add 和 concat的区别
特征add的时候就是增加特征的信息量,特征concat的时候就是增加特征的数量,注重细节的时候使用add,注重特征数量的时候使用concat,
resnet用的add
densenet用的concat
RNN应用
一、关键字提取(many to one)
将一段话作为序列输入网络,输出只取最后一个状态,用它来表示这句话的关键字。
和文本分类没啥区别,评价、态度等。
二、手写数字识别(many to many)
输入与输出都是序列,一般是定长的,模型设计上,利用RNN单元在每一个时间步上的输出得到序列结果。这个是1:1的,先识别第一个字,在将第一个字输入到网络来识别第二个字,依次类推。
三 seq2seq
一般是在机器翻译的任务中出现,将一句中文翻译成英文,那么这句英文的长度有可能会比中文短,也有可能会比中文长,所以这时候输出的长度就不确定了,需要用序列到序列的模型来解决这个问题。
聊天机器人和问答系统也都是同样的原理,将句子输入,输出是根据前面的输入来得到.
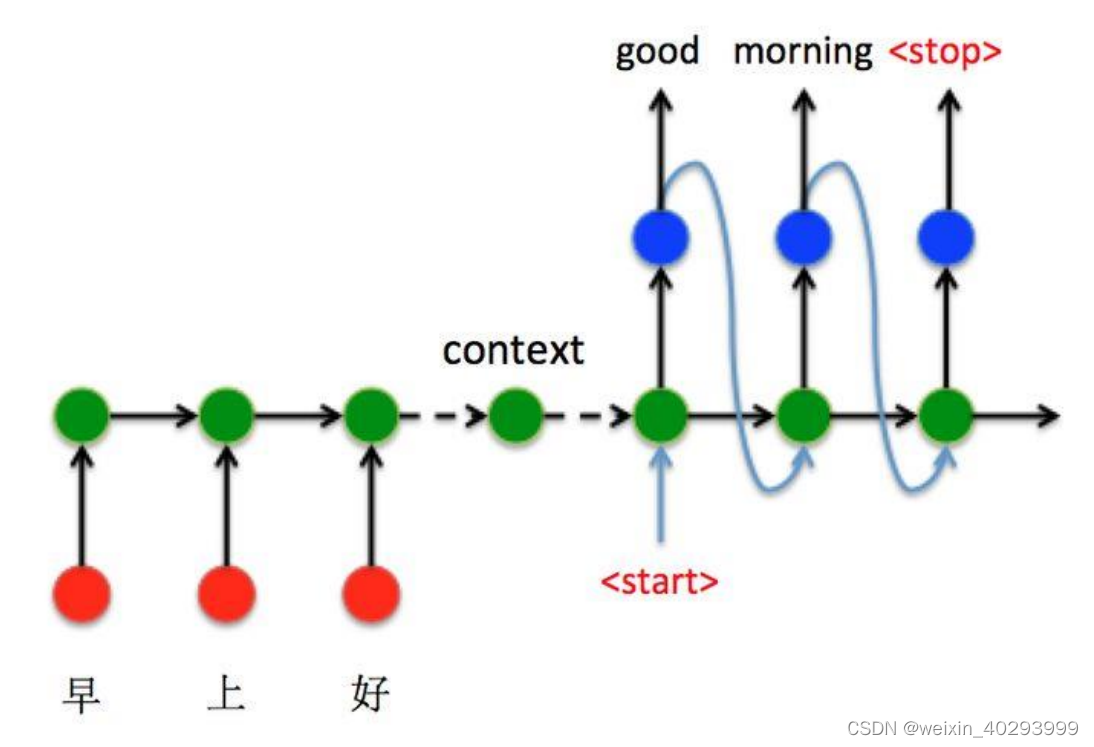
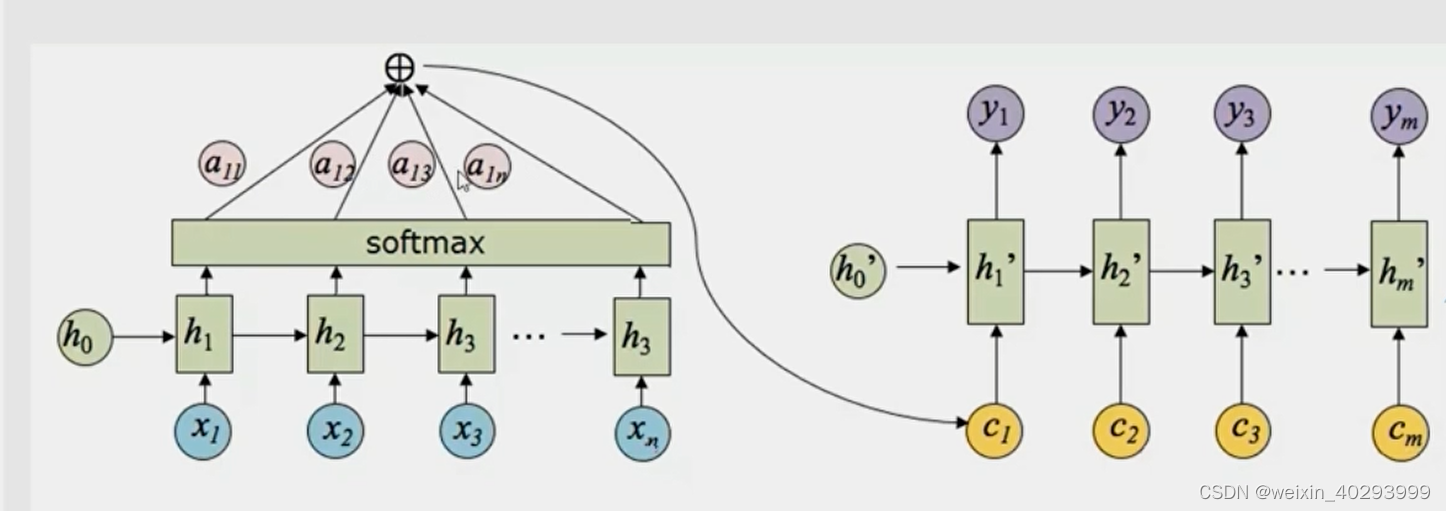
seq2seq模型结构如上图
Seq2Seq任务包含两部分:编码器(Encoder)和解码器(Decoder),编码器负责把文本序列转换成隐含表示,解码器负责把隐含表示还原成另一个文本序列。在这里,编码器和解码器的任务都能使用循环神经网络来实现。
注意中间的context(也叫作状态)
在Seq2Seq结构中,编码器Encoder把所有的输入序列都编码成一个统一的语义向量Context,然后再由解码器Decoder解码。在解码器Decoder解码的过程中,不断地将前一个的输出作为后一个时刻的输入,循环解码,直到输出停止符为止。
首先,解码器输入一个特殊的单词,即句子开头的单词对应的词向量(这个特殊的单词一般标记为<SOS>,即Start Of Sentence),输出第一个预测的单词。然后根据第一个预测的单词获取对应的词向量,进行第二个单词的预测,不断重复这个过程,直到到达最大预测长度或者预测得到另一个特殊单词(这个特殊的单词一般标记为<EOS>,即End Of Sentence),整个解码过程结束。Seq2seq解码过程对应的解码模型称为自回归模型(Autoregressive model)。
seq2seq的缺陷和注意力机制
看上图你也可以猜出来,对于很长的序列,RNN(包括LSTM和GRU)记不住啊。所以Attention Mechanism 注意力机制来解决。
注意力机制:就是通过引入一个神经网络,计算
编码器的输出对解码器贡献的权重,最后计算加权平均后编码器的输出,即上下文(Context)
通过在编码器的输出和下一步的输入中引入上下文的信息,最后达到让解码器的某一个特定的解码和编码器的一些输出关联起来,即对齐(Alignment)的效果。
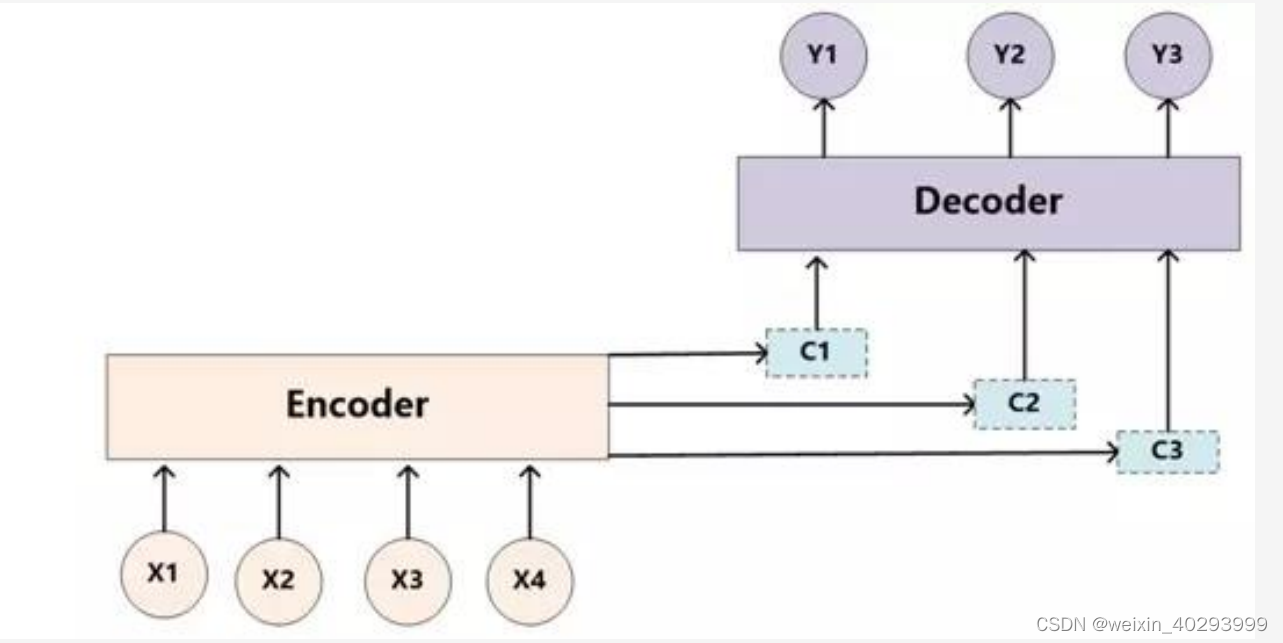
每一个输出都有一个上下文,每一个输入都会对每一个上下文有一个加权。
解码器每一步时间步的预测值都需要把原有的值都计算一遍。所以相较于LSTM,他的计算量是增加的。
最后将隐含层的结果和归一化后的结果在特征方向(最后一个维度)做拼接,线性变换,并使用Tanh函数作为激活函数输出最终上下文的值。
注意力层涉及编码器每一步输出的隐含状态,以及编码器的所有输出。
假设编码器输入序列的长度是S,解码器输出序列的长度是T,则总的计算量是SXT,因为解码过程中每个步骤都需要S次分数计算。
自注意力机制
自注意力机制和注意力机制完全不同,因为循环神经网络无法并行,有时序关系。
下一层只有在上一层计算完才进行,使得效率和优化都比较受限制。所以资助以来机制来了,attention is all your need. 不需要使用RNN类的循环神经网络。取而代之的是使用注意力机制来描述时间序列的上下文相关性,瑞阳的注意力机制称为自注意力机制。
它可以并行运算,没有先后顺序。
基本构造:
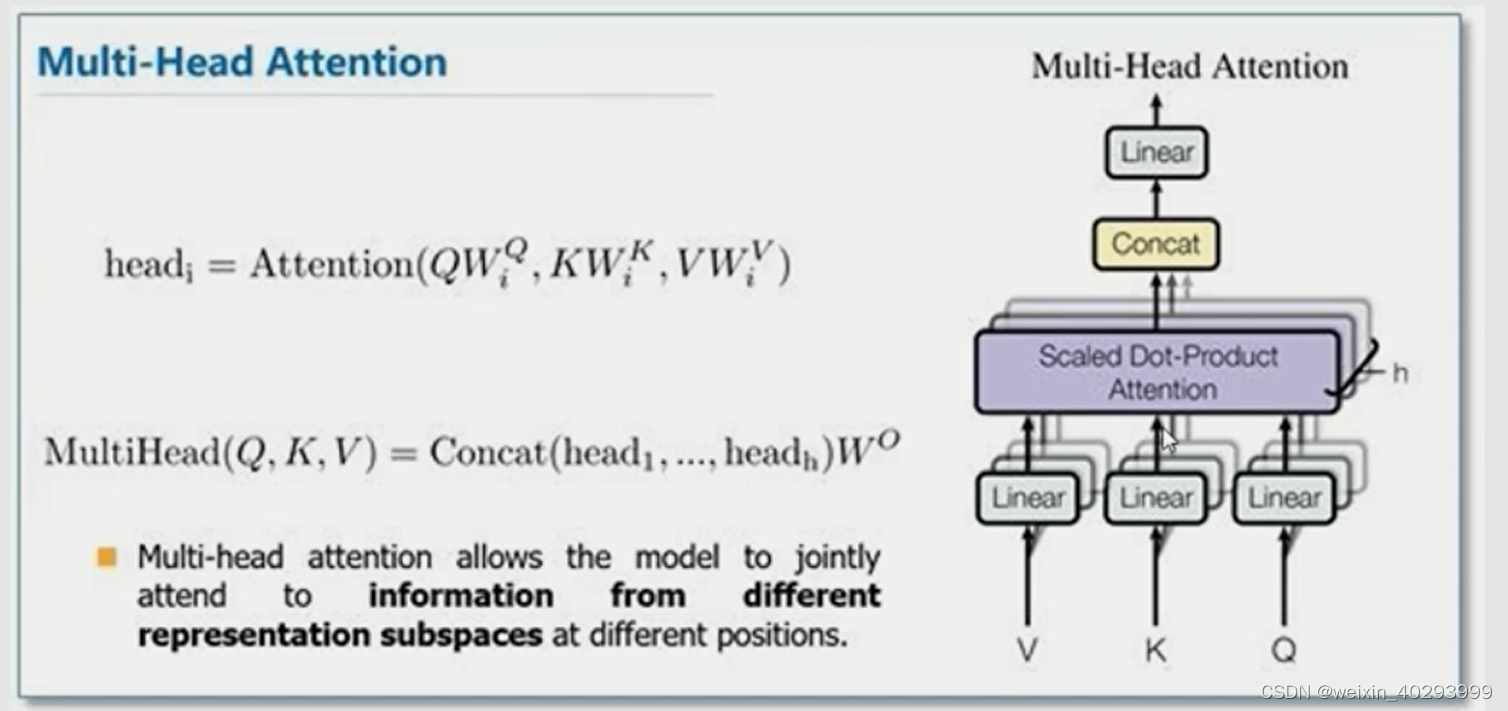
Query查询张量, K键,V值 实际上自问自答(自注意力)
Q,K,V三张量的形状为NTC: 第一维度为批次维度,第二维度是序列的时间长度,以及序列特征长度。
前两个张量(Q,K)的作用根据查询张量获取每个键张量的对应的分数,然后根据分数计算出对应的权重,用得到的权重乘以值(V)张量,并对值张量加权平均,最后输出结果。
实践中,使用多个并行的自注意力机制,(Multihead Attention),即使用多个注意力矩阵和多个权重对输入值进行加权平均,最后对加权平均的结果进行拼接。
为啥使用多头注意力机制?
单个注意力机制只能捕捉一种序列直接的关联(比如相邻单词)。
如果使用多个注意力机制,就能捕获多种序列直接的关联(比如,距离比较远的单词直接的相关性)。最后的拼接,通过结合多头注意力机制,就能更好的描述不同距离的单词之间的相互关系。(可以类别CNN中的多核来提取特征是类似的)
上边的介绍就引出了 Transformer
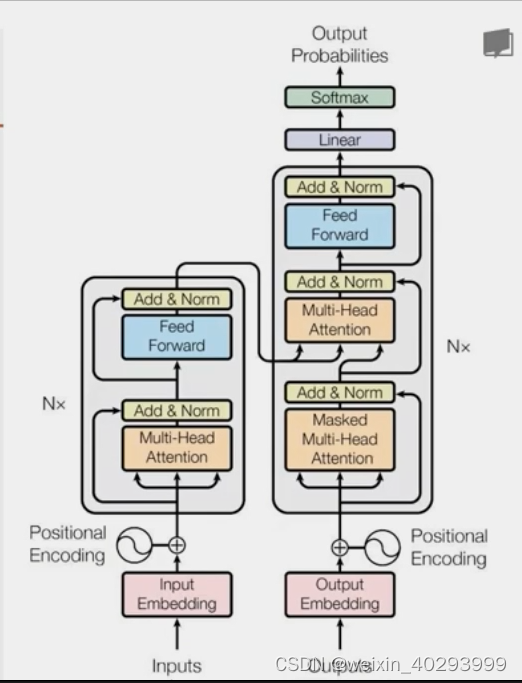
模型第一部分是词嵌入向量的生成,由于自注意力机制中不包含单词的顺序,如果要构建单词的词向量序列,需要引入单词的顺序相关的信息。
可使用周期性的函数来编码单词的顺序,比如使用不同周期的正弦函数和余弦函数来描述单词的顺序,这种位置编码方式的优点是能够编码任意长度的序列,但缺点是序列的词嵌入需要进行预先计算,需要消耗一定的计算时间。也可使用位置的嵌入