论文题目:
ANOMALY TRANSFORMER: TIME SERIES ANOMALY DETECTION WITH ASSOCIATION DISCREPANCY
发表会议:ICLR 2022
论文地址:https://openreview.net/pdf?id=LzQQ89U1qm_
论文代码:https://github.com/thuml/Anomaly-Transformer
目录
- 一、现状总结
- 1.1、利用经典的机器学习方法
- 1.2、通过自监督任务训练一个RNN网络
- 1.3、基于关联建模的方法
- 二、思想概述-基于关联的准则
- 2.1、序列关联
- 2.2、先验关联
- 2.3、关联差异
- 三、解决方法
- 3.1、模型整体架构
- 3.2、Anomaly-Attention
- 3.3、Association Discrepancy
- 3.4、Training Strategy
- 3.4.1、Vanilla Version
- 3.4.2、Minimax Association Learning
- 3.5、Association-based Anomaly Criterion
- 四、试验分析
- 4.1、结果分析
- 4.2、消融实验
- 4.3、异常判据的可视化
- 4.4、先验关联学习尺度的可视化
一、现状总结
1.1、利用经典的机器学习方法
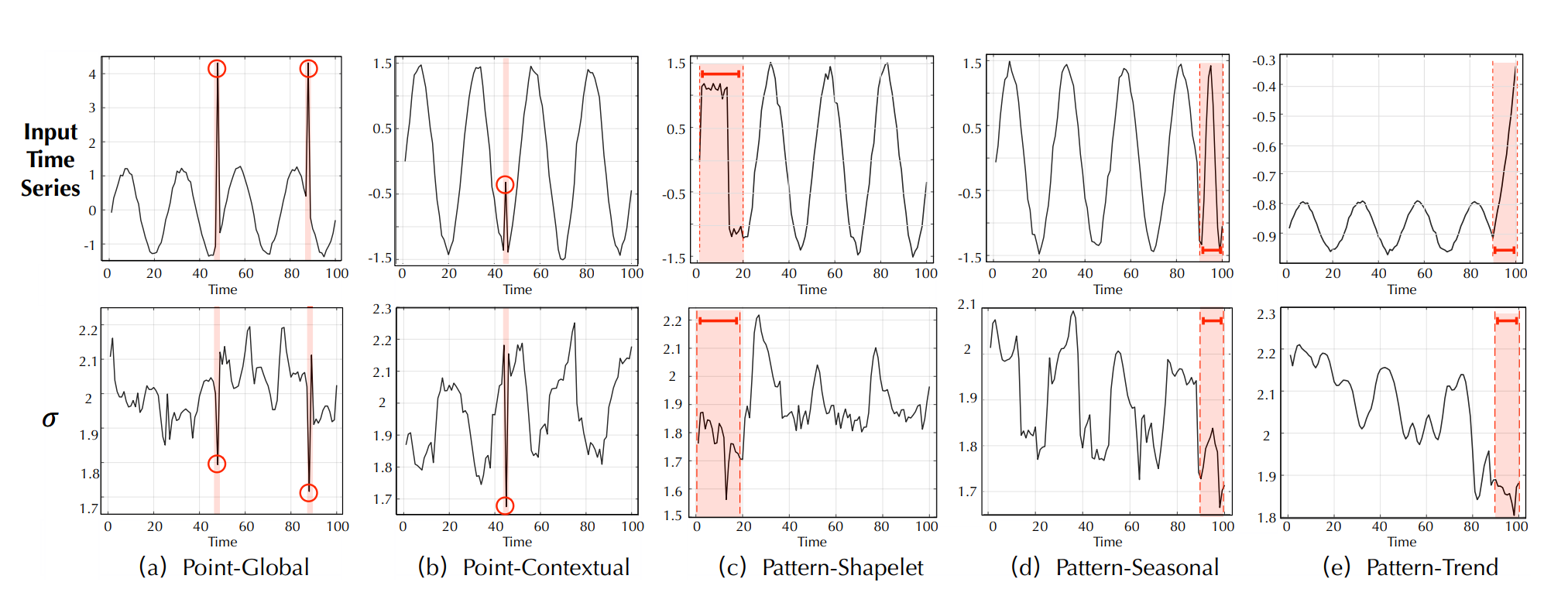
- 基于密度估计的方法,计算局部离群因子或则和局部连通性来检测异常
- 这些经典方法没有考虑时间序列信息,无法获取时间模式,只考虑到单个时间点,难以推广到不可见的真实场景
1.2、通过自监督任务训练一个RNN网络
- 通过预测来检测误差
- 虽然一定程度上解决了时序信息的问题,但对于复杂的时间模式,RNN无法学习到一个长序列的信息
- 这些经典方法没有考虑时间信息,难以推广到不可见的真实场景
- 对于复杂的时间模式,逐点表示信息较少,并且可以由正常时间点主导,使得异常难以区分。此外,重建或预测误差是逐点计算的,无法提供对时间背景的全面描述
1.3、基于关联建模的方法
- 对于多变量时间序列,可以看各个变量之间的关系是否变化来检测异常;但这种方法也只考虑到了逐点的信息
- 用子序列的关联来建模,找到异常;但这种无法捕获每个时间点与整个序列之间的细粒度时间关联
- 无法捕获每个时间点与整个序列之间的细粒度时间关联
二、思想概述-基于关联的准则
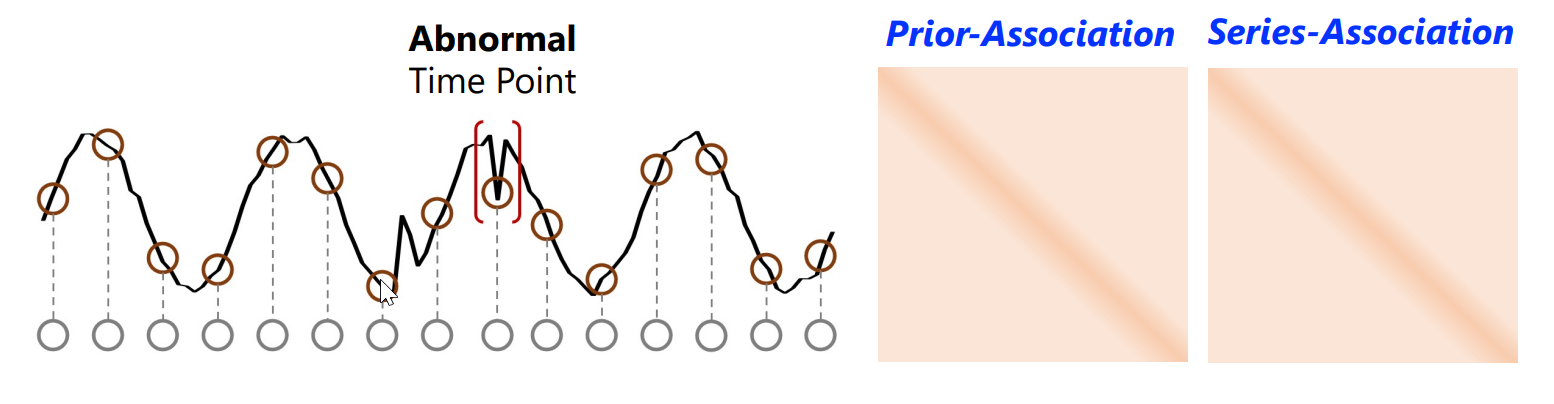
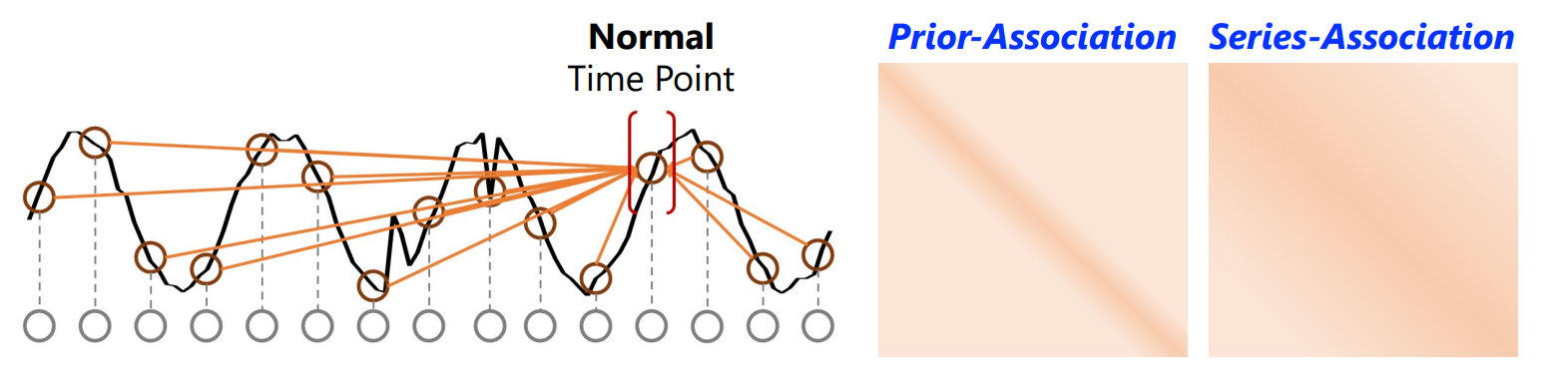
对每个时间点的先验关联和序列关联进行建模,由于异常点的先验关联和序列关联都差不多,因此异常的关联差异会比正常时间点小,在两个分支之间采用极大极小策略,放大关联差异的正常与异常可分辨性。
2.1、序列关联
序列关联:点与整个序列的关联;每个时间点的时间关联可以从自注意图中得到,该自注意图表现为其对所有时间点的关联权值沿时间维的分布。每个时间点的关联分布可以为时间上下文提供更有信息的描述。原始transformer中的自注意力权值
2.2、先验关联
先验关联:点与相邻序列的关联;异常的关联应集中在相邻的时间点,这些时间点由于连续性更容易包含相似的异常模式。这种邻接集中的归纳偏倚被称为先验关联;使用可学习的高斯核来表示每个时间点的邻接集中归纳偏差
2.3、关联差异
关联差异:每个时间点的先验关联和序列关联之间的距离来量化,称为关联差异
三、解决方法
3.1、模型整体架构
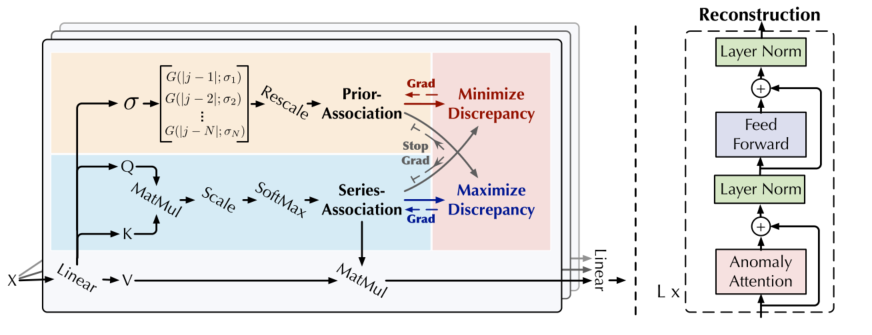
3.2、Anomaly-Attention
一个双分支结构的异常注意力机制(图一左),上半部用来计算先验关联,下半部是计算序列关联,即原始transformer得权重矩阵。Anomaly-Attention得公式表示如下公式一。
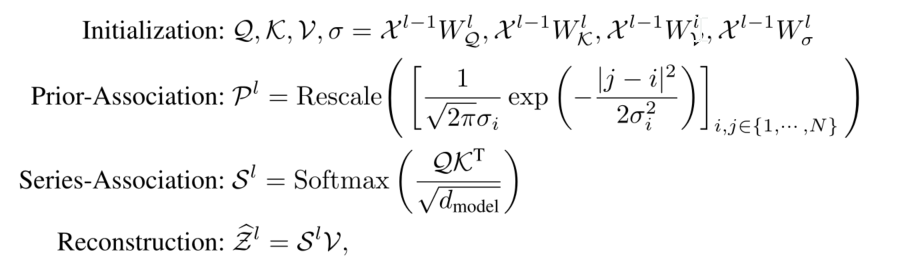
其中
σ
∈
R
N
×
1
σ∈R^{N×1}
σ∈RN×1为可学习的尺度参数
3.3、Association Discrepancy
算出了先验关联和序列关联,接下来就要算两者的关联差异;将关联差异形式化为先验关联和序列关联之间的对称KL散度,它表示这两个分布之间的信息增益。我们对多层的关联差异进行平均,将多层特征的关联组合成一个更有信息量的度量,公式如下:
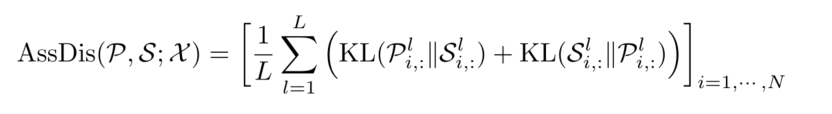
其中i代表时间点,L代表层数
3.4、Training Strategy
3.4.1、Vanilla Version
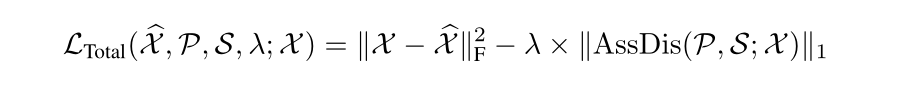
第一项是重构损失,让模型提取到的特征更准确;第二项是差异损失,让异常的可识别性更强
理解:要想损失越小,那么第二项就要越大,就意味着关联差异越大,就意味着先验关联和序列关联越大;要想先验关联和序列关联越大,那么就要引导序列关联更多地关注非相邻区域;因为这样做,对于异常点来说即便更多的关注了非邻域区域,但由于异常点很难与全局时间序列建立关系,所以先验关联和序列关联的差异还是很小;但对于正常点来说,多的关注了非邻域区域,那么就会使序列关联对角线的值变小,而对角线以外的值变大,这样先验关联和序列关联的差异就会变大。就会让异常的可识别性更强。
此种方法的缺点:
直接最大化第二项的差异损失,会让先验关联中可学习的尺度参数σ变为0,使先验关联变得毫无意义
3.4.2、Minimax Association Learning
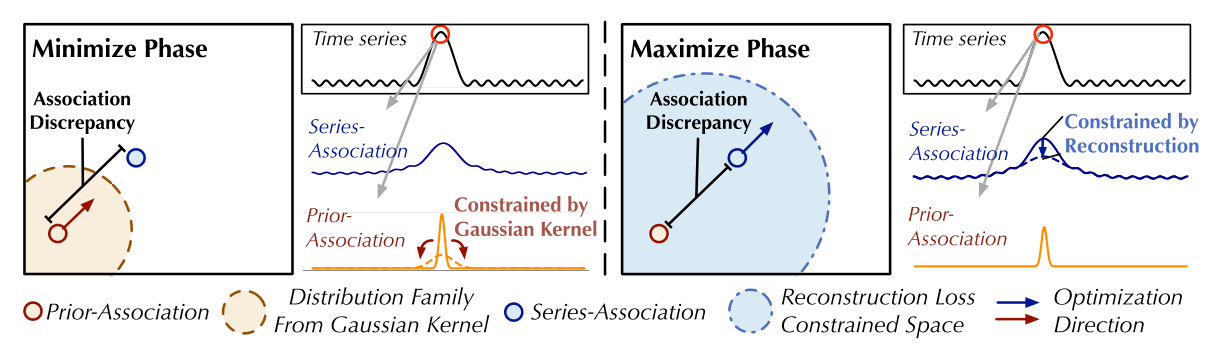
参考图一和图二,本文采用的训练策略分为两步
第一步:最小化阶段,固定序列关联,让先验关联尽可能的去贴近序列关联,这一过程将使先验关联适应不同的时间模式;
第二步:最大化阶段,固定先验关联,让序列关联尽可能的去远离序列关联,这个过程迫使序列关联更加关注非邻域区域;
由于先验关联在最小阶段近似于序列关联,因此最大阶段将对序列关联进行更强的约束,迫使时间点更加关注非相邻区域。在重构损失下,异常比正常时间点更难达到这一点,从而放大了关联差异的正常-异常可分辨性。
3.5、Association-based Anomaly Criterion
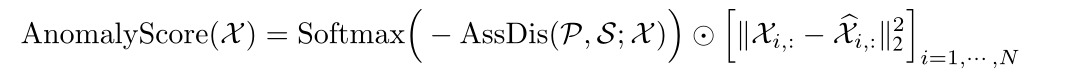
本文定义的异常判别准则如公式四所示:
第一项是关联差异,第二项是重构重构差异,上述的准则,对于异常点来说,不管怎样,异常分数都是大的:

四、试验分析
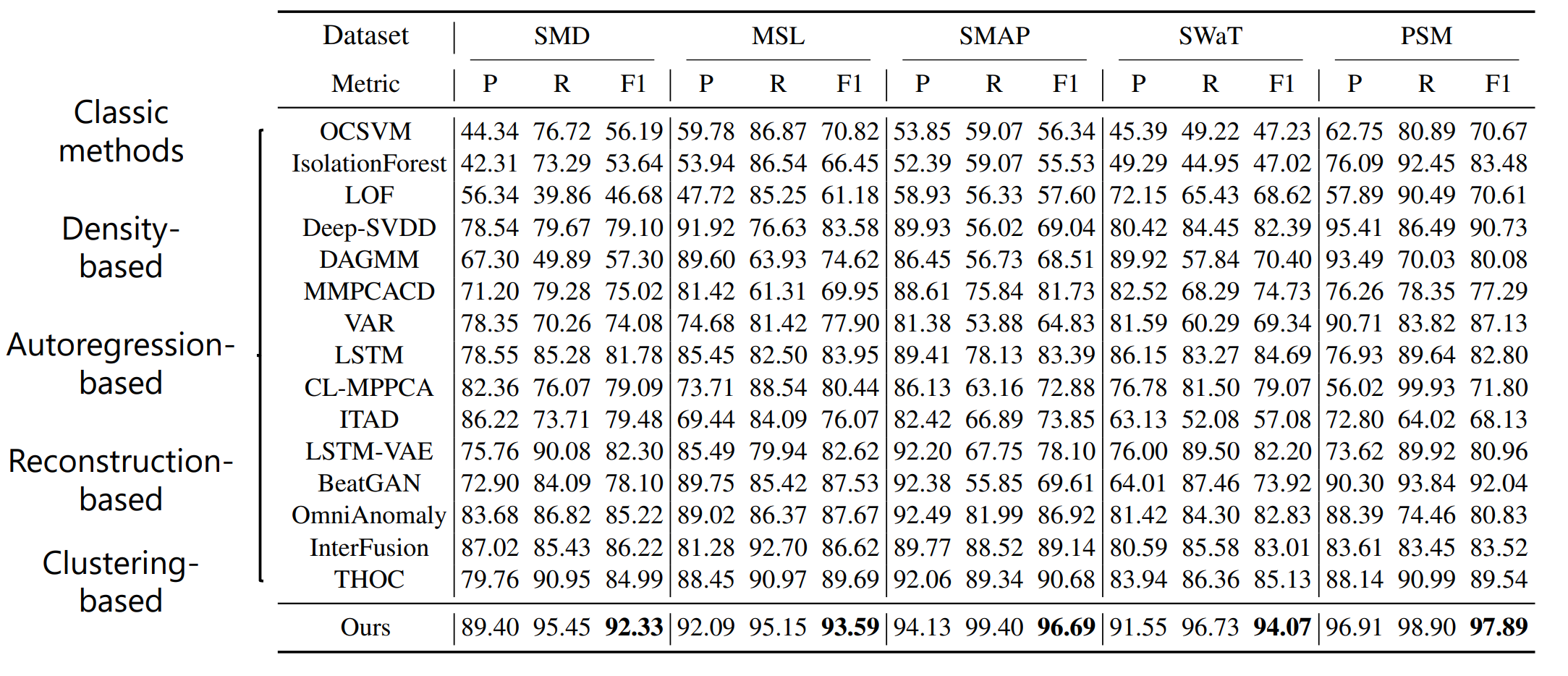
4.1、结果分析
采用了6个数据集,在18个模型上验证
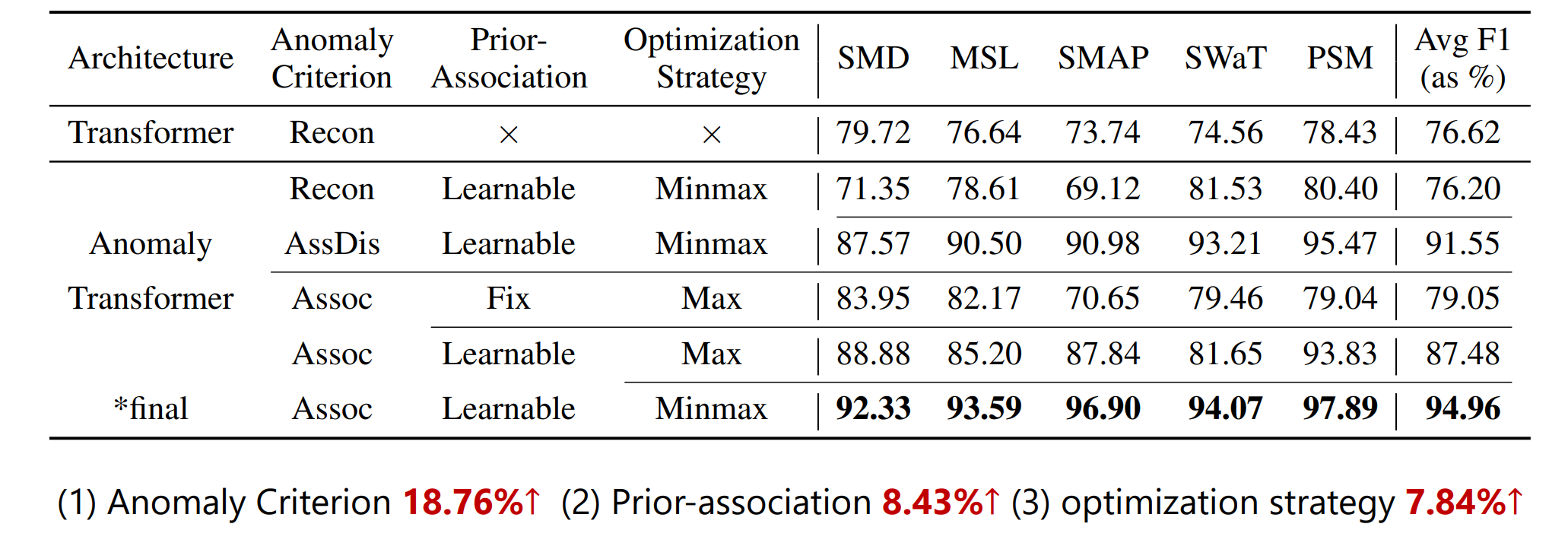
4.2、消融实验
4.3、异常判据的可视化
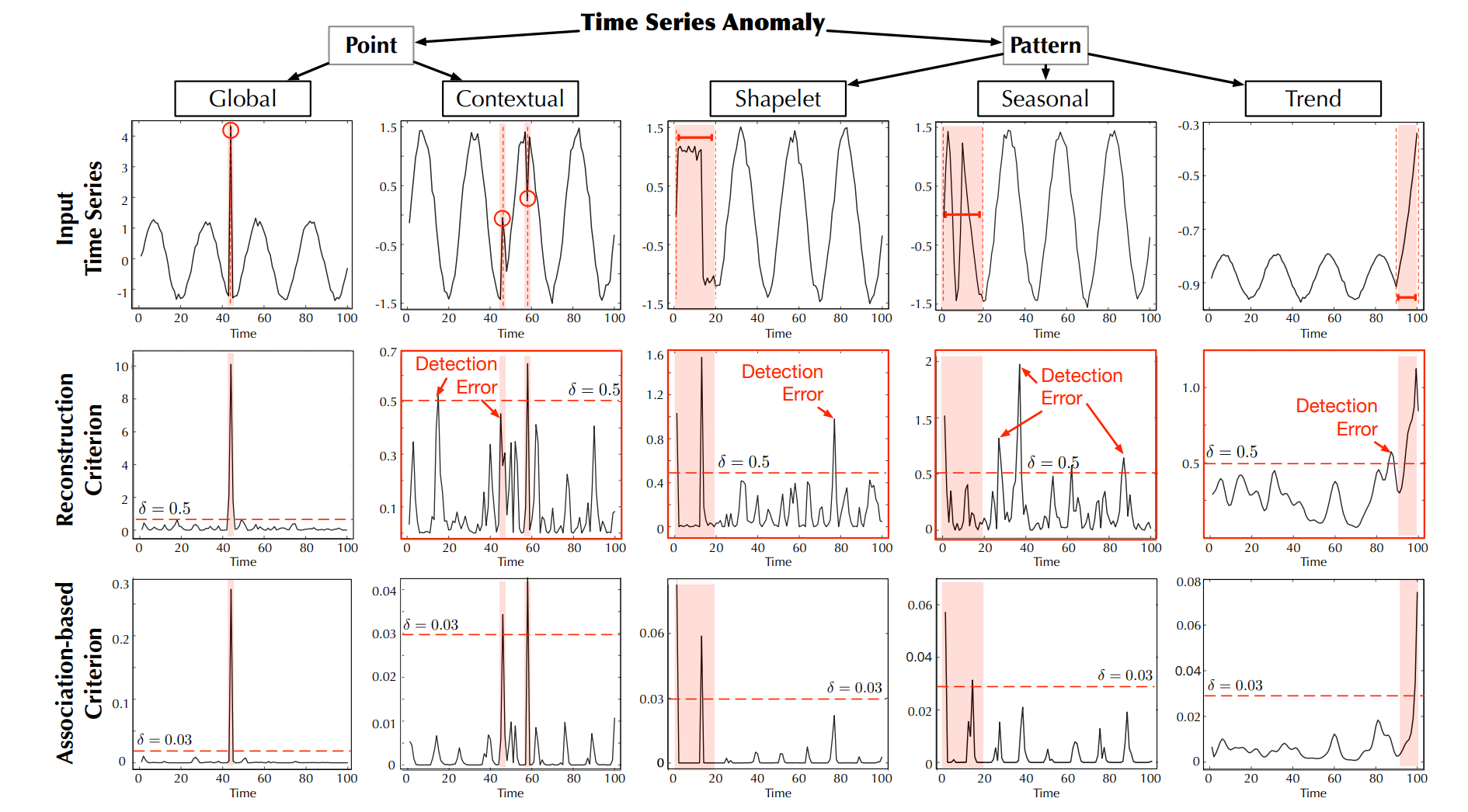
4.4、先验关联学习尺度的可视化