PTQ、 partialPTQ、 QAT 选择流程
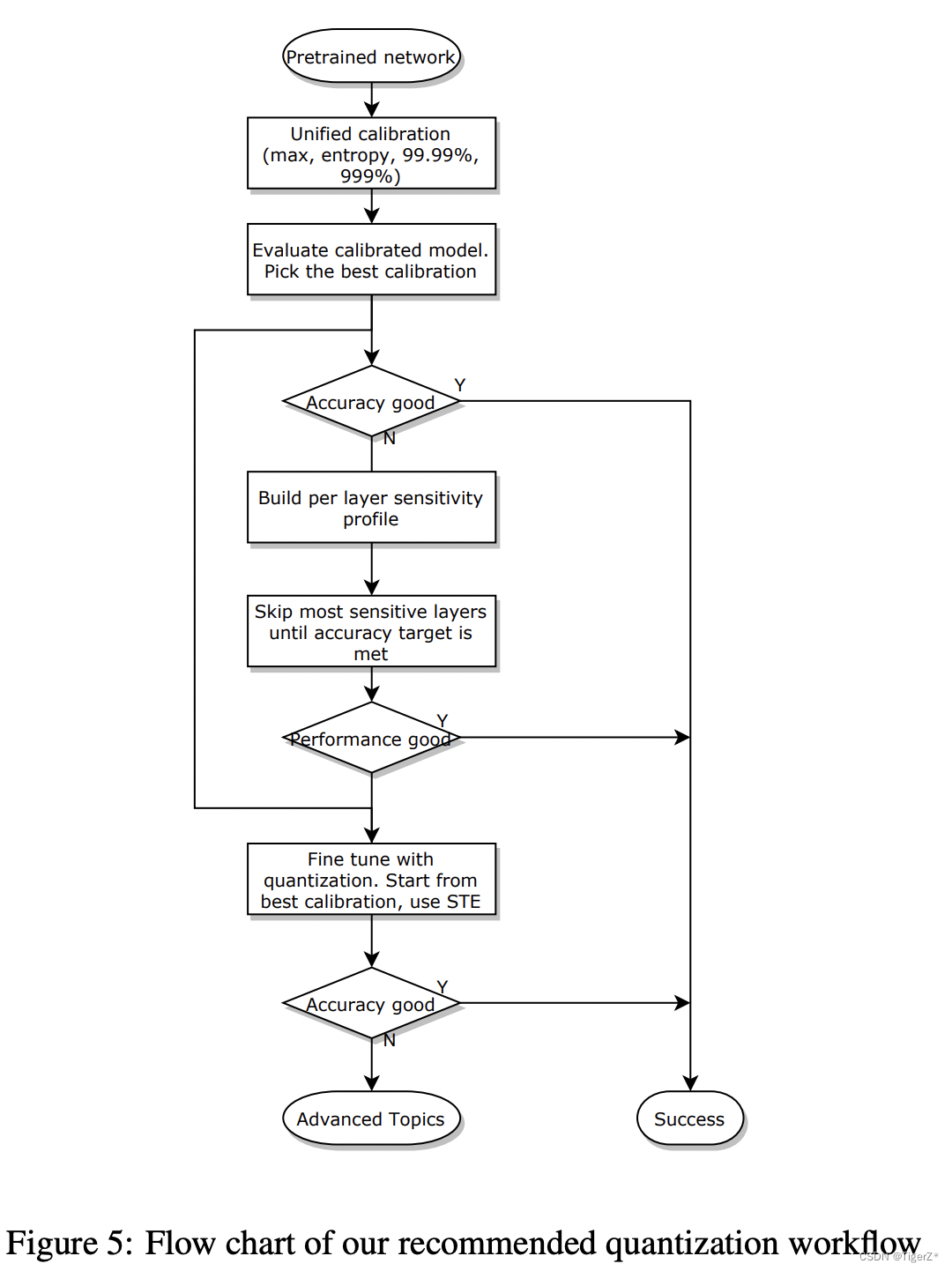
PTQ、 partialPTQ、 QAT 咨询NVIDIA 官方后,他们的校正过程一致,支持的量化算子本质是一样的,那么如果你的算子不是如下几类,那么需要自己编写算子。参考TensorRT/tools/pytorch-quantization/pytorch_quantization/nn/modules/quant_conv.py at release/8.6 · NVIDIA/TensorRT · GitHub
QuantConv1d, QuantConv2d, QuantConv3d,
QuantConvTranspose1d, QuantConvTranspose2d, QuantConvTranspose3d
QuantLinear
QuantAvgPool1d, QuantAvgPool2d, QuantAvgPool3d,
QuantMaxPool1d, QuantMaxPool2d, QuantMaxPool3d
QuantAdaptiveAvgPool1d, QuantAdaptiveAvgPool2d, QuantAdaptiveAvgPool3d
Clip
QuantLSTM, QuantLSTMCell
一些知识点
1、As well as quantizing activations, TensorRT must also quantize weights. It uses symmetric quantization with a quantization scale calculated using the maximum absolute values found in the weight tensor. For convolution, deconvolution, and fully connected weights, scales are per-channel. With explicit quantization, weights can be quantized using per-tensor quantization or they can be quantized using per-channel quantization. In either case, the scale precision is FP32. Activation can only be quantized using per-tensor quantization. When using per-channel quantization, the axis of quantization must be the output-channel axis. For example, when the weights of 2D convolution are described using KCRS notation, K is the output-channel axis。TensorRT supports only per-tensor quantization for activation tensors, but supports per-channel weight quantization for convolution, deconvolution, fully connected layers, and MatMul where the second input is constant and both input matrices are 2D.
总结:TRT8 建议权重为per-channel量化(CNN 权重是四维的!!!,per-channel 对应的是一个激活图对应的三维权重!),激活为per-tensor 量化。
2、Calibration can be slow; therefore the output of step 2 (the calibration table) can be cached and reused. The calibration cache data is portable across different devices as long as the calibration happens before layer fusion. Specifically, the calibration cache is portable when using the IInt8EntropyCalibrator2 or IInt8MinMaxCalibrator calibrators, or when QuantizationFlag::kCALIBRATE_BEFORE_FUSION is set. The calibration cache is in general not portable across TensorRT releases.
总结:校正文件对于同一版本的TRT的不同平台的没有先合并算子的是一致的(包括不同的平台),好处:可以校准一次,生成engine 的时候直接用校准缓存。
3、PyTorch 1.8 introduced support for exporting PyTorch models to ONNX using opset 13.PyTorch 1.8.0 and forward support ONNX QuantizeLinear/DequantizeLinear support per channel scales. You can use pytorch-quantization to do INT8 calibration, run quantization aware fine-tuning, generate ONNX and finally use TensorRT to run inference on this ONNX model. More detail can be found in NVIDIA PyTorch-Quantization Toolkit User Guide.SM 7.5 and earlier devices may not have INT8 implementations for all layers. In this case, you will encounter a could not find any implementation error while building your engine. To resolve this, remove the Q/DQ nodes which quantize the failing layers.
总结:量化需要TRT8+, pytorch 1.8+, onnx opset 13, sm 7.5 (之前的可能一些算子没有int8 实现)
4、TensorRT does not support prequantized ONNX models that use INT8 tensors or quantized operators.By default, do not quantize the outputs of weighted-operations. It is sometimes useful to preserve the higher-precision dequantized output. For example, if the linear operation is followed by an activation function (SiLU, in the following diagram) that requires higher precision input to produce acceptable accuracy. Do not simulate batch-normalization and ReLU fusions in the training framework because TensorRT optimizations guarantee to preserve the arithmetic semantics of these operations. Quantize the residual input in skip-connections. TensorRT can fuse element-wise addition following weighted layers, which are useful for models with skip connections like ResNet and EfficientNet. The precision of the first input to the element-wise addition layer determines the precision of the output of the fusion.
总结:TRT 不支持已经量化后的int8算子(他根据Q、DQ算子自己去优化图,至于所谓的Q DQ算子怎么定义,目前未知)。不要提前合并BN Relu等,TRT 会自动合并这些。具体可以参考最新的介绍:Developer Guide :: NVIDIA Deep Learning TensorRT Documentation
5、INT8 calibration can be used along with the dynamic range APIs. Setting the dynamic range manually overrides the dynamic range generated from INT8 calibration.
6、For networks with implicit quantization, TensorRT attempts to reduce quantization noise in the output by forcing some layers near the network outputs to run in FP32, even if INT8 implementations are available.
排除你指定int8 或者第三方层,TRT会将网络最后几层保留FP32 精度。
7、You can further optimize engine latency by enabling FP16. TensorRT attempts to use FP16 instead of FP32 whenever possible (this is not currently supported for all layer types).
INT8 可以和FP32 混合存在,也可以和FP16混合存在。
8、bs can be set difference between set_calibration_profile and add_optimization_profile?
the int8 engine build has 2 pass, first pass is the calibration, the batch size in calibrator should match the set_calibration_profile, the second pass is the int8 engine build pass, and the batch size is configured from add_optimization_profile.
经验:小模型(YOLO s m)含有repvgg 部件的使用PTQ掉点严重。partialPTQ一般最敏感的就是几乎整个head 的卷积网络。QAT也是先按照PTQ获得校准文件然后finetune 10% epoch.
参考链接
部分量化:YOLOv6/tools/partial_quantization at main · meituan/YOLOv6 · GitHub
QAT : YOLOv6/tools/qat at main · meituan/YOLOv6 · GitHub
NVIDIA 论文:https://arxiv.org/pdf/2004.09602.pdf