承接上文:Transformer Encoder-Decoer 结构回顾
笔者以huggingface T5 transformer 对encoder-decoder 模型进行了简单的回顾。
由于笔者最近使用decoder-only模型时发现,其使用细节和encoder-decoder有着非常大的区别;而huggingface的接口为了实现统一化,很多接口的使用操作都是以encoder-decoder的用例为主(如T5),导致在使用hugging face运行decoder-only模型时(如GPT,LLaMA),会遇到很多反直觉的问题。
本篇进一步涉及decoder-only的模型,从技术细节上,简单列举一些和encoder-decoder模型使用上的区别。
以下讨论均以huggingface transformer接口为例。
1. 训练时input与output合并
对于encoder-decoder模型,我们需要把input和output 分别 喂给模型的encoder和decoder。也就是说,像T5这种模型,会有一个单独的encoder编码input的上下文信息,由decoder解码output和计算loss。简而言之,如果是encoder-decoder模型,我们 只把 output喂给decoder(用于计算loss,teacher forcing),这对于我们大多是人来说是符合直觉的。
但decoder-onyl模型,需要你手动地将input和output合并在一起,作为decoder的输入。因为,从逻辑上讲,对于decoder-only模型而言,它们并没有额外的encoder去编码input的上下文,所以需要把input作为“前文”,让decoder基于这一段“前文”,把“后文”的output预测出来(auto regressive)。因此,在训练时,input和output是合并在一起喂给decoder-only 模型的(input这段前文必须要有)。这对于大多数习惯了使用encoder-decoder的人来说,是很违反直觉的。
于此相对应的,decoder-only 模型计算loss时的“答案”(ground truth reference)也得是input和output的合并(因为计算loss的时候,输入token representation得和输出ground truth reference要对应)。而这样一来,decoder 的loss就既包含output,又会涉及input上的预测error。由于我们大多数情况下不希望去惩罚decoder模型在input上的error,一般的做法是,训练时我们只计算output上的loss ,即,把input token对应的ground truth全部设置为-100(cross entropy ignore idx)。
2. 测试时,手动提取output
encoder-decoder模型的输出就是很“纯粹”的output(模型的预测结果)
但decoder-only模型,在做inference的时候,模型的输出就会既包含output也包含input(因为input也喂给了decoder)
所以这种情况下,decoder-only 模型我们需要手动地把output给分离出来。
如下所示:
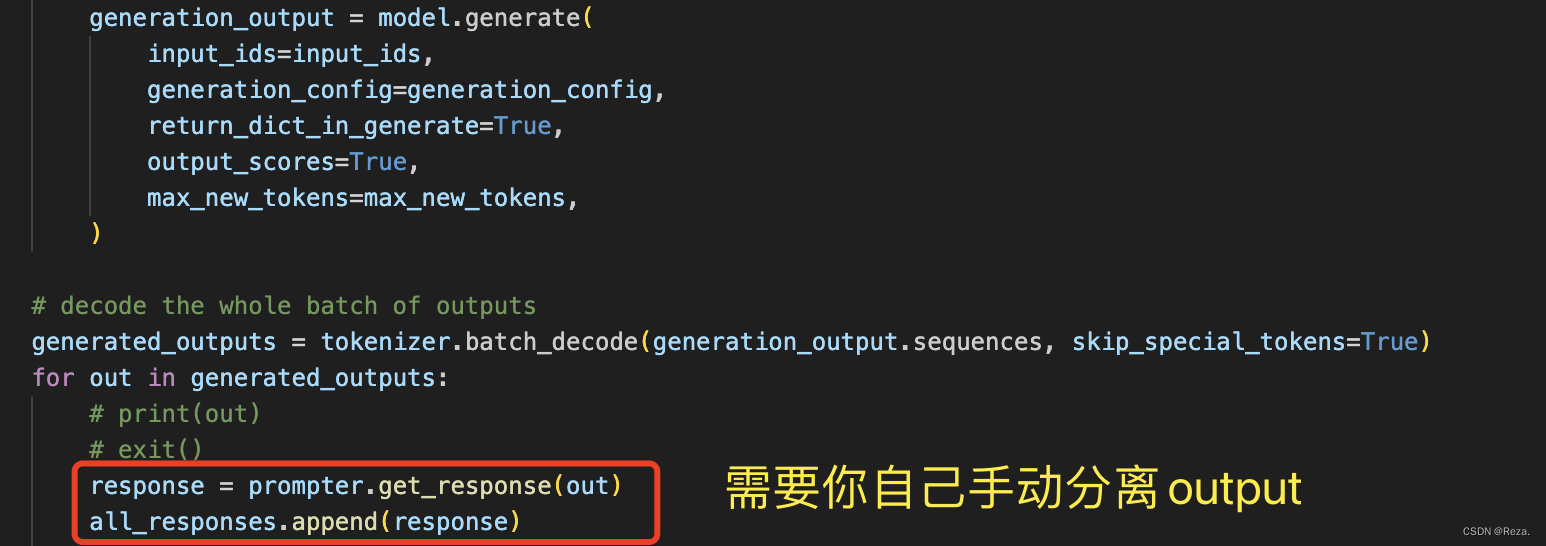
笔者也很无语,huggingface的 model.generate() 接口为什么不考虑一下,对于decoder-only模型,设置一个额外参数,能够自动提取output(用input token的数量就可以自动定位output,不难实现的)
3. batched inference的速度和准确度
如果想要批量地进行预测,简单的做法就是把一个batch的样本,进行tokenization之后,在序列末尾(右边)pad token,补足长度差异。这对于encoder-decoder 模型来说是适用的。
但是对于decoder-only模型,你需要在训练时,额外地将tokenizer的pad 位置设置为左边:

因为你一旦设置为默认的右边,模型在做inference时,一个batch的样本,所有pad token就都在序列末尾。而decoder only模型是auto regressive地生成新token的,最右边的pad token就很容易影响到模型生成的内容。
有人就会问,这个时候和encoder-decoder模型一样,用attention mask把那些pad tokens都遮掉,不就不会影响模型生成的内容了吗?
但是很遗憾,对于decoder-only模型,huggingface model.generate 接口并不支持输入attention mask(如下面官方api所描述):

所以你如果想batched inference,不得不在训练和测试的时候,把tokenizer的pad设置在左手边,以降低pad token对生成内容的影响;或者干脆设置batch size为1 。
经过笔者自己的实验,推理时
batch size==1能够显著提升推理准确度
以下为笔者测试的性能表现排序:
- batch size 为1 (完全没有pad token的影响),性能最好
- batch size不为1,pad token在左侧(pad token影响降低,但还是会损伤推理性能),在部分任务上,性能降低较为明显
- batch size不为1,pad token在右侧(pad token对大量的样本的预测产生极大干扰,模型最后的输出基本都是乱码),性能接近于0
总之,当前huggingface的生成接口对于decoder-only模型的支持度并不是非常高,decoder-only模型推理的速度和精度,以及接口使用的便捷程度,都会逊于encoder-decoder模型。
下面是GPT-4对于为何decoder-only模型做推理时不需要attention mask(最后一句话是亮点。。。):
The instruction from the Hugging Face Transformers documentation regarding the use of
input_idsfor decoder-only models during generation (like GPT-2, GPT-3) stems from the typical use case and architecture of these models.
Whyinput_ids?
Decoder-only models like GPT-2 or GPT-3 are designed to generate text sequentially. When generating text, the model uses its previously generated tokens as context to generate the next token. Since these models are autoregressive, they generate one token at a time, and the sequence of generated tokens grows until it reaches a stopping condition (like themax_lengthoreos_token_id). During this process, the only necessity is to know which tokens have been generated (encoded asinput_ids), so the model knows the context based on which it should generate the subsequent token(s).
Aboutattention_mask
While it’s true that attention masks are used to prevent the model from attending to certain positions within the input sequence (for example, padding tokens in a batched input scenario), during the generation phase, the need to specify anattention_maskexplicitly is not as critical as during training or evaluation. This is because, during generation, the model is focusing on the tokens it has already generated and the positions it needs to fill next – all of which are relevant and none should be masked out.
That said, for certain generation scenarios or model configurations, you might want to control the attention mechanism explicitly. The Hugging Face Transformers library does allow for passing additional arguments likeattention_maskin some contexts, but for the default use case of generating text with decoder-only models, including theattention_maskis not necessary.
Batched Inference
For batched inference,input_idsare necessary to understand the sequence (or sequences) from which to start generating text. If the sequences within a batch have different lengths, padding might be necessary to shape the input tensor appropriately. In such cases, anattention_maskbecomes relevant because it allows the model to distinguish between the actual content and the padding. Therefore, while the generation call as you’ve shown doesn’t explicitly mentionattention_mask, depending on the specifics of your use case and the model’s implementation, you might still need or want to provide it to ensure proper handling of batched inputs.
其他待补充
。。。
总结
总而言之,个人认为 huggingface目前的模型接口,对于decoder-only模型的使用并不是很友好。在使用过程中需要注意很多细节,不然会遇到许多问题,而这些问题,encoder-decoder模型是完全不会有的。
参考:
- 官方接口
- alpaca-lora