第一课:Transformer
文章目录
- 第一课:Transformer
- 1、学习总结:
- 什么是语言模型?
- 大语言模型(LLM)技术演变史
- 注意力机制
- Transformer结构
- 课程ppt及代码地址
- 2、学习心得:
- 3、经验分享:
- 4、课程反馈:
- 5、使用MindSpore昇思的体验和反馈:
- 6、未来展望:
1、学习总结:
什么是语言模型?
从科学上给语言这个东西给个定义。实际上有两种思路,一种是集合的定义,把语言里面所有能够说出来的句子和在这个语言里面可以理解的句子都定义为一个合法的句子,这些句子组成了一个有限的集合;另一种是用概率的定义方法,即把一个语言理解成为这个语言里面能够所有说的那些句子的一个概率分布。

大语言模型(LLM)技术演变史
1、统计语言模型(SLM)时代
又叫做自回归语言模型,是一种基于概率的模型,用于生成文本或预测序列数据。这种类型的模型试图预测一个序列中的下一个元素,给定先前的元素或上下文信息。

2、基于神经网络的语言模型 (NNLM)
用GPU来计算,最重要的方法就是词嵌入的方法,将每个词变成一个向量,精度得到了很大的提升。

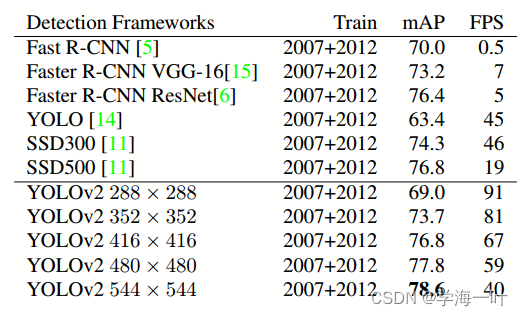
3、预训练语言模型(PLM)
预训练语言模型主要分为两个部分,一个是预训练的部分,一个是微调的部分。

4、通用人工智能(AGI)时代
本质上还是一个预训练模型,主要是Decoder的模型架构,比早期的预训练模型在结构上更简单,但模型规模变得很大,参数量上亿。

注意力机制
如同阅读时,视线只会集中在正在阅读的部分;自然语言处理中,根据任务内容的不同,句子中需要更加关注的部分也会不同。注意力机制便是在判断词在句子中的重要性,我们通过注意力分数来表达某个词在句子中的重要性,分数越高,说明该词对完成该任务的重要性越大。
计算注意力分数时,我们主要参考三个因素: query、 key和value。计算注意力分数就是计算query和key的相似度,主要有两种方法:缩放点积注意力(Scaled Dot-Product Attention) 和 加性注意力(Additive Attention)。最常用的是缩放点积注意力,其公式如下: Attention Output = softmax ( Q ⋅ K T d k ) ⋅ V \text{Attention Output} = \text{softmax} \left( \frac{Q \cdot K^T}{\sqrt{d_k}} \right) \cdot V Attention Output=softmax(dkQ⋅KT)⋅V,其中 Q 是查询向量,K是键向量,V 是值向量,dk 是键向量的维度。
- query:任务内容
- key:索引/标签(帮助定位到答案)
- value:答案
普通的注意力机制(例如缩放点积注意力)通常是使用单一的注意力权重来将输入序列中不同位置的信息融合到一起。这意味着对于每个查询,都会得到一个对应于所有键的权重分布。但在某些情况下,单个的注意力权重分布可能无法捕捉到序列中复杂的关系。
多头注意力机制引入了多组不同的注意力权重,每组被称为一个“头”。每个头都有自己的查询、键和值的线性投影,从而生成一个独立的注意力输出。这些独立的输出会被拼接或合并,并经过另一个线性变换来产生最终的多头注意力输出。
**多头注意力的主要优势在于它能够同时关注序列中的不同子空间或方面,并且可以学习到更丰富和复杂的表示。**这有助于模型更好地捕获序列中的长距离依赖关系和语义信息。
总结一下,多头注意力与普通的注意力机制不同之处在于:
- 多个头:多头注意力有多个注意力头,每个头都有自己的查询、键和值的投影矩阵。
- 独立计算:每个头都会独立计算注意力分数和输出,因此能够捕捉序列不同方面的信息。
- 合并与融合:多头注意力的输出通常会合并或融合多个头的输出,以获得更综合的表示。


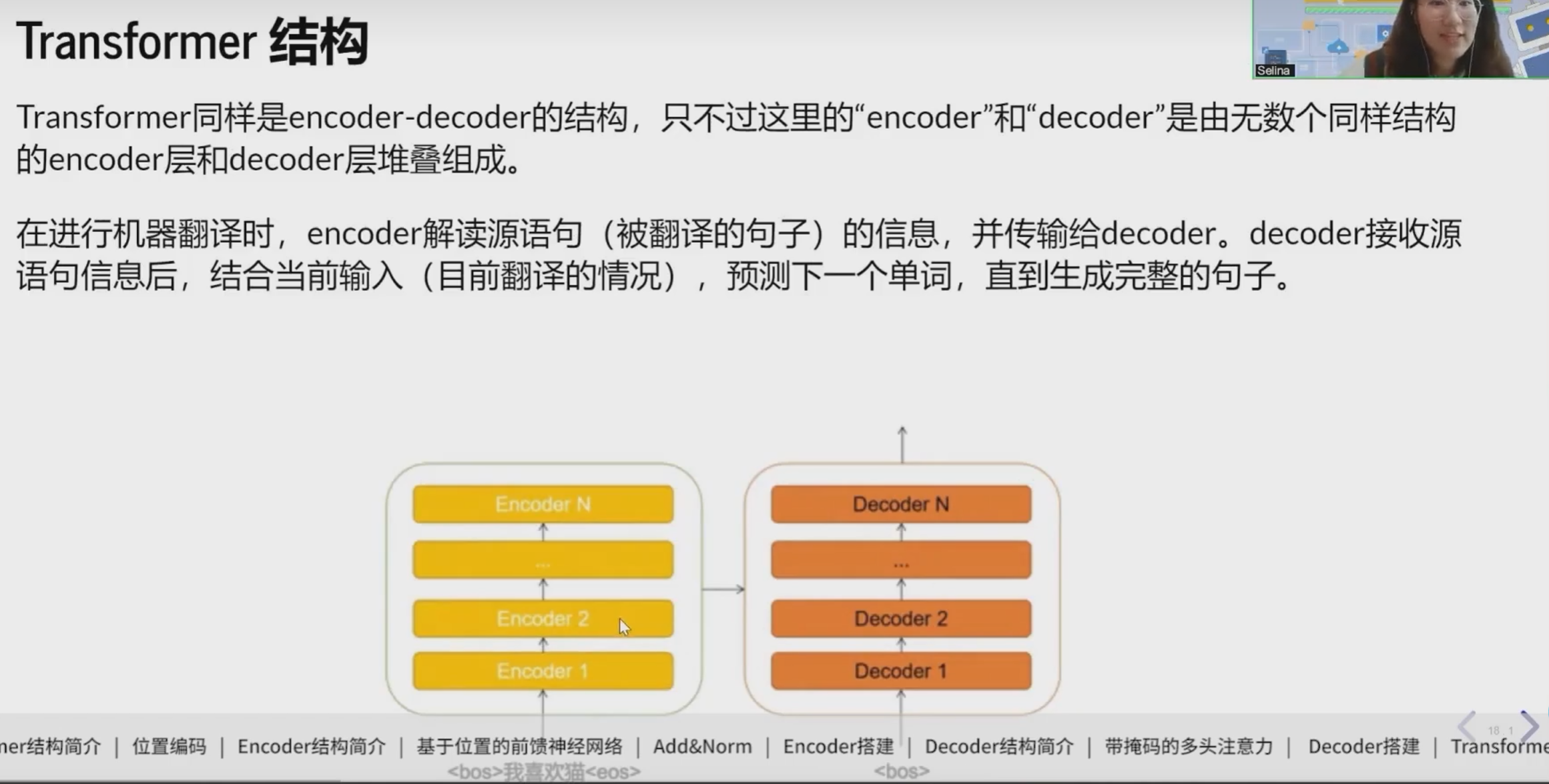
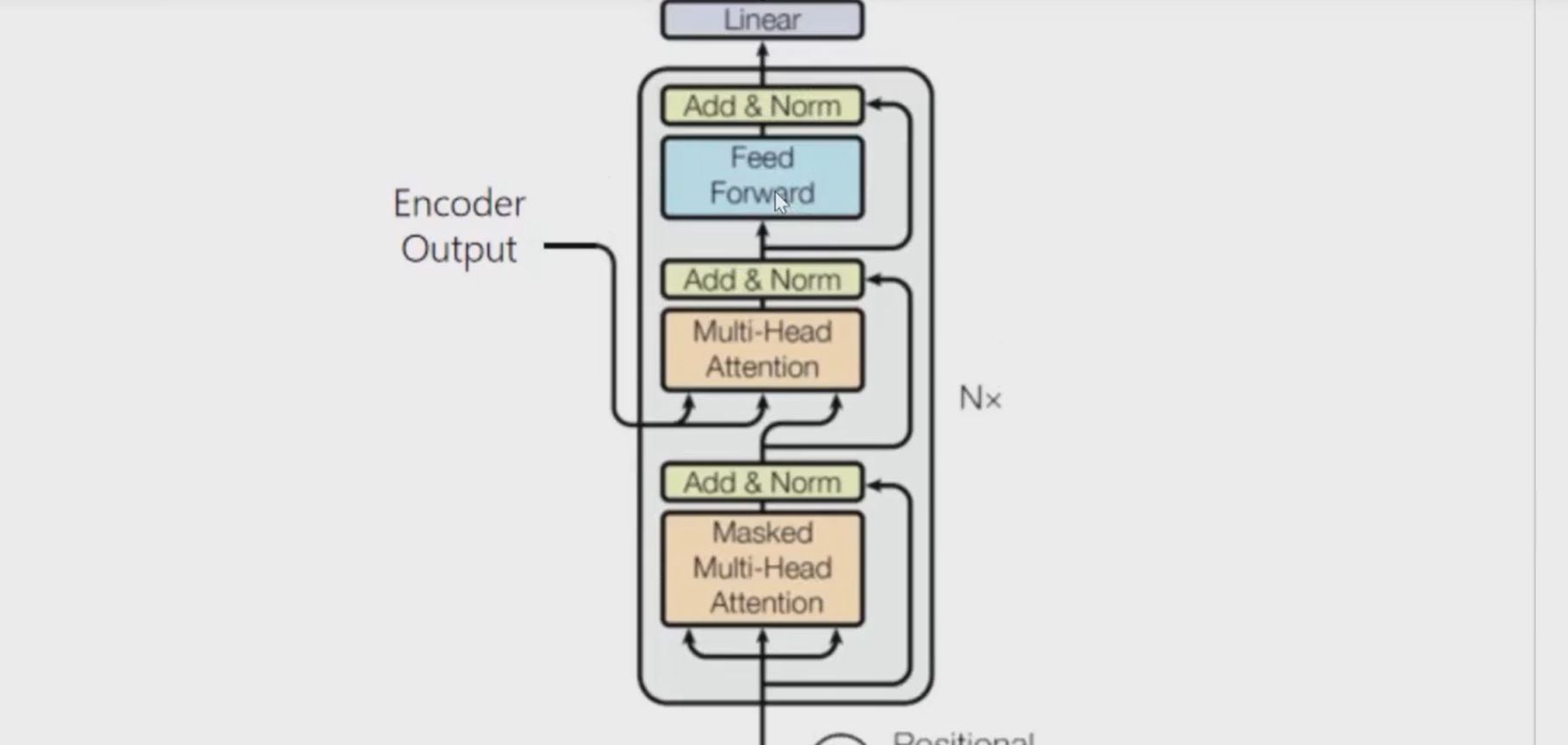
Transformer结构
Transformer由Attention机制构建而成,具有编码器(Encoder)和解码器(Decoder)两个主要部分。下面是Transformer的主要组成部分:
- 位置编码(Positional Encoding)
Transformer中没有循环神经网络(RNN)或卷积神经网络(CNN)中的序列位置信息。为了将顺序信息引入模型,位置编码被添加到输入数据中,使模型能够理解输入序列中不同位置的单词或标记。

- 编码器(Encoder)
编码器由多个相同的层堆叠而成。每个编码器层通常由两个子层组成:
- 自注意力机制(Self-Attention):用于计算输入序列内部元素之间的关联性,以便更好地理解全局信息。
- 前馈神经网络(Feed-Forward Neural Network):在每个位置上应用全连接层来处理自注意力子层的输出。


- 残差连接(Residual Connections)和 层归一化(Layer Normalization)
在每个子层(如自注意力层和前馈神经网络层)之后都会添加残差连接。这使得神经网络更容易训练,减轻了深度网络中的梯度消失问题。在每个子层的输出上应用层归一化,有助于提高模型的训练稳定性和收敛速度。

- 解码器(Decoder)
解码器也由多个相同的层堆叠而成。每个解码器层同样由两个子层组成:
- 自注意力机制(Self-Attention):用于关注解码器自身的不同位置,确保在生成输出时考虑到上下文信息。
- 编码器-解码器注意力机制(Encoder-Decoder Attention):帮助解码器关注输入序列的不同部分,使其能够利用编码器产生的信息来生成正确的输出。
课程ppt及代码地址
github地址(网络不好的可以访问下面我克隆到gitee上的地址):
step_into_llm/Season1.step_into_chatgpt/1.Transformer at master · mindspore-courses/step_into_llm (github.com)
gitee地址:
Season1.step_into_chatgpt/1.Transformer · a strong python/step_into_llm - 码云 - 开源中国 (gitee.com)
2、学习心得:
通过本次学习,熟悉了Mindspore这个国产深度学习框架,也对transformer的基本技术原理有所了解,最重要的是能够通过transformer完成一个简单的机器翻译的任务,这让我十分有成就感!!!希望Mindspore越来越好,能够推出更多的优质课程!!!
3、经验分享:
在启智openI上的npu跑transformer.ipynb时,数据下载模块的代码会报错,原因是openI上ssl证书失效,无法用download模块进行下载,但是可以用wget进行下载,这里将修改的代码贴在这儿,如果大家遇到和我一样的问题可以直接替换。
#原始代码
from download import download
from pathlib import Path
from tqdm import tqdm
import os
urls = {
'train': 'http://www.quest.dcs.shef.ac.uk/wmt16_files_mmt/training.tar.gz',
'valid': 'http://www.quest.dcs.shef.ac.uk/wmt16_files_mmt/validation.tar.gz',
'test': 'http://www.quest.dcs.shef.ac.uk/wmt17_files_mmt/mmt_task1_test2016.tar.gz'
}
cache_dir = Path.home() / '.mindspore_examples'
train_path = download(urls['train'], os.path.join(cache_dir, 'train'), kind='tar.gz')
valid_path = download(urls['valid'], os.path.join(cache_dir, 'valid'), kind='tar.gz')
test_path = download(urls['test'], os.path.join(cache_dir, 'test'), kind='tar.gz')
#修改后的代码
from download import download
from pathlib import Path
from tqdm import tqdm
import os
# # 创建缓存目录
# !mkdir -p ~/.mindspore_examples/train
# !mkdir -p ~/.mindspore_examples/valid
# !mkdir -p ~/.mindspore_examples/test
# # 下载训练数据
# !wget -P ~/.mindspore_examples/train http://www.quest.dcs.shef.ac.uk/wmt16_files_mmt/training.tar.gz && tar -xzf ~/.mindspore_examples/train/training.tar.gz -C ~/.mindspore_examples/train
# # 下载验证数据
# !wget -P ~/.mindspore_examples/valid http://www.quest.dcs.shef.ac.uk/wmt16_files_mmt/validation.tar.gz && tar -xzf ~/.mindspore_examples/valid/validation.tar.gz -C ~/.mindspore_examples/valid
# # 下载测试数据
# !wget -P ~/.mindspore_examples/test http://www.quest.dcs.shef.ac.uk/wmt17_files_mmt/mmt_task1_test2016.tar.gz && tar -xzf ~/.mindspore_examples/test/mmt_task1_test2016.tar.gz -C ~/.mindspore_examples/test
train_path = '/root/.mindspore_examples/train'
valid_path = '/root/.mindspore_examples/valid'
test_path = '/root/.mindspore_examples/test'
4、课程反馈:
本次课程中的代码串讲我觉得是做的最好的地方,没有照着ppt一直念,而是在jupyter上把代码和原理结合到一块进行讲解,让学习者对代码的理解更加深入。我觉得内容的最后可以稍微推荐一下与Mindspore大模型相关的套件,让学习者在相关套件上可以开发出更多好玩和有趣的东西!
5、使用MindSpore昇思的体验和反馈:
MindSpore昇思的优点和喜欢的方面:
- 灵活性和可扩展性: MindSpore提供了灵活的编程模型,支持静态计算图和动态计算图。这种设计使得它适用于多种类型的机器学习和深度学习任务,并且具有一定的可扩展性。
- 跨平台支持: MindSpore支持多种硬件平台,包括CPU、GPU和NPU等,这使得它具有在不同设备上运行的能力,并能充分利用各种硬件加速。
- 自动并行和分布式训练: MindSpore提供了自动并行和分布式训练的功能,使得用户可以更轻松地处理大规模数据和模型,并更高效地进行训练。
- 生态系统和社区支持: MindSpore致力于建立开放的生态系统,并鼓励社区贡献,这对于一个开源框架来说非常重要,能够帮助用户更好地学习和解决问题。
一些建议和改进方面:
- 文档和教程的改进: 文档和教程并不是很详细,希望能够提供更多实用的示例、详细的文档和教程,以帮助用户更快速地上手和解决问题。
- 更多的应用场景示例: 提供更多真实场景的示例代码和应用案例,可以帮助用户更好地了解如何在实际项目中应用MindSpore。
6、未来展望:
通过本次Transformer课程的学习,我能够更好地理解Transformer内部运作机制和设计原理,可以更深入地应用它在语言建模、翻译、摘要、问答等任务中,并探索其在其他领域(如图像处理、推荐系统等)的潜在应用。也能够更好地理解大型模型的优势、局限性和应用场景,探索如何解决与大型模型相关的问题。
基于课程学到的知识,我对人工智能和大模型的发展和应用有以下展望:
- 更强大和智能的AI应用:随着对Transformer和大型模型的理解深入,未来的AI系统将变得更加智能和灵活,能够更好地理解和处理复杂的自然语言以及其他领域的数据。
- 更高效的模型设计和训练:在大模型的发展过程中,不断寻求更高效的模型设计、训练策略以及推理方法,以解决资源消耗、存储、能效等问题。
- 多模态和跨领域应用:Transformer的成功为多模态数据和跨领域信息融合提供了新思路。未来,我们可以期待更多融合不同类型数据的模型,以解决更广泛的问题。
- 持续探索新的模型结构和学习机制:Transformer的成功启发了对新模型结构和学习机制的探索,这种创新将继续推动AI领域的发展。