目录
相关资料
模型概述
Patch to Token
Embedding
Token Embedding
Position Embedding
ViT总结
相关资料
论文链接:https://arxiv.org/pdf/2010.11929.pdf
论文源码:https://github.com/google-research/vision_transformer
PyTorch实现代码: pytorch_classification/vision_transformer
Tensorflow2实现代码:tensorflow_classification/vision_transformer
在bilibili上的视频讲解:https://www.bilibili.com/video/BV1Jh411Y7WQ
博客讲解:https://blog.csdn.net/qq_375410
https://juejin.cn/post/7254341178258489404
模型概述
在Transformer Encoder架构的启发下,Google推出了VIT(Vision Transformer):一个和Bert几乎一致,同时不添加任何卷积结构的图像分类模型。VIT在Transformer上的成功,证明了可以用统一的模型,来处理不同领域(语言/图像/视频)的任务,进而开启了多模态模型研究的新篇章。今天就和大家一起学习一下ViT的相关知识~
VIT的训练:把图片分成多个patch,送入Transformer Encoder,然后拿<cls>对应位置的向量,经过一个softmax多分类模型,去预测原始图片中描绘的物体类别。
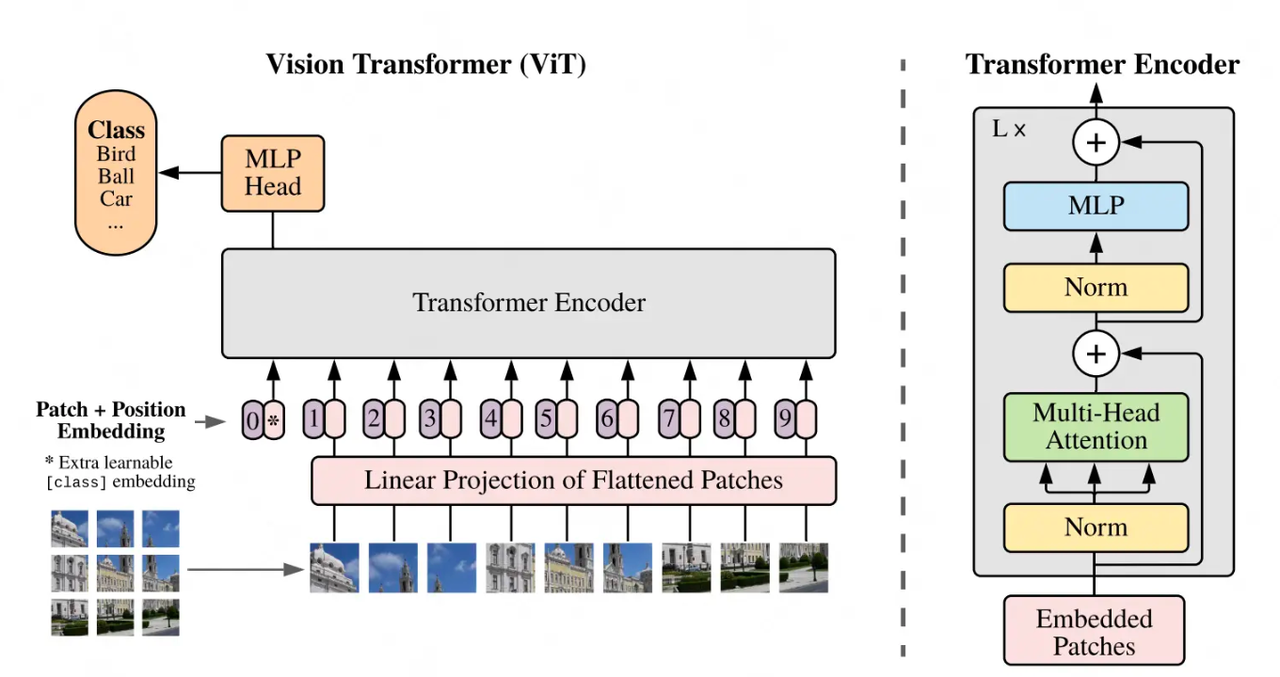
左边部分:
-
Patch:对于输入图片,首先将它分成几个patch(如图中分为9个patch),每个patch就类似于NLP中的一个token。
-
Position Embedding:每个patch的位置向量,用于指示对应patch在原始图片中的位置。和Bert一样,这个位置向量是learnable的,而并非原始Transformer中的函数式位置向量。
-
Input: 最终传入模型的Input = patching_emebdding + position embedding,同样,在输入最开始,我们也加一个分类符
<cls>,在bert中,这个分类符是作为“下一句预测”中的输入,来判断两个句子是否真实相连。在VIT中,这个分类符作为分类任务的输入,来判断原始图片中物体的类别。
右侧部分:
给出了Transformer Encoder层的架构,它由L块这样的架构组成。
Patch to Token

224*224*3的原始图像切分成196个16*16*3大小的patch,每个patch对应着一个token,将每个patch展平则得到输入矩阵X,其大小为(196,768),也就是每个token是768维。通过这样的方式可以将图像数据处理成自然语言的向量表达方式。patch to token 有两个优点:1.减少模型计算 2. 图像数据带有较多冗余信息,不需细粒度计算。
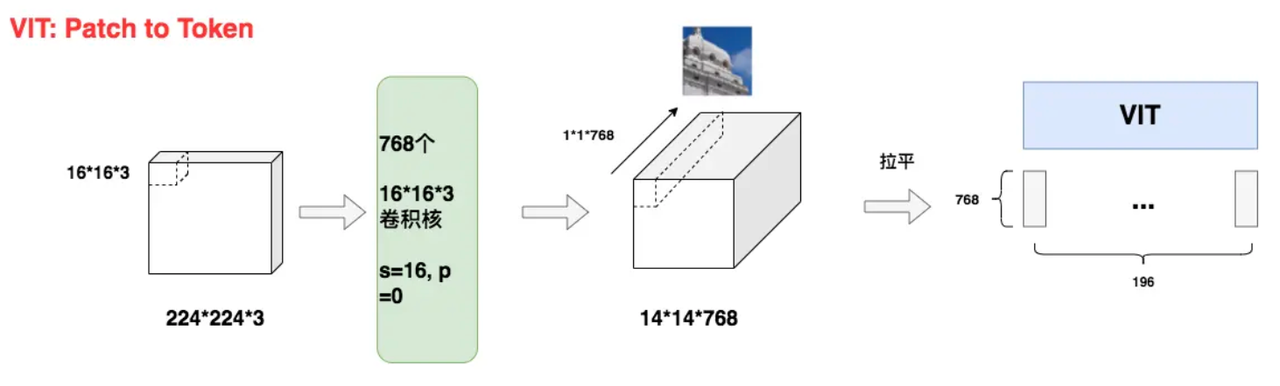
对于每一个16*16*3的图像patch,需要将其拉平成1*768维的向量,ViT采用CNN进行特征提取,采用768个16*16*3尺寸的卷积核,stride=16,padding=0。这样我们就能得到14*14*768大小的特征图。如同所示,特征图中每一个1*1*768大小的子特征图,都是由卷积核对第一块patch做处理而来,因此它就能表示第一块patch的token向量。
Embedding
在Bert(及其它NLP任务中):输入 = token_embedding(将单个词转变为词向量) + position_embedding(位置编码,用于表示token在输入序列中的位置) + segment_emebdding( 非必须,在bert中用于表示每个词属于哪个句子)。在VIT中,同样存在token_embedding和postion_emebedding。
Token Embedding
Token embedding为一个(768,768)的矩阵,图像的每个patch尺寸为(196, 768),则经过token embedding后的结果为:XTE=X∗E=(196,768)∗(768∗768)=(196,768),转换为token_embedding后就可以参与主体模型的梯度更新。
Position Embedding
在NLP任务中,位置向量的目的是让模型学得token的位置信息。在VIT中也是同理,需要让模型知道每个patch的位置信息。位置向量为E_pos,则它是一个形状为(196,768)的矩阵,表示196个维度为768的向量,每个向量表示对应token的位置信息。

ViT总结
-
证明了一个统一框架在不同模态任务上的表现能力。在VIT之前,NLP的SOTA范式被认为是Transformer,而图像的SOTA范式依然是CNN。VIT出现后,证明了用NLP领域的SOTA模型一样能解图像领域的问题,同时在论文中通过丰富的实验,证明了VIT对CNN的替代能力,同时也论证了大规模+大模型在图像领域的涌现能力。
-
虽然VIT只是一个分类任务,但在它提出的几个月之后,立刻就有了用Transformer架构做检测(detection)和分割(segmentation)的模型。而不久之后,GPT式的无监督学习,也在CV届开始火热起来。
-
工业界上,对大部分企业来说,受到训练数据和算力的影响,预训练和微调一个VIT都是困难的,但是这不妨碍直接拿大厂训好的VIT特征做下游任务。