transformer___0">transformer机制 – 潘登同学的深度学习笔记
文章目录
- transformer机制 -- 潘登同学的深度学习笔记
- 应用了残差思想的self-Attention Encoder
- 加入位置信息Position Embedding
- transformer模型详解
- Decoder的第一层self-Attention
- Decoder的第二层self-Attention
- 理解为啥第二层不需要做mask
应用了残差思想的self-Attention Encoder

简单来说就是每一层的输入都会加到每一层的结果上去,然后做Layer Normalization
加入位置信息Position Embedding
注意到前面说的Self-attention是没有位置信息的,对于相同输出
b
1
,
b
3
b_1,b_3
b1,b3来说,输入句子我爱你 与 你爱我, 得到的
b
1
,
b
3
b_1,b_3
b1,b3是相同的,因为都是我然后其他两个字都是你和爱, 根据上面计算图计算出来的都是相等的,所以Transformer 模型用到Position Embedding; 这是因为Transformer 摒弃了之前机器翻译任务中常用的 RNN 结构,使得并行性更好。RNN的这种结构天生考虑了词语的先后顺序关系。当 Transformer 模型不使用 RNN 结构时,它就要想办法通过其它机制把位置信息传输到 Encoding 的部分。所以在该模型中,每个时刻的输入是 Word Embedding+Position Embedding
在原论文中是拿了一个预训练的Position Embedding,直接与Embedding层进行加和,得到Encoder的输入,其实也可以自己训练,原理就是在词向量加上位置信息的向量,如下图所示

对输入 x l ∗ 1 x_{l*1} xl∗1拼接上一个位置向量,扔到Embedding层中去等同于,用一个位置矩阵 W K ∗ P W_{K*P} WK∗P与位置向量 P P ∗ 1 P_{P*1} PP∗1相乘得到的 e K ∗ 1 e_{K*1} eK∗1 加上 词嵌入矩阵 W K l W_{K_l} WKl与词向量 x l ∗ 1 x_{l*1} xl∗1相乘得到的 α K ∗ 1 \alpha_{K*1} αK∗1;

transformer_25">transformer模型详解
整体模型
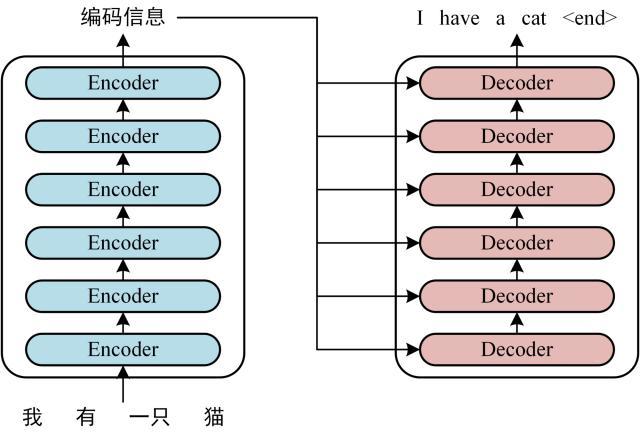
模型内部
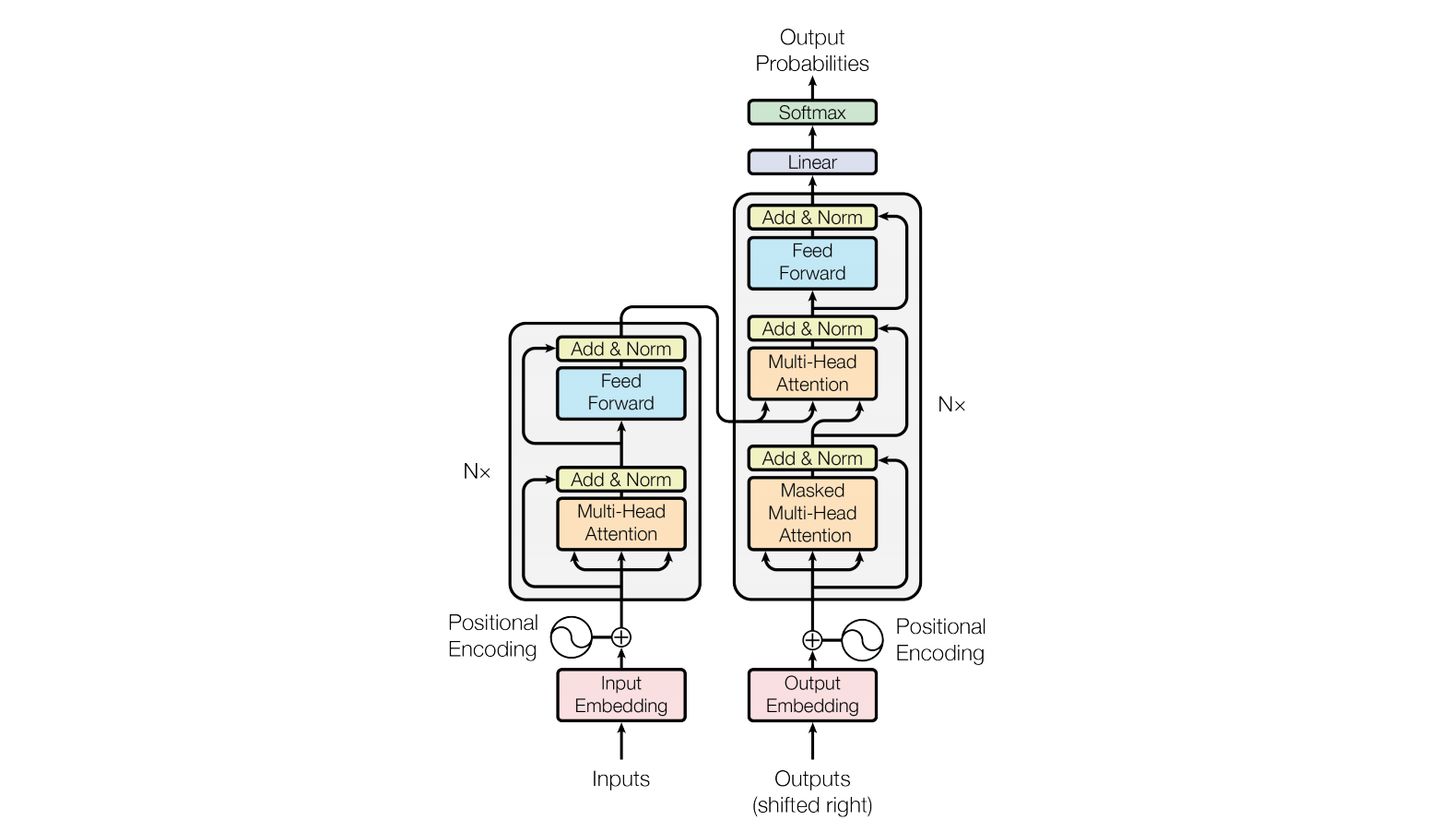
Encoder部分我们已经研究的比较透彻了,现在重点关注Decoder层,一个Decoder有两层,一层是self-Attention,另一层也是Self-Attention,但是这两者略有不同
Decoder的第一层self-Attention
Decoder block 的第一个 Multi-Head Attention 采用了 Masked 操作,因为在翻译的过程中是顺序翻译的,即翻译完第 i 个单词,才可以翻译第 i+1 个单词。通过 Masked 操作可以防止第 i 个单词知道 i+1 个单词之后的信息。
算法步骤(引用自Transformer模型详解)
- Decoder 的输入矩阵和 Mask 矩阵,输入矩阵包含 “
<
B
e
g
i
n
>
<Begin>
<Begin> I have a cat” (0, 1, 2, 3, 4) 五个单词的表示向量,Mask 是一个 5×5 的矩阵。在 Mask 可以发现单词 0 只能使用单词 0 的信息,而单词 1 可以使用单词 0, 1 的信息,即只能使用之前的信息。
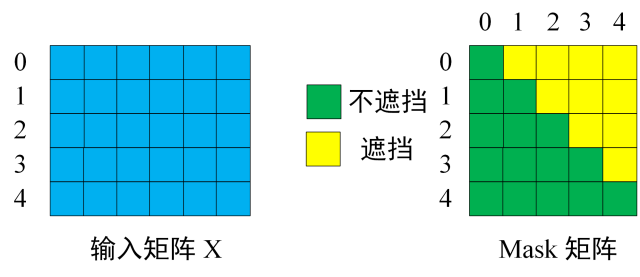
- 和之前的 Self-Attention 一样,通过输入矩阵X计算得到Q,K,V矩阵。然后计算Q和 K T K^T KT 的乘积 Q K T QK^T QKT
- 在得到
Q
K
T
QK^T
QKT 之后需要进行 Softmax,计算 attention score,我们在 Softmax 之前需要使用Mask矩阵遮挡住每一个单词之后的信息,遮挡操作如下
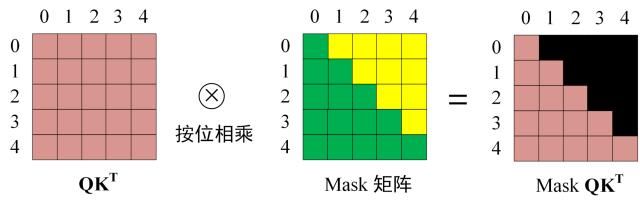
得到 Mask Q K T QK^T QKT 之后在 Mask Q K T QK^T QKT上进行 Softmax,每一行的和都为 1。但是单词 0 在单词 1, 2, 3, 4 上的 attention score( b 1 , 1 , … , b 1 , 4 b_{1,1},\ldots,b_{1,4} b1,1,…,b1,4) 都为 0。 - 使用 Mask
Q
K
T
QK^T
QKT与矩阵 V相乘,得到输出 Z,则单词 1 的输出向量
Z
1
Z_1
Z1 是只包含单词 1 信息的。
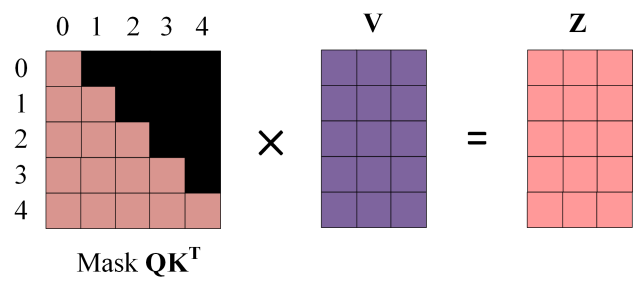
- 通过上述步骤就可以得到一个 Mask Self-Attention 的输出矩阵 Z i Z_i Zi ,然后和 Encoder 类似,通过 Multi-Head Attention 拼接多个输出 Z i Z_i Zi 然后计算得到第一个 Multi-Head Attention 的输出Z,Z与输入X维度一样
Decoder的第二层self-Attention
第二层self-Attention与Encoder中self-Attention主要的区别在于其中 Self-Attention 的 K, V矩阵不是使用 上一个 Decoder block 的输出计算的,而是使用 Encoder 的编码信息矩阵 C 计算的。
简单来说,就是输入self-Attention的有两个向量,一个向量是从Encoder的output拿过来与矩阵 W K , W V W^K,W^V WK,WV相乘,得到 K, V ;另一个向量是从第一层self-Attention中拿过来,与矩阵 W Q W^Q WQ相乘得到Q矩阵;然后后续的计算方法与Encoder部分一样
tention中拿过来,与矩阵 W Q W^Q WQ相乘得到Q矩阵;然后后续的计算方法与Encoder部分一样
理解为啥第二层不需要做mask
回想Self-Attention,是用Q分别与K內积,得到相似度权重,最后与V相乘得到上下文向量;这点很关键,因为第一层mask输出结果当做Q,Encoder的输出当做KV,Q只要一个,而KV有很多,这满足了self-attention的要求(我就是搞反Q和V了, 死活也想不明白, 为什么第二层不做mask)