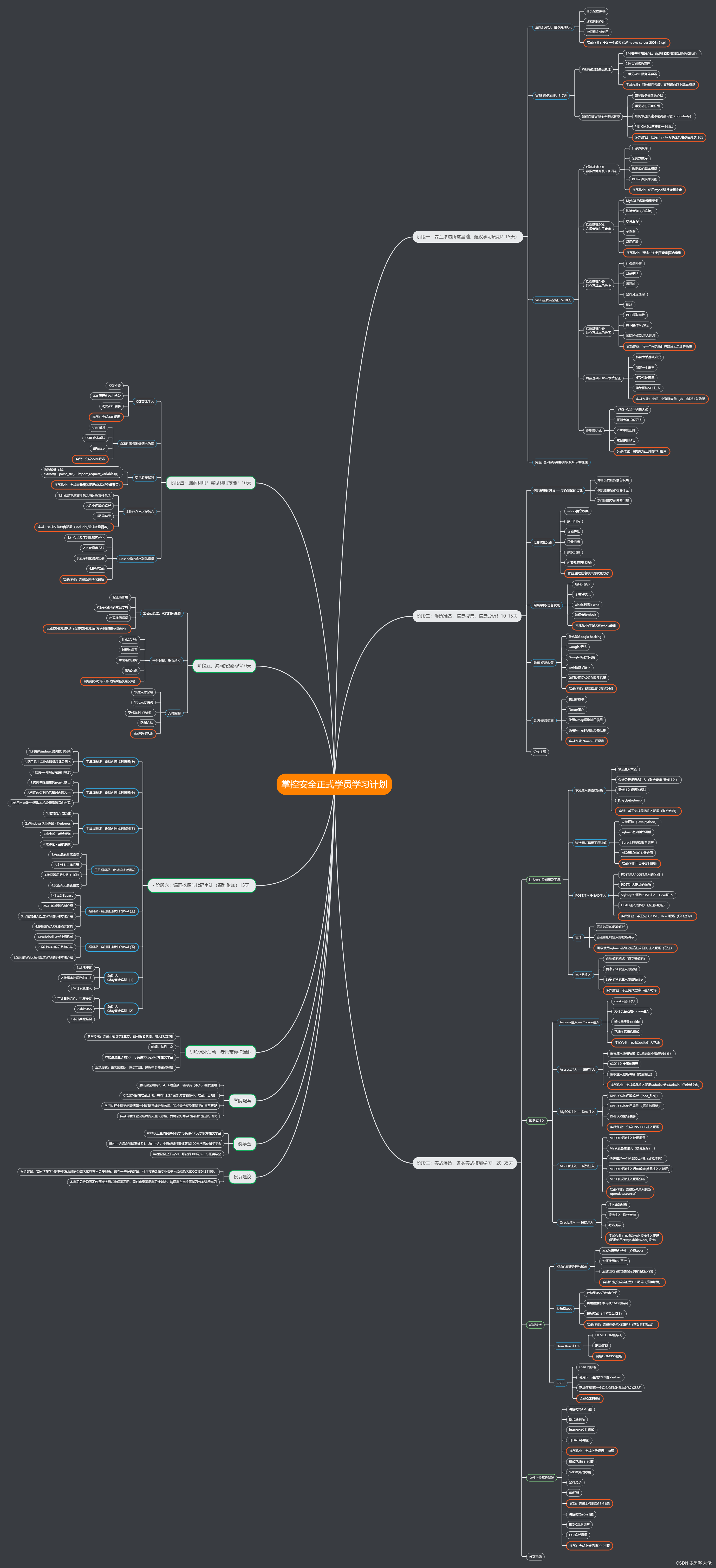
概述
AutoRound(https://github.com/intel/auto-round)实现了出色的量化性能,在W4G128上多数场景中接近无损压缩,适用于包括gemma-7B、Mistral-7b、Mixtral-8x7B-v0.1、Mixtral-8x7B-Instruct-v0.1、Phi2、LLAMA2等一系列流行模型。在尽量公正的评估中,AutoRound在W4G128、W4G-1、W3G128、W2G128的大多数场景中优于GPTQ,AWQ等方法
主要特性
- 广泛的模型支持:AutoRound可以量化多种模型族,涵盖了gemma、Mistral-7b、Mixtral-8x7B-v0.1、LLAMA1、LLAMAv2、GPT、QWEN1、OPT、Bloom、Falcon、GPT-LEO、StableLM-Base-Alpha、Dolly-v2、MPT、GPT-J-6b、ChatGLM2等。
- 导出灵活性:无缝导出量化模型到ITREX [1]格式,用于部署在Intel CPU上,以及导出到AutoGPTQ [2]格式,用于在Nvidia-GPU上运行。
- Tuning设备兼容性:支持tuning设备扩展到Intel CPU、Intel Guadi2和Nvidia-GPU。
- 数据集兼容性:AutoRound支持与Pile10k和MBPP数据集的校准,可轻松扩展以纳入其他所需的数据集。
示例
- 语言建模模型量化示例。
- 代码生成模型量化示例。
其他
- 已量化模型:已在Hugging Face发布几个预先量化的模型,由于公司内部审核,有些模型待发布
- 大量得准确性数据。
精度数据示例
gemma-7b
Install lm-eval-harness from source, and the git id 96d185fa6232a5ab685ba7c43e45d1dbb3bb906d, Install the latest AutoGPTQ from source first
lm_eval --model hf --model_args pretrained="Intel/gemma-7b-int4-inc",autogptq=True,gptq_use_triton=True --device cuda:0 --tasks lambada_openai,hellaswag,piqa,winogrande,truthfulqa_mc1,openbookqa,boolq,rte,arc_easy,arc_challenge,mmlu --batch_size 32
| Metric | FP16 | int4 |
|---|---|---|
| Avg. | 0.6239 | 0.6307 |
| mmlu | 0.6162 | 0.6147 |
| lambada_openai | 0.6751 | 0.7204 |
| hellaswag | 0.6047 | 0.5903 |
| winogrande | 0.7324 | 0.7514 |
| piqa | 0.7943 | 0.7949 |
| truthfulqa_mc1 | 0.3097 | 0.3011 |
| openbookqa | 0.3320 | 0.3400 |
| boolq | 0.8278 | 0.8269 |
| rte | 0.6534 | 0.7076 |
| arc_easy | 0.8178 | 0.7959 |
| arc_challenge | 0.4991 | 0.4940 |
Mixtral-8x7B-Instruct
| Metric | FP16 | INT4 |
|---|---|---|
| Avg. | 0.7000 | 0.6977 |
| mmlu | 0.6885 | 0.6824 |
| lambada_openai | 0.7718 | 0.7790 |
| hellaswag | 0.6767 | 0.6745 |
| winogrande | 0.7687 | 0.7719 |
| piqa | 0.8351 | 0.8335 |
| truthfulqa_mc1 | 0.4969 | 0.4884 |
| openbookqa | 0.3680 | 0.3720 |
| boolq | 0.8850 | 0.8783 |
| rte | 0.7184 | 0.7004 |
| arc_easy | 0.8699 | 0.8712 |
| arc_challenge | 0.6220 | 0.6229 |
phi-2
Since we encountered an issue evaluating this model with lm-eval, we opted to evaluate the qdq model instead. In our assessment, we found that its accuracy closely matches that of the real quantized model in most cases except for some small models like opt-125m.
| Metric | FP16 | INT4 qdq |
|---|---|---|
| Avg. | 0.6155 | 0.6163 |
| mmlu | 0.5448 | 0.5417 |
| lambada_openai | 0.6268 | 0.6225 |
| hellaswag | 0.5585 | 0.5498 |
| winogrande | 0.7530 | 0.7545 |
| piqa | 0.7867 | 0.7824 |
| truthfulqa_mc1 | 0.3133 | 0.3060 |
| openbookqa | 0.4000 | 0.4100 |
| boolq | 0.8339 | 0.8327 |
| rte | 0.6245 | 0.6643 |
| arc_easy | 0.7997 | 0.7955 |
| arc_challenge | 0.5290 | 0.5196 |
参考:
[1] Intel Extension for Transformers
[2] AutoGPTQ