编码器部分:
- 由N个编码器层堆叠而成
- 每个编码器层由两个子层连接结构组成
- 第一个子层连接结构包括一个多头自注意力子层和规范化层以及一个残差连接。第二个子层连接结构包括一个前馈全连接子层和规范化层以及一个残差连接
掩码张量
什么是掩码张量
掩代表遮掩,码就是我们张量中的数值,它的尺寸不定,里面一般只有1和0的元素,代表位置被遮掩或者不被遮掩,至于是0位置被遮掩还是1位置被遮掩可以自定义,因此它的作用就是让另外一个张量中的一些数值被遮掩,也可以说被替换,它的表现形式是一个张量.
掩码张量的作用:
在transformer中,掩码张量的主要作用在应用attention时,有一些生成的attention张量中的值计算有可能已知了未来信息而得到的,未来信息被看到是因为训练时会把整个输出结果都一次性进行Embedding,但是理论上解码器的的输出却不是一次就能产生最终结果的,而是一次次通过上一次结果综合得出的,因此,未来的信息可能被提前利用.所以,我们会进行遮掩.
code
from inputs import Embeddings,PositionalEncoding
import numpy as np
import torch
import matplotlib.pyplot as plt
def subsequent_mask(size):
"""
生成向后遮掩的掩码张量,参数size是掩码张量最后两个维度的大小,
他们最好会形成一个方阵
"""
attn_shape = (1,size,size)
# 使用np.ones方法向这个形状中添加1元素,形成上三角阵
subsequent_mask = np.triu(np.ones(attn_shape),k=1).astype('uint8')
# 最后将numpy类型转化为torch中的tensor,内部做一个1-的操作,
# 在这个其实是做了一个三角阵的反转,subsequent_mask中的每个元素都会被1减
# 如果是0,subsequent_mask中的该位置由0变成1
# 如果是1,subsequent_mask中的该位置由1变成0
return torch.from_numpy(1-subsequent_mask)
 输出效果分析:
输出效果分析:
通过观察可视化方阵,黄色是1的部分,这里代表被遮掩,紫色代表没有被遮掩的信息,横坐标代表目标词汇的位置,纵坐标代表可查看的位置;
我们看到,在0的位置我们一看望过去都是黄色的,都被遮住了,1的位置一眼望过去还是黄色,说明第一次词还没有产生,从第二个位置看过去,就能看到位置1的词,其他位置看不到,以此类推.
注意力机制
原理理解
原来参考文章1这篇文章已经把注意力机制讲解的很清晰了,我就不罗嗦了,大家仔细研读,后续更多的是代码实现,还可以多参考几篇,文章2,文章3
下面我使用上面文章1的图进行简要理解什么是注意力机制:
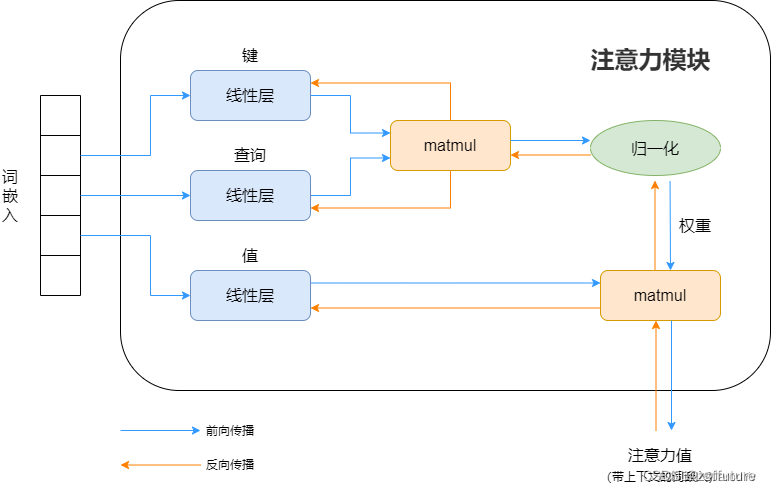
注意力说白了就是把一句话相关性的词找到,并使其更相关,弱化不相关的内容,和我们提炼一句话主要内容类似,但是如何能找到呢?现在知道的是每个词假如都是512维度的词嵌入向量构成(假如向量已经是训练好的,这个向量就是代表这个词),那么如何计算 一句话比较相关的词呢?因为每个token(词)都是一个向量表示,而向量计算相关性,直观的方法就是内积呀,所以使用内积就可以计算词与词的相关性了,虽然词宇词的相关性可以计算了,但是一句话我也不知道哪个词才是最重要的,如果不知道哪个词是重要的后续也是无法提取主要内容的,此时最直观的想法就是给词加个权重,越重要越相关,权重越大,理论上来说这个思路是可行的,但是应该怎么做呢?我现在唯一知道的就是每个词都由512维的向量构成,也知道可以计算每个词彼此之间的相似性,但是怎么加权重呢?我们可以想象数学领域的加权求和(概率论是期望),我们也可效仿,假如现在我计算第一个词和整个句子的其他词哪个最相关,最简单的做法就是把当前词的词向量和整个句子的词向量进行求内积即计算,如果和当前词的相关性很大,那计算出来的内积就会很大,同时希望权重也大,因此我们发现内积和希望的权重是正相关的,所以可以考虑直接把内积值作为权重即可,但整个权重是相对宇整个句子,权重值没有进行统一度量,因此做一个softmax就可以定性的确定比重问题。权重有了,那如何计算这个所谓的注意力呢?现在我们明确一下有哪些已知量,词嵌入向量、每个词和整个句子的其他词的权重,数学中的期望其实就相当于加权求和以此代表该物理量的平均结果,同理我们也可以求期望,这样就可以衡量当前词在所有词中的平均相关性程度,同时这个期望就是注意力值。上面的过程可以用下图表示:
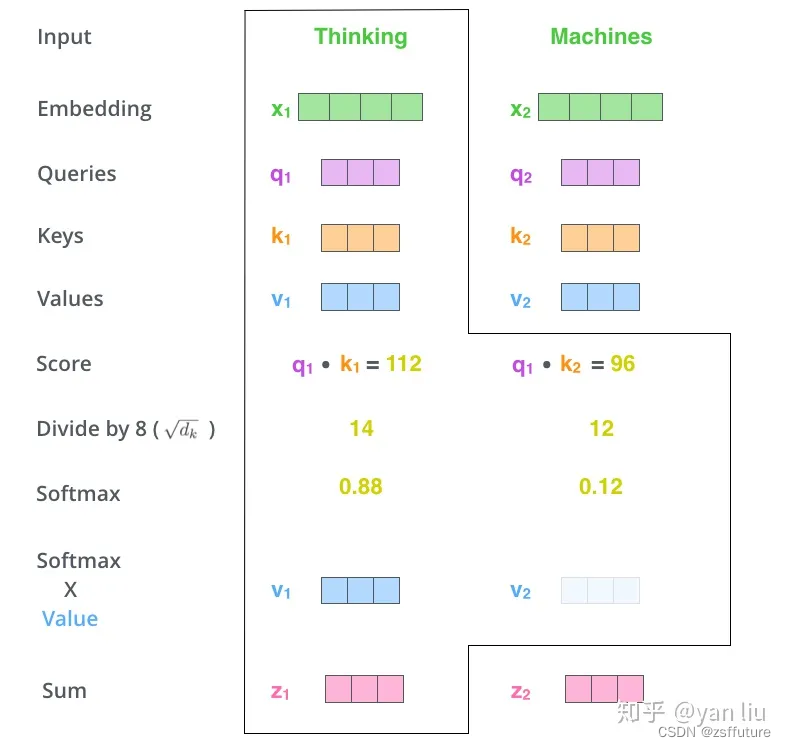
上面是我的一些理解,可能会有点问题,但是不影响深入理解,同时上面只是过程,但是如何训练呢?就需要设计权重了,但是过程还是那些,设计权重通过神经网络训练可以更好的辅助整个注意力值的计算。
概率论的期望:
在物理学中,期望可以被解释为系统在一系列可能的状态中的平均预期值。它表示了在多次实验或观测中,某个物理量的平均测量结果。
考虑一个物理系统,其中某个量(例如位置、速度、能量等)是随机变量。通过对该随机变量进行多次测量或观测,可以得到一系列可能的测量结果。期望值就是对这些测量结果的加权平均,其中每个测量结果的权重是其出现的概率
物理中的期望在描述量子力学中的测量结果、统计物理中的平均性质、热力学中的热力学量等方面起着重要的作用。它提供了确定物理系统的平均行为和预期结果的数学工具。
chatgpt的回答:
当我们谈到Transformer模型中的注意力机制中的Q(Query)、K(Key)、V(Value)时,可以使用以下类比来更形象地解释:
假设你是一位学生,而你的同学是输入序列中的其他元素。你们正在进行一项任务,需要相互交流和合作。在这个场景中,你可以将自己视为查询(Q),你的同学作为键(K)和值(V)。
- 查询(Q):你正在思考一个问题或需要某种信息。你提出了一个问题,希望得到其他同学的回答或关注。
- 键(K):你的同学们各自拥有自己的知识和经验。他们可以提供与你问题相关的信息。这些信息可以被认为是键(K),用来衡量其他同学与你的相关性。
- 值(V):你的同学们可以根据你的问题提供有用的答案或具体的信息。这些答案或信息可以被认为是值(V),提供给你作为参考或使用。
当你提出一个问题时,你会向你的同学们传达你的查询(Q)。然后,他们会根据自己的知识和经验,衡量他们与你的相关性,即键(K)。最后,他们会提供有用的答案或信息作为值(V),给予你参考。
在Transformer模型中,Q、K和V也是类似的。每个元素(例如词嵌入或编码器的隐藏状态)都有自己的查询(Q)、键(K)和值(V)。通过计算查询与键的相似度,可以确定每个元素对其他元素的关注程度。然后,使用这些关注权重来加权计算其他元素的值(V),以获得每个元素的上下文表示。
这个类比可以帮助我们理解注意力机制中的Q、K和V的作用,以及它们如何协同工作来建立元素之间的关联性
code

from inputs import Embeddings,PositionalEncoding
import numpy as np
import torch
import torch.nn.functional as F
import matplotlib.pyplot as plt
import math
def subsequent_mask(size):
"""
生成向后遮掩的掩码张量,参数size是掩码张量最后两个维度的大小,
他们最好会形成一个方阵
"""
attn_shape = (1,size,size)
# 使用np.ones方法向这个形状中添加1元素,形成上三角阵
subsequent_mask = np.triu(np.ones(attn_shape),k=1).astype('uint8')
# 最后将numpy类型转化为torch中的tensor,内部做一个1-的操作,
# 在这个其实是做了一个三角阵的反转,subsequent_mask中的每个元素都会被1减
# 如果是0,subsequent_mask中的该位置由0变成1
# 如果是1,subsequent_mask中的该位置由1变成0
return torch.from_numpy(1-subsequent_mask)
def attention(query, key, value, mask=None, dropout=None):
""" 注意力机制的实现,输入分别是query、key、value,mask
此时输入的query、key、value的形状应该是 batch * number_token * embeding
"""
# 获取词嵌入的维度
d_k = query.size(-1)
# 根据注意力公示,将query和key的转置相乘,然后乘上缩放系数得到评分,这里为什么需要转置?
# batch * number_token * embeding X batch * embeding * number_token = batch * number_token * number_token
# 结果是个方阵
scores = torch.matmul(query,key.transpose(-2,-1))/math.sqrt(d_k)
# 判断是否使用mask
if mask is not None:
scores = scores.masked_fill(mask==0,-1e9)
# scores 的最后一维进行softmax操作,为什么是最后一维?
# 因为scores是方阵,每行的所有列代表当前token和全体token的相似度值,
# 因此需要在列维度上进行softmax
p_attn = F.softmax(scores,dim=-1) # 这个就是最终的注意力张量
# 之后判断是否使用dropout 进行随机置0
if dropout is not None:
p_attn = dropout(p_attn)
# 最后,根据公式将p_attn与value张量相乘获得最终的query注意力表示,同时返回注意力张量
# 计算后的 维度是多少呢?
# batch * number_token * number_token X batch * number_token * embeding =
# batch * number_token * embeding
return torch.matmul(p_attn,value), p_attn
if __name__ == "__main__":
# 词嵌入
dim = 512
vocab =1000
emb = Embeddings(dim,vocab)
x = torch.LongTensor([[100,2,321,508],[321,234,456,324]])
embr =emb(x)
print("embr.shape = ",embr.shape)
# 位置编码
pe = PositionalEncoding(dim,0.1) # 位置向量的维度是20,dropout是0
pe_result = pe(embr)
print("pe_result.shape = ",pe_result.shape)
# 获取注意力值
query = key = value = pe_result
attn,p_attn = attention(query,key,value)
print("attn.shape = ",attn.shape)
print("p_attn.shape = ",p_attn.shape)
print("attn: ",attn)
print("p_attn: ",p_attn)
# 带mask
mask = torch.zeros(2,4,4)
attn,p_attn = attention(query,key,value,mask)
print("mask attn.shape = ",attn.shape)
print("mask p_attn.shape = ",p_attn.shape)
print("mask attn: ",attn)
print("mask p_attn: ",p_attn)
# size = 5
# sm = subsequent_mask(size)
# print("sm: \n",sm.data.numpy())
# plt.figure(figsize=(5,5))
# plt.imshow(subsequent_mask(20)[0])
# plt.waitforbuttonpress()
输出:
embr.shape = torch.Size([2, 4, 512])
pe_result.shape = torch.Size([2, 4, 512])
attn.shape = torch.Size([2, 4, 512])
p_attn.shape = torch.Size([2, 4, 4])
attn: tensor([[[ 11.8008, 30.6138, 3.5098, ..., 18.5594, -32.1164, -23.8748],
[ 39.1808, 0.0000, 16.5035, ..., 5.2685, -4.0213, -26.3394],
[ -5.4832, -11.0806, -0.9127, ..., -22.0353, 0.6908, 18.5235],
[ 25.6710, -14.6862, 39.7165, ..., 23.6078, -17.8417, 25.0513]],
[[ -6.4936, -9.5071, 0.0000, ..., -22.0353, 0.0000, 18.5235],
[ 13.3299, -13.5200, 29.1027, ..., -14.6726, 0.0000, 49.9336],
[ 32.0995, -8.8866, 39.6734, ..., -14.7124, 9.7955, 69.3002],
[ 18.8763, 10.9287, 17.8396, ..., 44.9964, -43.6573, -50.0163]]],
grad_fn=<UnsafeViewBackward0>)
p_attn: tensor([[[1., 0., 0., 0.],
[0., 1., 0., 0.],
[0., 0., 1., 0.],
[0., 0., 0., 1.]],
[[1., 0., 0., 0.],
[0., 1., 0., 0.],
[0., 0., 1., 0.],
[0., 0., 0., 1.]]], grad_fn=<SoftmaxBackward0>)
mask attn.shape = torch.Size([2, 4, 512])
mask p_attn.shape = torch.Size([2, 4, 4])
mask attn: tensor([[[ 17.7923, 1.2117, 14.7043, ..., 6.3501, -13.3221, -1.6598],
[ 17.7923, 1.2117, 14.7043, ..., 6.3501, -13.3221, -1.6598],
[ 17.7923, 1.2117, 14.7043, ..., 6.3501, -13.3221, -1.6598],
[ 17.7923, 1.2117, 14.7043, ..., 6.3501, -13.3221, -1.6598]],
[[ 14.4530, -5.2462, 21.6539, ..., -1.6060, -8.4654, 21.9353],
[ 14.4530, -5.2462, 21.6539, ..., -1.6060, -8.4654, 21.9353],
[ 14.4530, -5.2462, 21.6539, ..., -1.6060, -8.4654, 21.9353],
[ 14.4530, -5.2462, 21.6539, ..., -1.6060, -8.4654, 21.9353]]],
grad_fn=<UnsafeViewBackward0>)
mask p_attn: tensor([[[0.2500, 0.2500, 0.2500, 0.2500],
[0.2500, 0.2500, 0.2500, 0.2500],
[0.2500, 0.2500, 0.2500, 0.2500],
[0.2500, 0.2500, 0.2500, 0.2500]],
[[0.2500, 0.2500, 0.2500, 0.2500],
[0.2500, 0.2500, 0.2500, 0.2500],
[0.2500, 0.2500, 0.2500, 0.2500],
[0.2500, 0.2500, 0.2500, 0.2500]]], grad_fn=<SoftmaxBackward0>)多头注意力机制
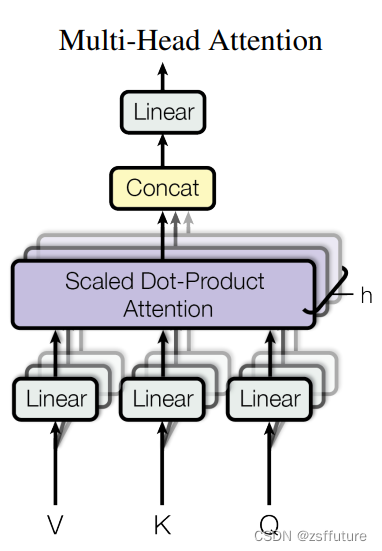
什么是多头注意力机制:
从多头注意力的结构图中,貌似这个所谓的多个头就是指多组线性变换层,其实并不是我只有使用了一组线性变化层,即三个变换张量对Q,K,V分别进行线性变换,这些变换不会改变原有张量的尺寸,因此每个变换矩阵都是方阵,得到输出结果后,多头的作用才开始显现,每个头开始从词义层面分割输出的张量,也就是每个头都想获得一组Q,K,V进行注意力机制的计算,但是句子中的每个词的表示只获得一部分,也就是只分割了最后一维的词嵌入向量,这就是所谓的多头,将每个头的获得的输入送到注意力机制中,就形成多头注意力机制.
多头注意力机制的作用:
这种结构设计能让每个注意力机制去优化每个词汇的不同特征部分,从而均衡同一种注意力机制可能产生的偏差,让词义拥有来自更多元的表达,实验表明可以从而提升模型效果
code
from inputs import Embeddings,PositionalEncoding
import numpy as np
import torch
import torch.nn.functional as F
import torch.nn as nn
import matplotlib.pyplot as plt
import math
import copy
def subsequent_mask(size):
"""
生成向后遮掩的掩码张量,参数size是掩码张量最后两个维度的大小,
他们最好会形成一个方阵
"""
attn_shape = (1,size,size)
# 使用np.ones方法向这个形状中添加1元素,形成上三角阵
subsequent_mask = np.triu(np.ones(attn_shape),k=1).astype('uint8')
# 最后将numpy类型转化为torch中的tensor,内部做一个1-的操作,
# 在这个其实是做了一个三角阵的反转,subsequent_mask中的每个元素都会被1减
# 如果是0,subsequent_mask中的该位置由0变成1
# 如果是1,subsequent_mask中的该位置由1变成0
return torch.from_numpy(1-subsequent_mask)
def attention(query, key, value, mask=None, dropout=None):
""" 注意力机制的实现,输入分别是query、key、value,mask
此时输入的query、key、value的形状应该是 batch * number_token * embeding
"""
# 获取词嵌入的维度
d_k = query.size(-1)
# 根据注意力公示,将query和key的转置相乘,然后乘上缩放系数得到评分,这里为什么需要转置?
# batch * number_token * embeding X batch * embeding * number_token = batch * number_token * number_token
# 结果是个方阵
scores = torch.matmul(query,key.transpose(-2,-1))/math.sqrt(d_k)
# 判断是否使用mask
if mask is not None:
scores = scores.masked_fill(mask==0,-1e9)
# scores 的最后一维进行softmax操作,为什么是最后一维?
# 因为scores是方阵,每行的所有列代表当前token和全体token的相似度值,
# 因此需要在列维度上进行softmax
p_attn = F.softmax(scores,dim=-1) # 这个就是最终的注意力张量
# 之后判断是否使用dropout 进行随机置0
if dropout is not None:
p_attn = dropout(p_attn)
# 最后,根据公式将p_attn与value张量相乘获得最终的query注意力表示,同时返回注意力张量
# 计算后的 维度是多少呢?
# batch * number_token * number_token X batch * number_token * embeding =
# batch * number_token * embeding
return torch.matmul(p_attn,value), p_attn
def clones(module, N):
"""用于生成相同网络层的克隆函数,N代表克隆的数量"""
return nn.ModuleList([copy.deepcopy(module) for _ in range(N)])
class MultiHeadedAttention(nn.Module):
def __init__(self, head,embedding_dim,dropout=0.1) -> None:
""" head 代表头的数量, embedding_dim 词嵌入的维度 """
super(MultiHeadedAttention,self).__init__()
# 因为多头是指对embedding的向量进行切分,因此头的数量需要整除embedding
assert embedding_dim % head == 0
# 计算每个头获得分割词向量维度d_k
self.d_k = embedding_dim // head
# 传入头数
self.head = head
# 获得线形层对象,因为线性层是不分割词向量的,同时需要保证线性层输出和词向量维度相同
# 因此线形层权重是方阵
self.linears = clones(nn.Linear(embedding_dim,embedding_dim),4)
# 注意力张量
self.attn = None
# dropout
self.dropout = nn.Dropout(p=dropout)
def forward(self,query,key,value,mask=None):
if mask is not None:
# 拓展维度,因为有多头了
mask = mask.unsqueeze(0)
batch_size = query.size(0)
# 输入先经过线形层,首先使用zip将网络层和输入数据连接一起,
# 模型的输出利用view和transpose进行维度和形状的变换
# (query,key,value) 分别对应一个线形层,经过线形层输出后,立刻对其进行切分,注意这里切分是对query经过线形层输出后进行切分,key经过线性层进行切分,value进行线性层进行切分,在这里才是多头的由来
query,key,value = \
[model(x).view(batch_size, -1, self.head,self.d_k).transpose(1,2) for model,x in zip(self.linears,(query,key,value))]
# 将每个头的输出传入注意力层
x,self.attn = attention(query,key,value,mask,self.dropout)
# 得到每个头的计算结果是4维张量,需要进行形状的转换
x = x.transpose(1,2).contiguous().view(batch_size,-1,self.head*self.d_k)
return self.linears[-1](x)
if __name__ == "__main__":
# 词嵌入
dim = 512
vocab =1000
emb = Embeddings(dim,vocab)
x = torch.LongTensor([[100,2,321,508],[321,234,456,324]])
embr =emb(x)
print("embr.shape = ",embr.shape)
# 位置编码
pe = PositionalEncoding(dim,0.1) # 位置向量的维度是20,dropout是0
pe_result = pe(embr)
print("pe_result.shape = ",pe_result.shape)
# 获取注意力值
# query = key = value = pe_result
# attn,p_attn = attention(query,key,value)
# print("attn.shape = ",attn.shape)
# print("p_attn.shape = ",p_attn.shape)
# print("attn: ",attn)
# print("p_attn: ",p_attn)
# # 带mask
# mask = torch.zeros(2,4,4)
# attn,p_attn = attention(query,key,value,mask)
# print("mask attn.shape = ",attn.shape)
# print("mask p_attn.shape = ",p_attn.shape)
# print("mask attn: ",attn)
# print("mask p_attn: ",p_attn)
# 多头注意力测试
head = 8
embedding_dim = 512
dropout = 0.2
query = key = value = pe_result
# mask 是给计算出来的点积矩阵使用的,这个矩阵是方阵,token
mask = torch.zeros(8,4,4)
mha = MultiHeadedAttention(head,embedding_dim,dropout)
mha_result = mha(query,key,value,mask)
print("mha_result.shape = ",mha_result)
print("mha_result: ",mha_result)
# size = 5
# sm = subsequent_mask(size)
# print("sm: \n",sm.data.numpy())
# plt.figure(figsize=(5,5))
# plt.imshow(subsequent_mask(20)[0])
# plt.waitforbuttonpress()
embr.shape = torch.Size([2, 4, 512])
pe_result.shape = torch.Size([2, 4, 512])
mha_result.shape = torch.Size([2, 4, 512])
mha_result: tensor([[[ 7.9783, -8.5943, 2.3163, ..., -6.6598, 2.4111, 1.9539],
[ 9.3484, -6.2983, 3.9020, ..., -10.6280, 1.6378, 2.5569],
[ 3.4545, 0.5589, 2.1463, ..., -3.8981, 0.9144, 1.5187],
[ 5.1963, -1.6135, 2.2151, ..., -5.7002, 0.2560, 6.7808]],
[[ -3.3818, -2.1619, -5.1541, ..., -4.1403, 6.8026, -8.9239],
[ -2.3160, 0.7179, -5.7809, ..., -5.7708, 8.4911, -11.9158],
[ 2.8323, -2.9125, -3.9379, ..., -0.9162, 9.5047, -6.0437],
[ 1.7311, -2.5926, -5.0537, ..., -3.0688, 6.8356, -4.3697]]],
grad_fn=<ViewBackward0>)