步用于先验知识对齐
III. METHOD

Mix Transformer
生成分层特征
Knowledge Embedding Alignment.
知识嵌入对齐。由于车辆的位置比较粗糙,因此很难确定在BEV中嵌入的与摄像机视图相一致的参考知识。为了解决这个问题,需要一个知识嵌入对齐(KEA)模块来将知识嵌入与图像特征进行空间对齐
Fusion Transformer.
Architecture on benchmarks
ARFs)和ORpool[24]、[25]分别从先验知识嵌入中提取方向信息并保持旋转信息不变
带有一个通道的网格地图,而0/1表示相应的网格是否在道路自由空间中
这样,先验知识被呈现为“大图像”,一旦给出感知范围,局部先验知识可以表示为较小的知识。
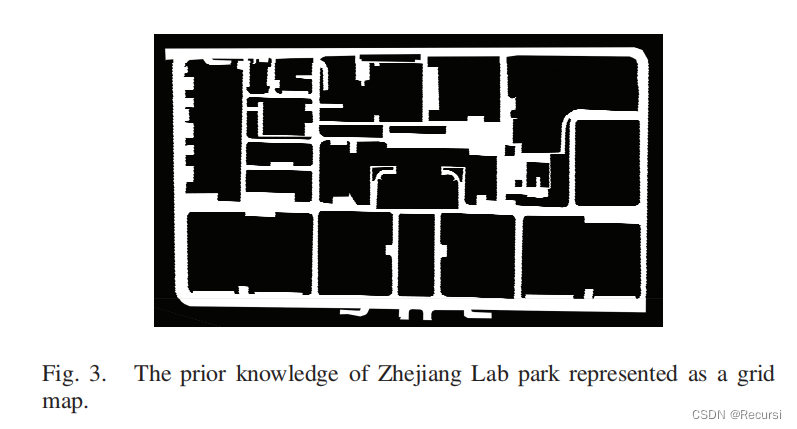
Knowledge Embedding.
首先,我们将局部网格地图数据M∈RH×W×C切成补丁,每个补丁的大小是P×P。此外,每个补丁转换成一个向量大小1××线性投影,因此当地先验知识表示为“知识嵌入”,用X表示,相应的大小为(H/P)×(W/P)×Ep。
C. Knowledge Embedding Alignment
在本节中,空间变压器网络(STN)[23]被调整用于对齐KEA模块中的嵌入。STN可以根据定位网络得到的仿射变换矩阵对先验知识的嵌入进行操作,从而提高先验知识与图像特征的融合性能。
IV. EXPERIMENTS
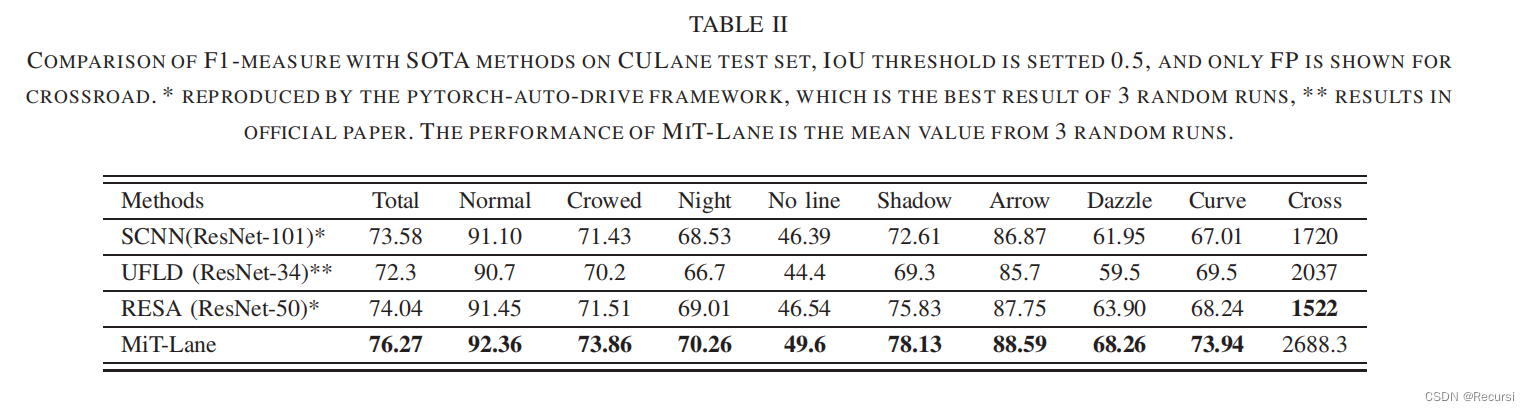
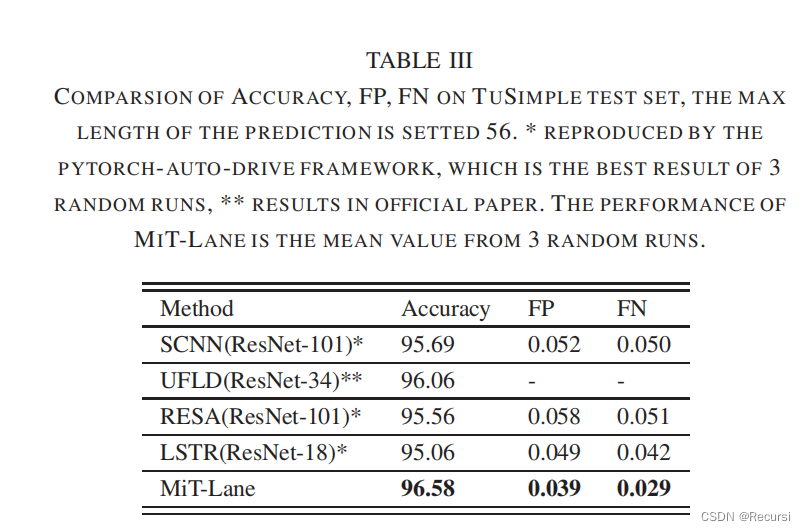
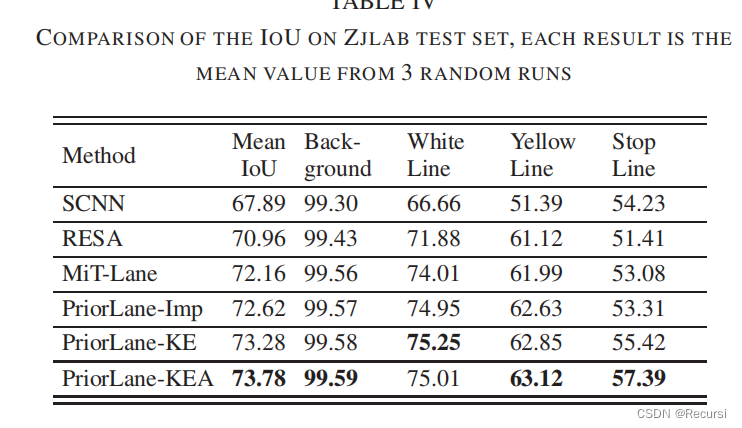
D. Ablation Study
Number of Encoder Layers.
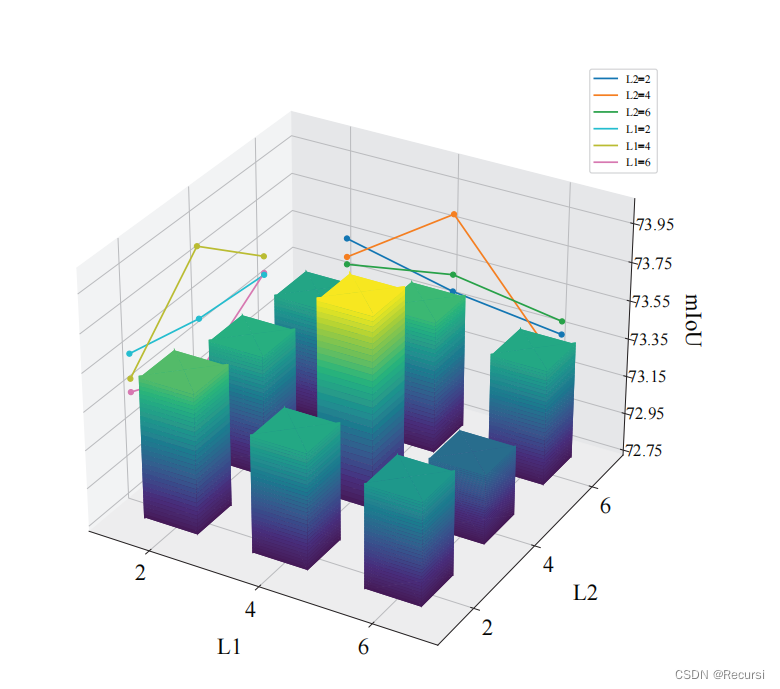
知识编码器层可以作为特征细化器,更深的层产生更高的语义特征,有助于分割性能。然而,较大的L1降低了模型的泛化性,导致峰值后mIoU的降低。
Inflfluence of Perception Range.
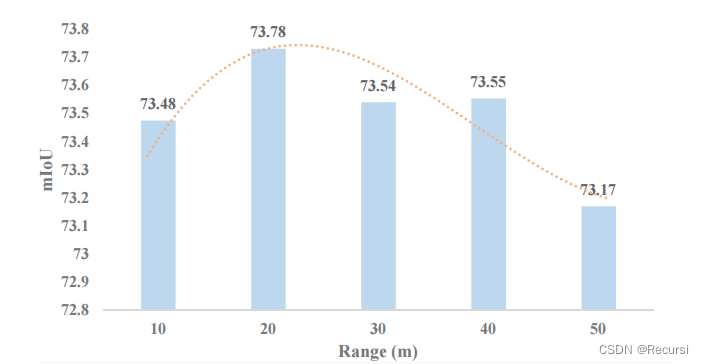
但该距离内的图像分辨率较低,模型难以计算出低分辨率特征与相应的先验知识之间的注意力,因此,当感知范围太大时,注意力会降低。



![[蓝桥杯 2021 国 ABC] 123](/images/no-images.jpg)

