content
attention mechanism
transformer structure
- pretrained language models
language modeling
pre-trained langue models(PLMs)
fine-tuning approaches
PLMs after BERT
applications of masked LM
frontiers of PLMs
- transformers tutorial(学术界和工业界运用广泛的开源包)
introduction
frequentli-used APIs
quick start
demo
attention mechanism注意力机制
以下是一个运用RNN模型来解决机器翻译问题的一个具体例子,这个模型中存在一个非常重要的问题,即信息瓶颈的问题

Q: 什么是信息瓶颈问题?
我们可以看到,需要从decoder端最后表示的向量来输出一个完整的正确的句子,那么这样就要求encoder端得到的最后一个向量表示,需要包含他输入句子的所有信息。
但是就这样一个向量,真的能够足够表达所有句子中包含的多种多样的信息吗,这个答案显然是否定的,研究人员也确实发现,这样一个向量的容量,会显著地限制模型encoder端的一个表示。
其实,在encoder端每一个位置的隐向量,都包含有丰富的信息,而最后这个向量其实就是整个encoder和decoder模型之间的一个信息瓶颈
之后要学习的注意力机制,就是为了解决这样一个问题而提出的
注意力机制的核心思想,就是通过在decoder的每一步,都把encoder端所有的向量提供给decoder模型,这样decoder根据自己当前的状态,来自动选择需要使用的信息和向量,来实现信息瓶颈的这样一个环节

以下是一个具体的例子:
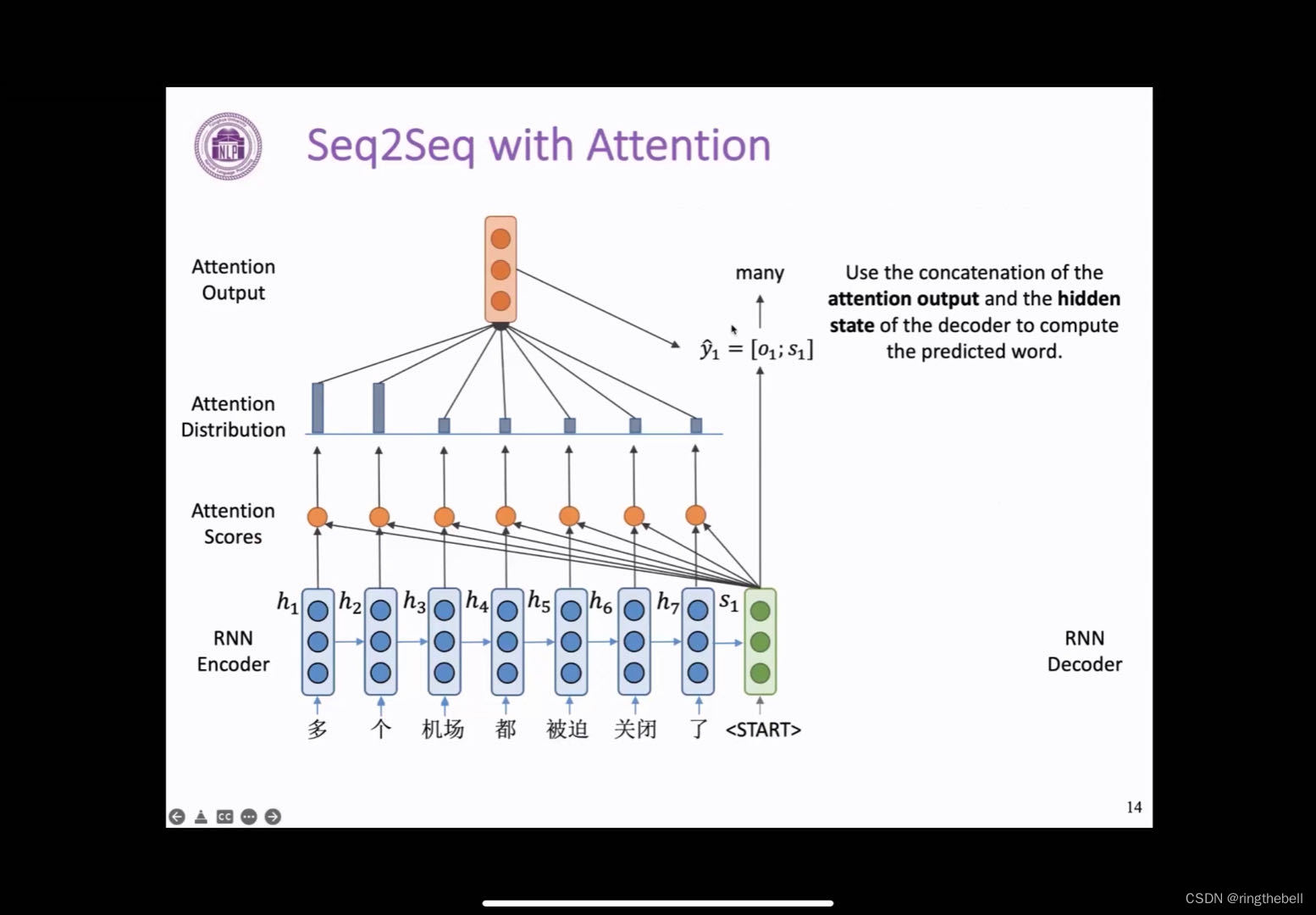
在这个图中,我们用蓝色表示encoder,用绿色表示decoder
encoder端得到的每一个隐向量,分别用h1到h7来表示;在decoder端它得到的第一个向量用s1来表示
与之前RNN模型不同的是,我们不用这个s1来直接计算这一步生成的单词的概率,而是利用s1来选择关注输入句子中的哪些部分,并计算得到一个新的隐向量,来得到生成单词的概率。
那么这样的一个decoder端如何根据s1来对encoder端的向量进行选择呢,我们首先需要计算一个叫做注意力分数的东西,这里我们将s1与h1进行点积,就可以得到一个标量,我们称它为e11

按此方法依次重复,我们就可以得到一个长度为7的向量,其中每个元素都是s1和对应位置的隐向量点积得到,我们将这样一个长度为7的向量称为encoder端隐向量的一个注意力分数,这个分数就表示了s1与每一个encoder端隐向量hi的一个相似程度,值越高,就表示s1与对应的隐向量相似程度越高
有了这个长度为7的注意力分数,我们需要把它变为一个概率分布,这里就需要用到softmax函数,这个函数会把e1中的每一个值变为从0到1之间的值,并且求和为1,这其实就可以看作是一个概率分布,而且之前e1中值越高的位置,对应在这个概率分布中,它也就会越大,并且越接近于1,表明decoder端将会更加关注这些位置的向量,我们可以看到在当前这个例子中,前两个位置的这个概率分布的值是比较高的,也说明这一步的生成会更加关注前两个位置的隐向量
随后,在第三步,我们利用前面得到的这样一个注意力分布,对encoder端的隐向量,进行一个加权的求和,然后就可以得到一个与隐向量维度相同的输出向量o1,这个向量也包含了decoder端当前所需要的encoder端的所有信息

这样,我们最后将o1与RNN得到的隐向量s1进行一个拼接,我们就可以得到一个新的表示,来表示decoder端这一步的一个状态,用这样一个向量来预测下一步需要生成的单词。
在这个例子中,我们得到many这个词,可以看到many其实它也就对应这个输入中的多个这样一个含义,这个也可以从我们这个注意力分布的高低,可以看到它的这样一个对应关系
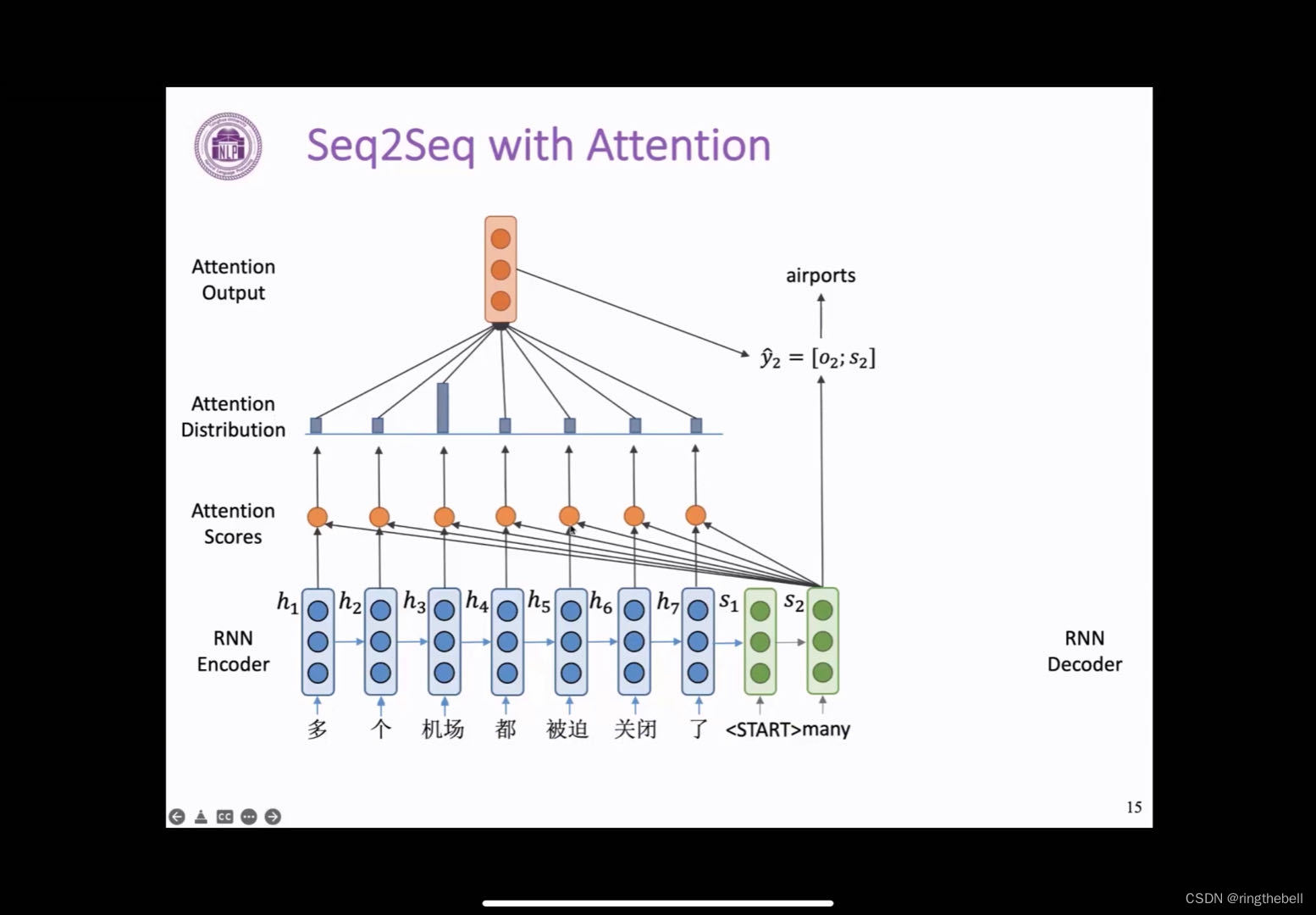
随后,和正常的RNN流程一样,我们将many输入到decoder端,就可以得到它的下一个表示s2,并且重复刚才的过程,我们就可以得到这一步需要输出的一个单词,而这里我们可以看到,模型输出了airports这个单词,而且他的注意力分布也是更加关注输入中的机场这个词,也是一个相互对应的关系
这样的步骤不断重复,我们对于decoder端的每一步,就可以自主的关注到decoder不同位置的隐向量,然后预测出一个新的单词,最后就可以得到一整个输出句子,完成整个模型的一个输出
这个就是在之前RNN模型中加入了attention机制的一个效果

下面我们对这样的一个注意力机制,进行一个形式化的总结:
以encoder端得到n个隐向量h1~hn
decoder端的每一步,都可以得到一个向量st,这是通过RNN得到的表示当前状态的一个隐向量
我们将st与前面的每个hi进行点积,就可以得到一个注意力分数,它的长度其实和encoder端的向量的数量是一样的
然后通过一个softmax函数,就可以将之前的一个标量变为一个0到1之间的一个概率分布

有了这样的一个概率分布之后,我们就可以对encoder端的向量进行一个加权平均,进而可以得到一个输出向量ot
最后通过将ot和st进行一个拼接,我们就可以得到最终用来预测生成单词的向量
这就是前面在端到端这样的模型中加入attention机制后的一个形式化表示,而attention的过程就是这个不断动态选择hi的一个过程

我们可以对前面那个attention的一个计算过程进行一个更加抽象的定义,这里我们给定一个query向量和一系列value向量,也就是对应我们之前提到的decoder端的向量和encoder端的向量,而注意力机制本质上就是通过一个query向量,对一个valye向量的集合进行加权平均,它是一个动态选择的过程,同时value向量的数量是可以任意的一个数值,最终我们都可以通过一个attention机制得到一个综合了所有value向量信息的表示,而且它具有一个固定的维度和这个value向量的维度是一致的

我们进行一个数学归纳:同样我们这里用h1~hn表示n个value向量以及一个query向量s,attention的机制首先它通过s和每个hi的一个交互,我们可以得到一个注意力分数,也就是这里的e,,这样的一个注意力分数,它的维度其实和value向量的数量是一样的,是属于rn的,然后就这样一个分数计算softmax,得到一个概率分布,通过此概率分布对前面所有的这个value向量进行一个加权平均,也就得到了这个attention的一个输出
关于如何计算注意力分数e,其实有很多种变体,前面的点积是一种非常常用的方式,在3-2中将介绍几种其他的一些变体