目录
前言
text2vec%E5%BC%80%E6%BA%90%E9%A1%B9%E7%9B%AE-toc" style="margin-left:0px;">text2vec开源项目
核心能力
文本向量表示模型
本地试用
安装依赖
huggingface%E4%B8%8A%E6%8B%89%E5%8F%96%E6%96%87%E4%BB%B6%EF%BC%8C%E5%8F%AF%E8%B7%B3%E8%BF%87%EF%BC%89-toc" style="margin-left:40px;">下载模型到本地(如果你的网络能直接从huggingface上拉取文件,可跳过)
运行试验代码
前言
在上一篇文章中介绍了,如何从不同格式的文件里提取文本信息。
本篇文章将介绍,如何将提取出的文本信息转换为vector,以便后续基于vector做相似性检索。
文档向量化工具(一):Apache Tika介绍![]() https://mp.csdn.net/mp_blog/creation/editor/134488150
https://mp.csdn.net/mp_blog/creation/editor/134488150
text2vec%E5%BC%80%E6%BA%90%E9%A1%B9%E7%9B%AE">text2vec开源项目
text2vec是github上很受欢迎的一个开源项目。
text2vec:Text to Vector。
【GitHub地址】
https://github.com/shibing624/text2vec
【开源协议】
Apache-2.0 license
核心能力
Text to Vector, Get Sentence Embeddings. 文本向量化,把文本(包括词、句子、段落)表征为向量矩阵。
text2vec实现了:
- Word2Vec
- RankBM25
- BERT
- Sentence-BERT
- CoSENT
等多种文本表征、文本相似度计算模型,并在文本语义匹配(相似度计算)任务上比较了各模型的效果。
文本向量表示模型
- Word2Vec:通过腾讯AI Lab开源的大规模高质量中文词向量数据(800万中文词轻量版) (文件名:light_Tencent_AILab_ChineseEmbedding.bin 密码: tawe)实现词向量检索,本项目实现了句子(词向量求平均)的word2vec向量表示
- SBERT(Sentence-BERT):权衡性能和效率的句向量表示模型,训练时通过有监督训练BERT和softmax分类函数,文本匹配预测时直接取句子向量做余弦,句子表征方法,本项目基于PyTorch复现了Sentence-BERT模型的训练和预测
- CoSENT(Cosine Sentence):CoSENT模型提出了一种排序的损失函数,使训练过程更贴近预测,模型收敛速度和效果比Sentence-BERT更好,本项目基于PyTorch实现了CoSENT模型的训练和预测
- BGE(BAAI general embedding):BGE模型按照retromae方法进行预训练,参考论文,再使用对比学习finetune微调训练模型,本项目基于PyTorch实现了BGE模型的微调训练和预测
本地试用
推荐用conda管理python环境
conda create -n py3.9 python=3.9 // 安装一个python3.9的环境
安装依赖
conda install -c pytorch pytorch
pip install -U text2vec
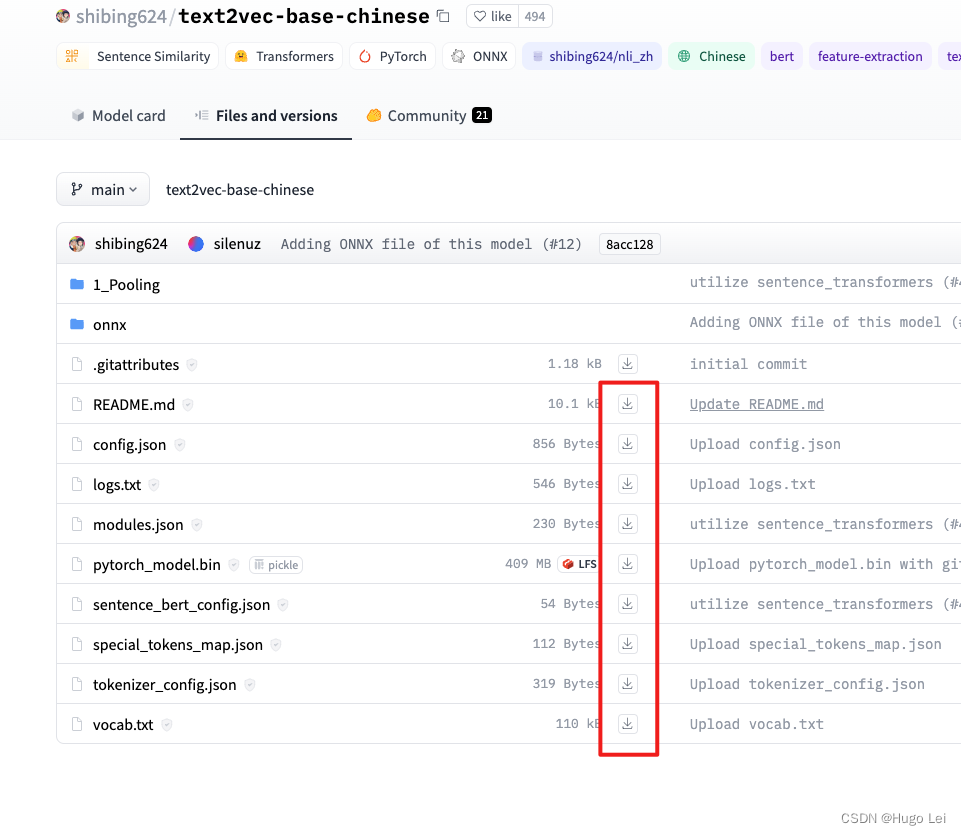
huggingface%E4%B8%8A%E6%8B%89%E5%8F%96%E6%96%87%E4%BB%B6%EF%BC%8C%E5%8F%AF%E8%B7%B3%E8%BF%87%EF%BC%89"> 下载模型到本地(如果你的网络能直接从huggingface上拉取文件,可跳过)
https://huggingface.co/shibing624/text2vec-base-chinese/tree/main
本地建立一个文件夹,名字是shibing624/text2vec-base-chinese
手动点击,逐个下载文件到此文件夹
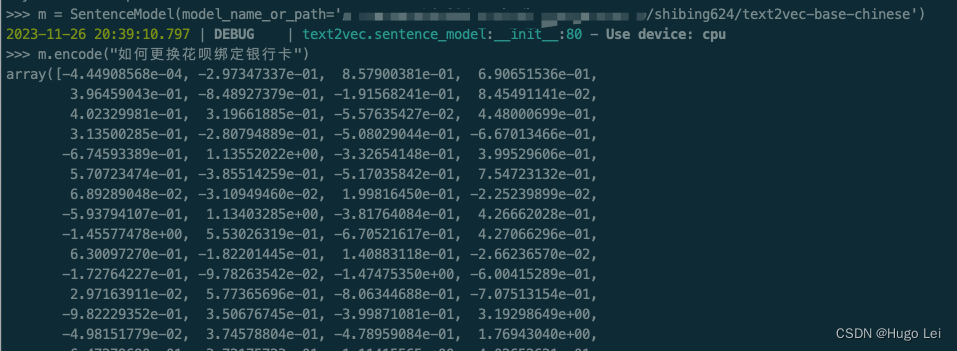
 运行试验代码
运行试验代码
# 设置huggingface以offline模式运行,从本地加载我们刚才下载的模型数据
HF_DATASETS_OFFLINE=1 TRANSFORMERS_OFFLINE=1from text2vec import SentenceModel
m = SentenceModel(model_name_or_path='/xxxxxxxx绝对路径xxxxxxx/shibing624/text2vec-base-chinese')
m.encode("如何更换花呗绑定银行卡")运行效果