Taming Transformers for High-Resolution Image Synthesis
- 记录
- 前置知识
- Abstract
- Introduction
- Related Work
- Method
- Learning an Effective Codebook of Image Constituents for Use in Transformers
- Learning the Composition of Images with Transformers
- 条件合成
- 合成高分辨率图像
- 实验
- Attention Is All You Need in the Latent Space
- A Unified Model for Image Synthesis Tasks
- 高分辨率合成
- Building Context-Rich Vocabularies、
- Benchmarking Image Synthesis Results
- Class-Conditional Synthesis on ImageNet
- 结论
- 附录
- paper:https://arxiv.org/abs/2012.09841
- code:https://github.com/CompVis/taming-transformers.git
- affiliation:德国海德堡大学图像处理实验室 CompVis
- project:https://compvis.github.io/taming-transformers
记录
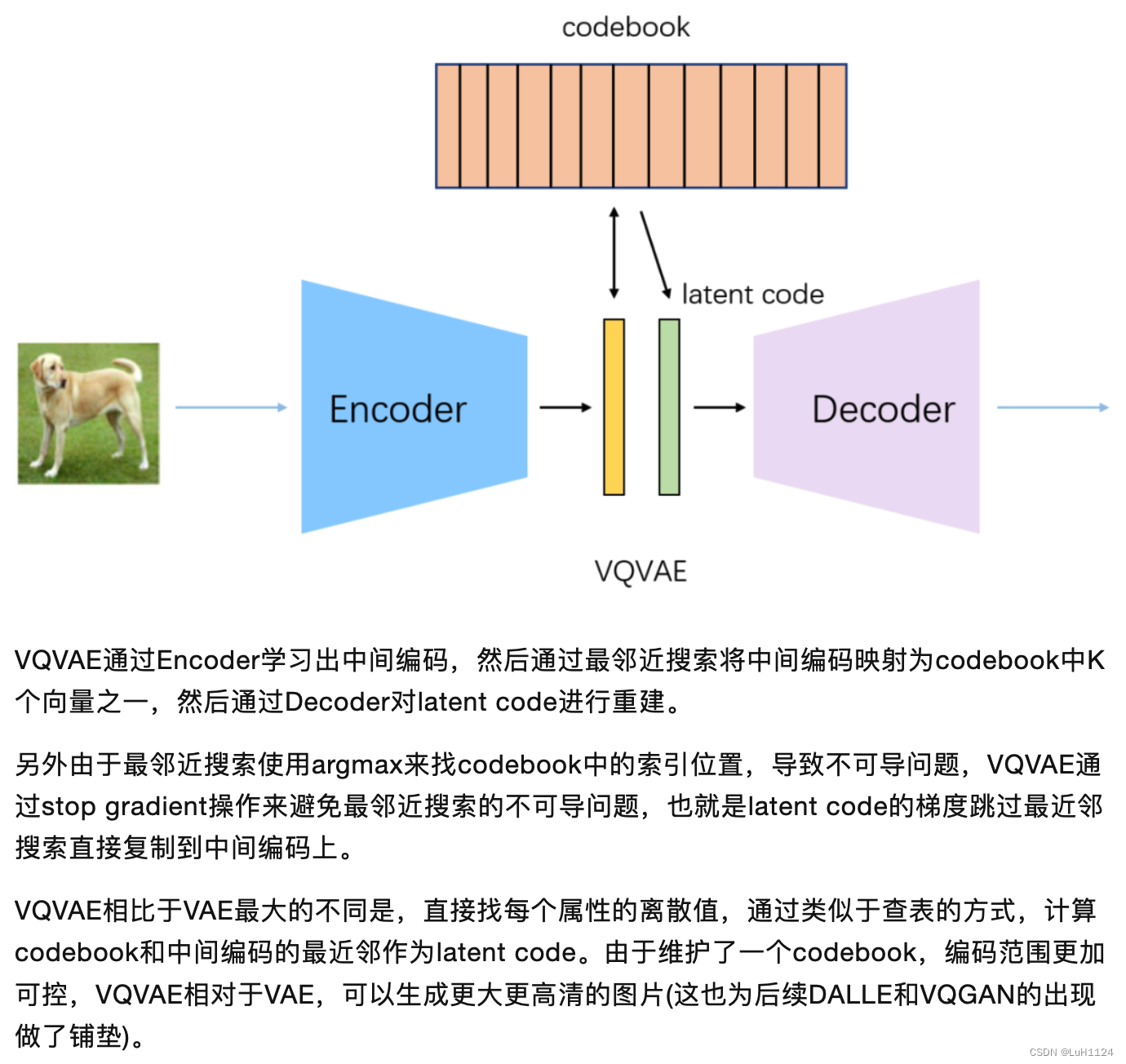
简单来说就是使用VQGAN对图像进行压缩为离散的序列(存储于codebook),在codebook空间训练了一个基于transformer的自回归模型。
充分利用了CNN对于图像的编码能力和局部感知,再通过transformer建模每个局部的全局关系。减少了transformer随图片分辨率增长导致的平方倍内存消耗和计算需求。

前置知识
Abstract
- 旨在学习序列数据的远程交互,transformer继续在各种任务中展示最先进的结果。与 CNN 相比,它们不包含优先考虑局部交互的归纳偏差。这使得它们具有表现力,但对于长序列(如高分辨率图像)也在计算上是不可行的。
- 我们演示了如何将cnn的归纳偏差与变压器的表达能力相结合,使它们能够建模,从而合成高分辨率图像。
- 我们展示了如何 (i) 使用 CNN 来学习图像成分的上下文丰富的词汇
- 进而 (ii) 利用transformer有效地对它们在高分辨率图像中的组成进行建模。
- 我们的方法可以很容易地应用于条件合成任务,其中非空间信息,如对象类和空间信息,如分割,都可以控制生成的图像。特别是,我们展示了使用变压器语义引导合成百万像素图像的第一个结果。
Introduction
- transformer表达能力的提高伴随着对计算资源的提高,这在合成百万像素图像上带来了挑战
- 作者假设low level图像结构可以用CNN架构很好地描述,但在更高语义层面上失效。此外,还提到了CNN表现出强烈的局部偏见和空间不变性的偏见,这使它们在需要更全面理解输入时变得无效。
- 我们获得有效和富有表现力的模型的关键见解是,将卷积和转换器架构一起建模我们的视觉世界的组合性质
- 使用CNN来有效地学习上下文丰富的视觉部分的codebook,然后Transformer学习它们的全局组合模型
- 利用对抗性方法来确保局部部分的字典捕获了感知上重要的局部结构,以减轻使用 Transformer 架构对低级统计数据进行建模的需要
- 允许变压器专注于其独特的优势来建模远程关系
- 可通过调节有关所需对象类或空间布局的信息来直接控制生成的图像
- 最后,实验表明,我们的方法优于以前基于codebook的基于卷积架构的最先进方法,保留了Transformer的优势
Related Work
- Transformer在序列化任务中考虑全局取得了SOTA,但开销随着序列的长度线性增长,面对图像力不从心
- CNN考虑局部,产生严重的归纳偏执,本文结合Transformer和CNN的优势进行建模
- 介绍了类似的二阶段方法,首先学习数据的编码,然后在第二阶段学习这种编码的概率模型
Method
高分辨率图像合成需要一个模型来理解图像的全局组合,使其能够生成局部逼真和全局一致的模式。
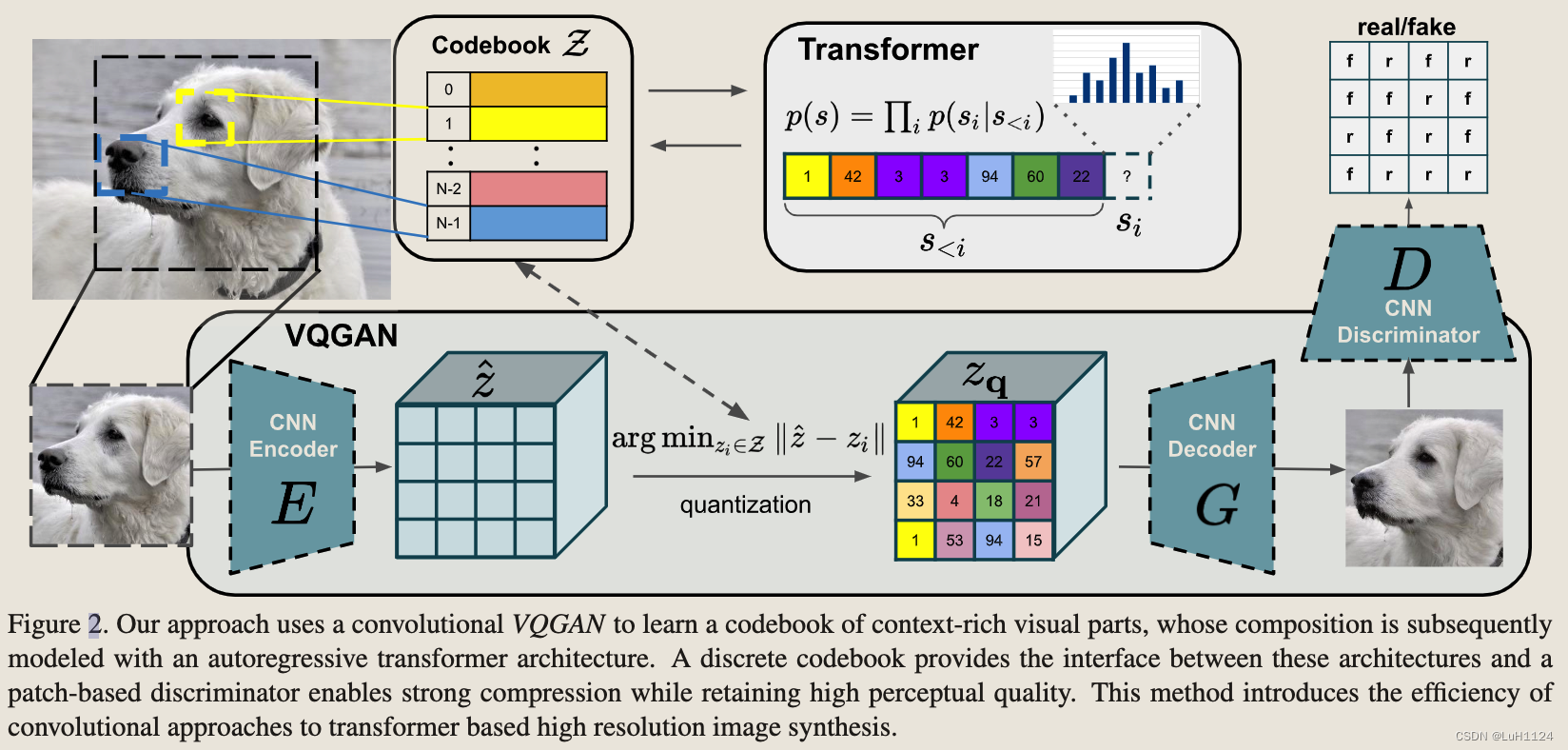
我们的方法使用卷积神经网络VQGAN来学习上下文丰富的视觉部分的码本,其组合随后使用自回归transormer架构建模。
离散码本提供了这些体系结构和基于补丁的鉴别器之间的接口,可以在保持高感知质量的同时实现强大的压缩。
该方法引入CNN提高了基于transormer的高分辨率图像合成的效率。
Learning an Effective Codebook of Image Constituents for Use in Transformers
- 直观理解,提前设定了一个长度为
n
z
n_z
nz,数量为
K
K
K的codebook存储离散编码;对输入图像(HW3)使用VQGAN的encoder得到当前的编码
z
^
\hat{z}
z^(hw
n
z
n_z
nz);根据最近邻搜索codebook中的离散编码并替换得到
z
q
z_q
zq(hw
n
z
n_z
nz),经过decoder得到输出
x
^
\hat{x}
x^。
note: 实际替换的公式: z q = z + ( z q − z ) . d e t a c h ( ) z_q = z + (z_q-z).detach() zq=z+(zq−z).detach(),将解码器输入 z q z_q zq的梯度复制到编码器输出 z z z。
loss定义为:
L V Q ( E , G , Z ) = ∥ x − x ^ ∥ 2 + ∥ sg [ E ( x ) ] − z q ∥ 2 2 + β ∥ sg [ z q ] − E ( x ) ∥ 2 2 \begin{aligned} \mathcal{L}_{\mathrm{VQ}}(E, G, \mathcal{Z})=\|x-\hat{x}\|^{2} & +\left\|\operatorname{sg}[E(x)]-z_{\mathbf{q}}\right\|_{2}^{2} \\ & +\beta\left\|\operatorname{sg}\left[z_{\mathbf{q}}\right]-E(x)\right\|_{2}^{2} \end{aligned} LVQ(E,G,Z)=∥x−x^∥2+∥sg[E(x)]−zq∥22+β∥sg[zq]−E(x)∥22
- 第一项约束图像层面的重建loss
- 第二项根据VAVAEVQ 目标使用 l2 误差将嵌入向量 z_q 移动到编码器输出z
- 第三项由于嵌入空间的体积是无量纲的,如果嵌入 z q z_q zq不像编码器参数那样快地训练,它可以任意增长。为了确保编码器嵌入并且其输出不会增长,我们添加了一个承诺损失。(我理解是限制编码器的更新速度,确保每一次encode的编码能够找到codebook中的编码,还望大佬请教)
解码器仅优化第一个损失项,编码器优化第一个和最后一个损失项,嵌入 z q z_q zq由中间损失项优化。
- 为了获得感知丰富的codebook,添加了GAN对抗性loss和感知LPIPSloss来替换一般的mse重建loss
ganloss的权重自适应:
L G A N ( { E , G , Z } , D ) = [ log D ( x ) + log ( 1 − D ( x ^ ) ) ] \mathcal{L}_{\mathrm{GAN}}(\{E, G, \mathcal{Z}\}, D)=[\log D(x)+\log (1-D(\hat{x}))] LGAN({E,G,Z},D)=[logD(x)+log(1−D(x^))]
Q ∗ = arg min E , G , Z max D E x ∼ p ( x ) [ L V Q ( E , G , Z ) + λ L G A N ( { E , G , Z } , D ) ] \begin{aligned} \mathcal{Q}^{*}=\underset{E, G, \mathcal{Z}}{\arg \min } \max _{D} \mathbb{E}_{x \sim p(x)}\left[\mathcal{L}_{\mathrm{VQ}}(E, G, \mathcal{Z})\right. \\ \left.+\lambda \mathcal{L}_{\mathrm{GAN}}(\{E, G, \mathcal{Z}\}, D)\right] \end{aligned} Q∗=E,G,ZargminDmaxEx∼p(x)[LVQ(E,G,Z)+λLGAN({E,G,Z},D)]
λ = ∇ G L [ L r e c ] ∇ G L [ L G A N ] + δ \lambda=\frac{\nabla_{G_{L}}\left[\mathcal{L}_{\mathrm{rec}}\right]}{\nabla_{G_{L}}\left[\mathcal{L}_{\mathrm{GAN}}\right]+\delta} λ=∇GL[LGAN]+δ∇GL[Lrec]
Learning the Composition of Images with Transformers
图像经过encoder之后的编码在codebook中对应的索引假设为s。在选择索引的某种排序后(对应着图像encoder后的编码),图像生成可以表述为自回归下一个索引预测:
- 给定索引 s<i,转换器学习预测可能的下一个索引的分布,即 p(si|s<i) 。
- 将完整表示的可能性计算为 p(s) = ∏i p(si|s<i)。这使我们能够直接最大化数据表示的对数似然:
L Transformer = E x ∼ p ( x ) [ − log p ( s ) ] \mathcal{L}_{\text {Transformer }}=\mathbb{E}_{x \sim p(x)}[-\log p(s)] LTransformer =Ex∼p(x)[−logp(s)]
条件合成
任务是在给定此信息 c 的情况下学习序列的可能性:
p ( s ∣ c ) = ∏ i p ( s i ∣ s < i , c ) p(s \mid c)=\prod_{i} p\left(s_{i} \mid s_{<i}, c\right) p(s∣c)=∏ip(si∣s<i,c)
如果条件信息 c 具有空间范围,我们首先学习另一个 VQGAN 再次获得基于索引的表示 r ∈ {0,…, |Zc|−1}hc ×wc 与新获得的码本 Zc 由于变压器的自回归结构,我们可以简单地将 r 前置到 s 并将负对数似然的计算限制为条目 p(si|s<i, r)。
合成高分辨率图像
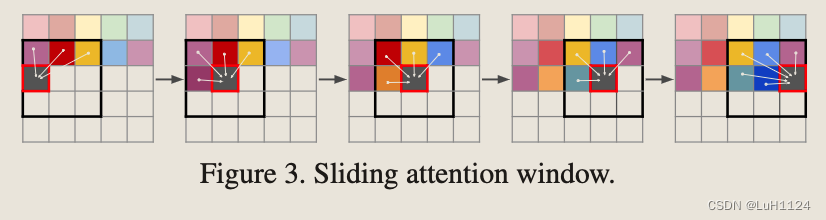
为了生成百万像素范围内的图像,因此我们必须处理补丁和裁剪图像,以在训练期间将 s 的长度限制为最大可行的大小。为了对图像进行采样,我们以滑动窗口的方式使用Transformer。
我们的VQGAN 确保可用的上下文仍然足以忠实地对图像进行建模,只要数据集的统计数据近似空间不变或空间条件信息可用。
实验
我们通常设置|Z|=1024,并训练所有后续的transformers模型来预测长度为16·16的序列
Attention Is All You Need in the Latent Space
transormers在很多任务上包括自回归图像生成取得了sota,那么现在的结构是否还能保证比CNN更强?
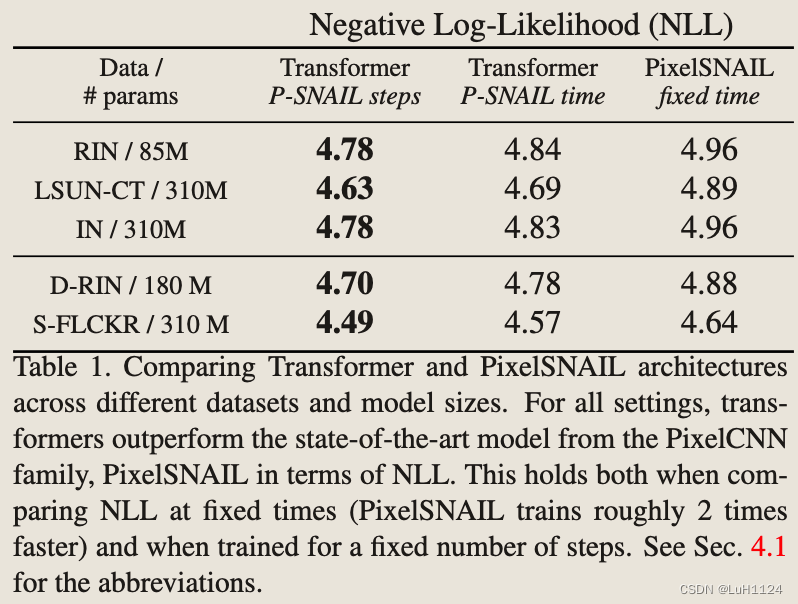
相比于SOTA的卷积自回归方法,相同epochs或者相同时间下的Transformer取得了更的负对数似然
A Unified Model for Image Synthesis Tasks
考察有条件生成,使用了类标签或分割图等附加信息c,目标是学习如式 p ( s ∣ c ) = ∏ i p ( s i ∣ s < i , c ) p(s \mid c)=\prod_{i} p\left(s_{i} \mid s_{<i}, c\right) p(s∣c)=∏ip(si∣s<i,c)所述的图像分布。
(i):语义图像合成,我们以ADE20K[72]、网络抓取景观数据集(S-FLCKR)和COCO-Stuff的语义分割掩码为条件。结果如图4、5和图6所示。
(ii):结构到图像,我们使用深度或边缘信息从 RIN 和 IN 合成图像(参见第 4.1 节)。得到的深度图像和边缘到图像转换如图4和图6所示。
(iii):姿势引导合成:图 4 显示了与之前实验相同的方法可用于在 DeepFashion 数据集上构建形状条件生成模型,而不是使用分割或深度图的语义丰富的信息。
(iv):随机超分辨率,其中低分辨率图像用作条件信息,从而进行上采样。我们在 ImageNet 上训练我们的模型上采样因子为 8,结果如图 6 所示。
(v):类条件图像合成:在这里,条件信息 c 是描述感兴趣类标签的单个索引。RIN 数据集的条件采样结果如图 4 所示。


高分辨率合成
第3.2节介绍的滑动窗口方法使图像合成超出256 × 256像素的分辨率。我们在LSUN-CT和FacesHQ上的无条件图像生成上评估我们的方法(见第4.3节),并在DRIN、COCO-Stuff和S-FLCKR上进行条件合成,我们在图1、6和补充中显示了结果(图17-27)。请注意,这种方法原则上可以用于生成任意比率和大小的图像,因为感兴趣的数据集的图像统计信息大致是空间不变的,或者空间信息是可用的。通过将该方法应用于S-FLCKR上语义布局的图像生成,可以获得令人印象深刻的结果,其中m = 5可以学习强VQGAN,使其码本和条件信息为变压器提供了足够的上下文,用于百万像素区域的图像生成。
Building Context-Rich Vocabularies、
为了研究这个问题,我们进行了 Transformer 架构保持固定的实验,而编码到第一阶段表示的上下文数量通过我们的 VQGAN 的下采样块的数量而变化。
- 我们根据图像输入和结果表示之间的边长的减少因子来指定编码的上下文量,即将大小为 H × W 的图像编码为大小为 H/f × W/f 的离散代码的第一阶段用因子 f 表示。对于 f = 1,我们重现的方法,并用 k = 512 的 RGB 值的 k-means 聚类替换我们的 VQGAN。在训练期间,我们总是裁剪图像以获得变压器大小为 16 × 16 的输入,即在第一阶段用因子 f 对图像进行建模时,我们使用大小为 16f × 16f 的裁剪。为了从模型中采样,我们总是以滑动窗口的方式应用它们,如第 3 节所述。
图7显示了FacesHQ上人脸无条件合成的结果,CelebA-HQ和FFHQ的组合。它通过增加变压器的有效感受野清楚地展示了强大的VQGAN的好处。对于小感受野,或者等效地小 f ,模型无法捕获连贯的结构。对于f = 8的中间值,可以近似图像的整体结构,但出现了半胡须脸和图像不同部位视点等面部特征的不一致。只有我们的完整模型off = 16可以合成高保真样本。对于 S-FLCKR 的条件设置中的类似结果,我们参考附录(图 10 和 Sec. B)。

为了定量评估我们方法的有效性,我们比较了**直接在像素上训练转换器的结果,并在具有固定计算预算的 VQGAN 潜在代码之上对其进行训练。**学习 CIFAR10 上 512 个 RGB 值字典,直接在像素空间上操作,并在我们的 VQGAN 之上训练相同的变压器架构,潜在代码大小为 16 × 16 = 256。我们观察到 FID 的改进为 18.63%,图像采样速度快 14.08×。
Benchmarking Image Synthesis Results


Class-Conditional Synthesis on ImageNet
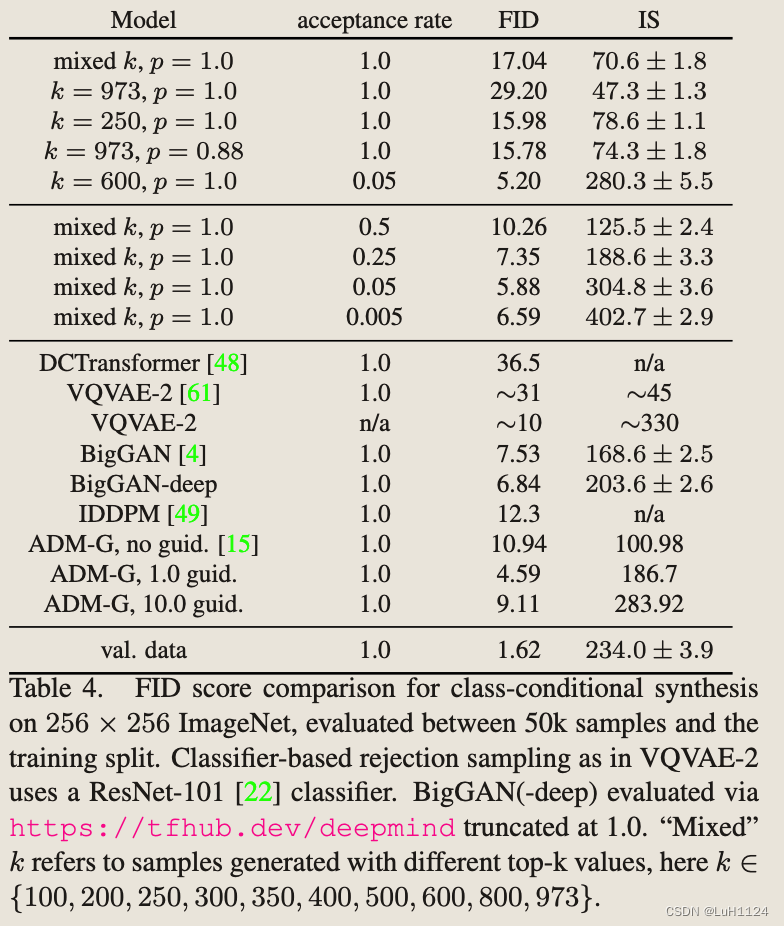

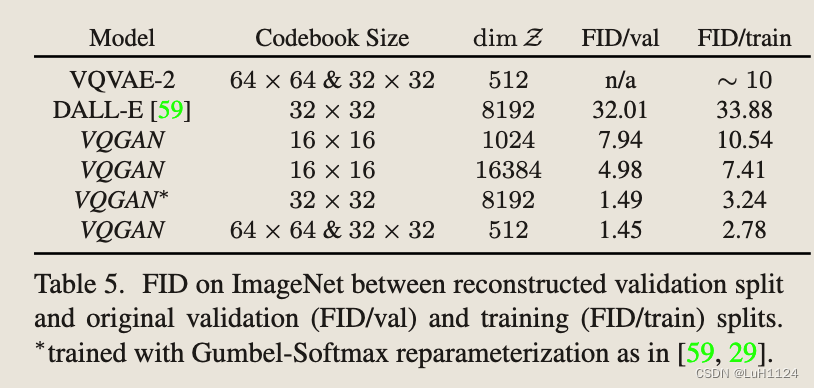
结论
本文解决了以前将transformer限制在低分辨率图像中的基本挑战。我们提出了一种将图像表示为感知丰富的图像成分的组合的方法,从而克服了直接在像素空间中建模图像时不可行的二次复杂度。使用 CNN 架构及其与 Transformer 架构的组合建模成分利用了它们互补优势的全部潜力,从而允许我们使用基于转换器的架构表示高分辨率图像合成的第一个结果。在实验中,**我们的方法通过合成百万像素范围内的图像,证明了CNN归纳偏差和transformer的表达能力,并优于最先进的卷积方法。**配备了条件合成的一般机制,它为新的神经渲染方法提供了许多机会。
附录
40页的俘虏就不摆放啦,做了非常多的实验,可以细看论文