文章目录
- 0 Abstract
- 1 Introduction
- 2 Related Works
- 3 Settings
- 3.1 CNN Block Instantiations
- 3.2 Computational Cost
- 3.3 Robustness Benchmarks
- 3.4 Training Recipe
- 3.5 Baseline Results
- 4 Component Diagnosis
- 4.1 Patchief Stem
- 4.2 Large Kernel Size
- 4.3 Reducing Activation And Normalization Layers
- 5 Components Combination
- 6 Knowledge Distillation
- 7 Larger Models
- 8 Conclusion
- Acknowledgement
- Reference
Article Reading Record

0 Abstract
- Transformers are inherently (本质上) more robust than CNNs
- we question that belief by closely examining the design of Transformers
- simple enough to be implemented in several lines of code, namely a) patchifying(修补) input images, b) enlarging kernel size, and c) reducing activation layers and normalization layers.
1 Introduction
- ViT offers a completely different roadmap—by applying the pure self-attention-based architecture to sequences of image patches, ViTs are able to attain competitive performance on a wide range of visual benchmarks compared to CNNs.
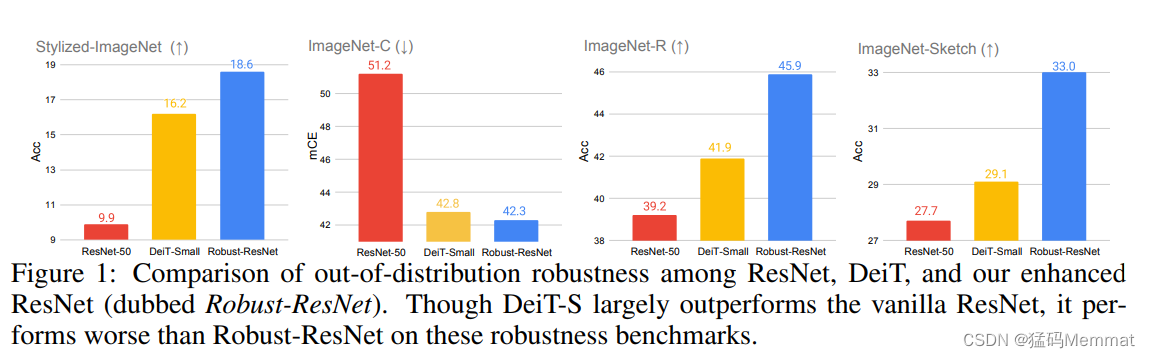
dubbed (被称为) vanilla(普通)
2 Related Works
- Vision Transformers.
- CNNs striking back ( 反击 )
- ConvNeXt, shifting the study focus from standard accuracy to robustness
- Out-of-distribution (分布) robustness.
ResNet Bottleneck block
counterpart (对口/对应方/同行)
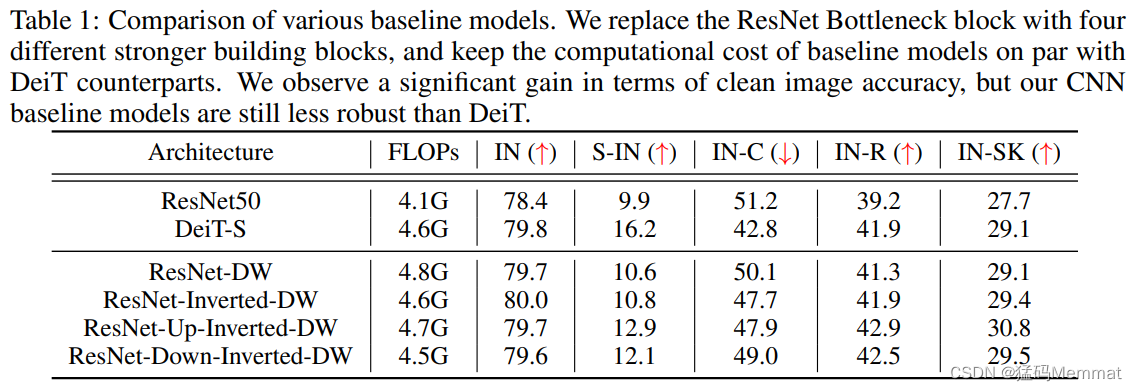
corruption (腐败/堕落) rendition (再现) inherently (本质)
- we show CNNs can in turn outperform Transformers in out-of-distribution robustness.
3 Settings
thoroughly (彻底)
3.1 CNN Block Instantiations
(实例化)
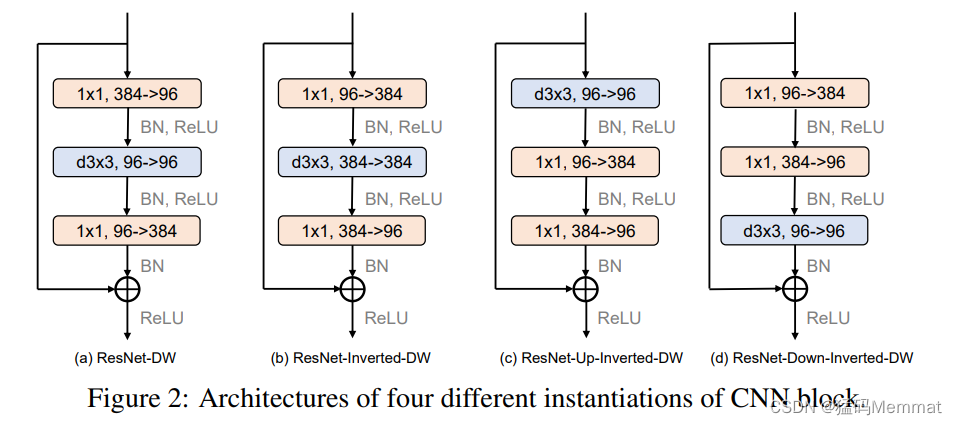
3.2 Computational Cost
mitigate (减轻) the computational cost loss
roughly(大约)
3.3 Robustness Benchmarks
extensively (广泛) evaluate
contains synthesized (合成) images with shape-texture(纹理) conflicting cues
image corruption(损坏)
which contains natural renditions (再现) of ImageNet object classes with different textures and local image statistics(统计)
3.4 Training Recipe
deliberately (故意) apply the standard 300-epoch DeiT training recipe
3.5 Baseline Results
we use “IN”, “S-IN”, “IN-C”, “IN-R”, and “IN-SK” as abbreviations(缩写) for “ImageNet”, “Stylized-ImageNet”, “ImageNet-C”, “ImageNet-R”, and “ImageNet-Sketch”.
4 Component Diagnosis
( 组件 )( 诊断 )
These designs are as follows: 1) patchifying
input images (Sec. 4.1), b) enlarging the kernel size (Sec. 4.2), and finally, 3) reducing the number
of activation layers and normalization layers (Sec. 4.3)
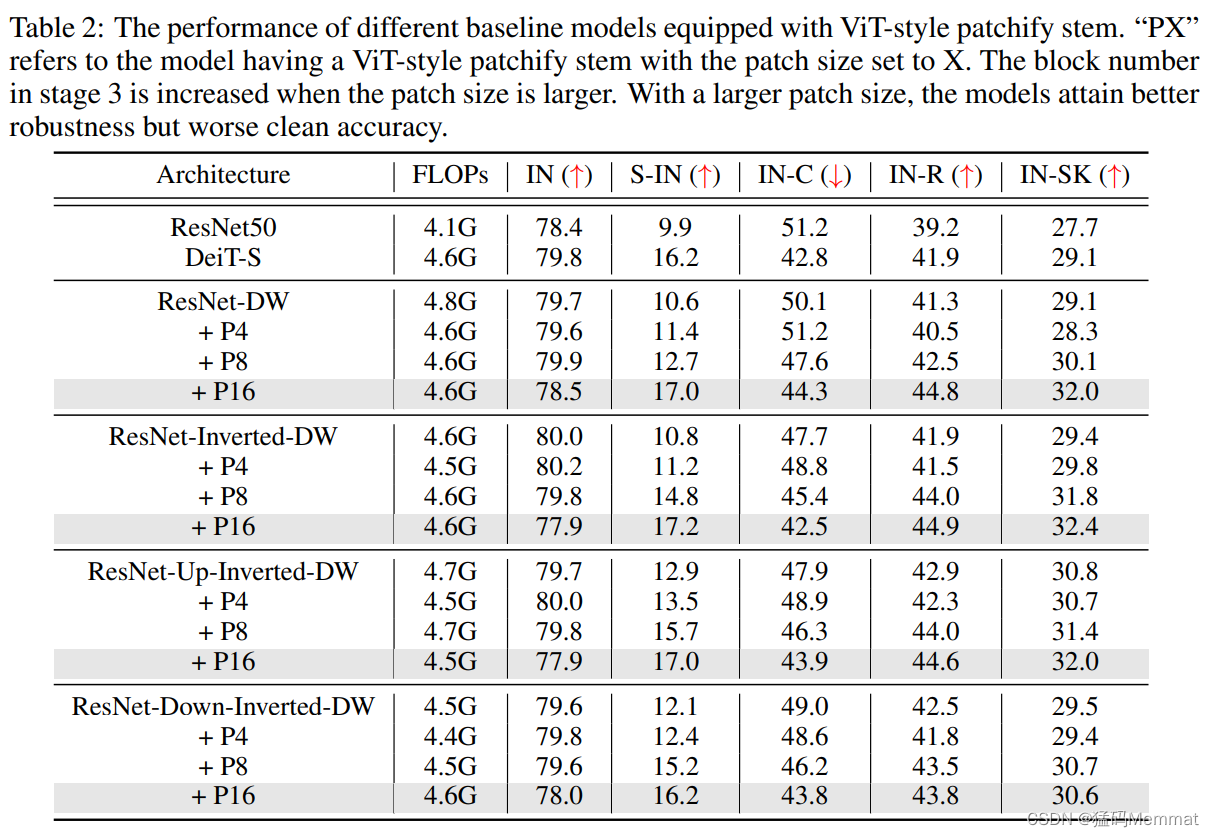
4.1 Patchief Stem
ViT adopts a much more aggressive down-sampling strategy by partitioning (分区) the input image into p×p non-overlapping (非重叠) patches and projects each patch with a linear layer
have investigated (调查) the importance of
when employing (使用) the 8×8 patchify stem
albeit (尽管) potentially (潜在) at the cost of clean accuracy
is boosted (提高) by at least 0.6%
play a vital(重要) role in closing the robustness gap between CNNs and Transformers.
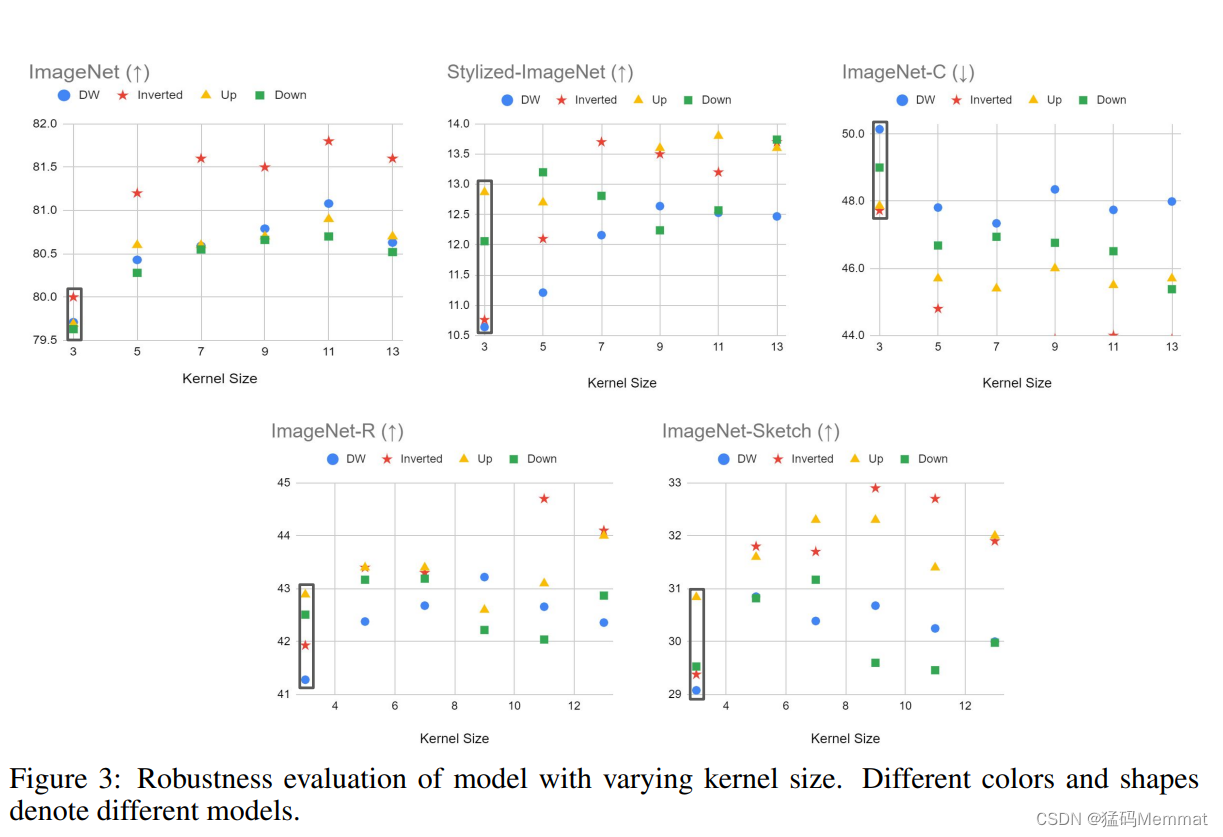
4.2 Large Kernel Size
One critical(关键) property (性质) that distinguishes the self-attention operation from the classic convolution operation is its ability to operate on the entire input image or feature map, resulting in a global receptive(接收) field.
The importance of capturing long-range (远程)dependencies (依赖)has been demonstrated (证明) for CNNs even
In this section, we aim to mimic (模仿) the behavior of the self-attention block
the performance gain gradually saturates(饱和)
an unfair(不公平的) comparison to some extent.(程度)
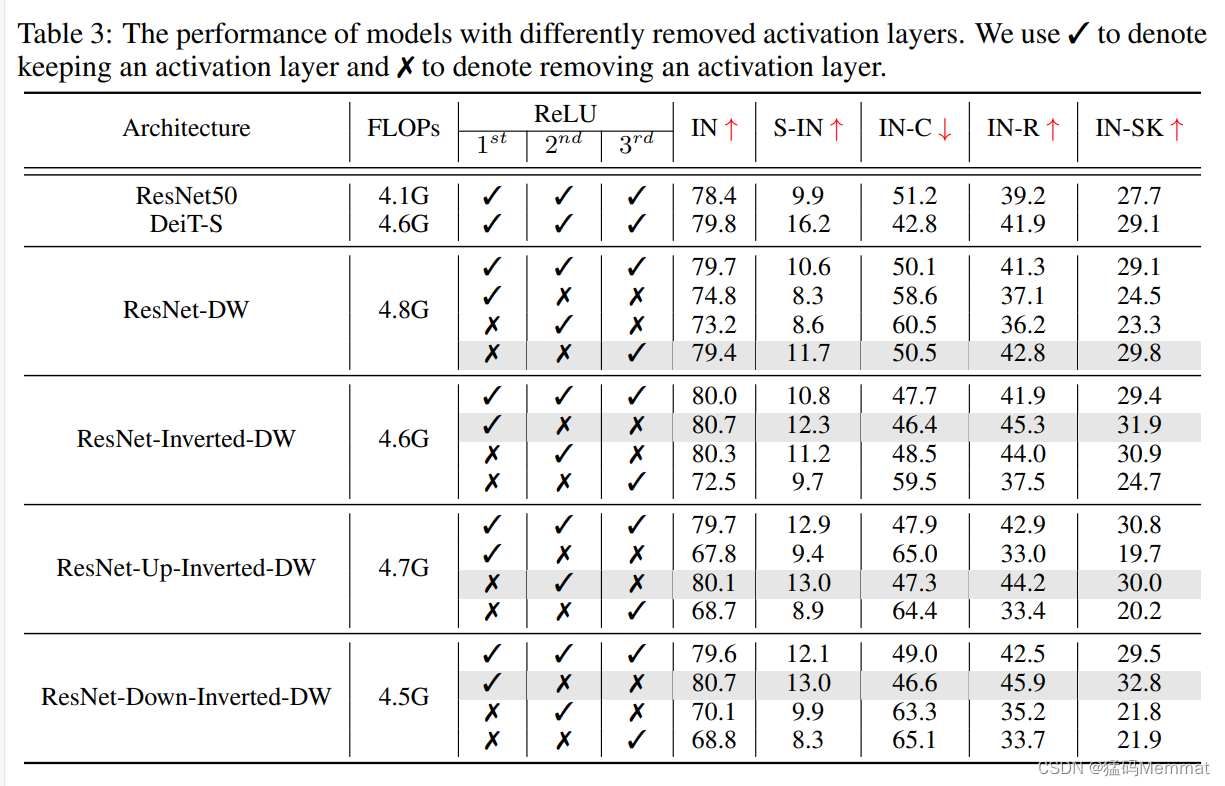
4.3 Reducing Activation And Normalization Layers
(规范化层)
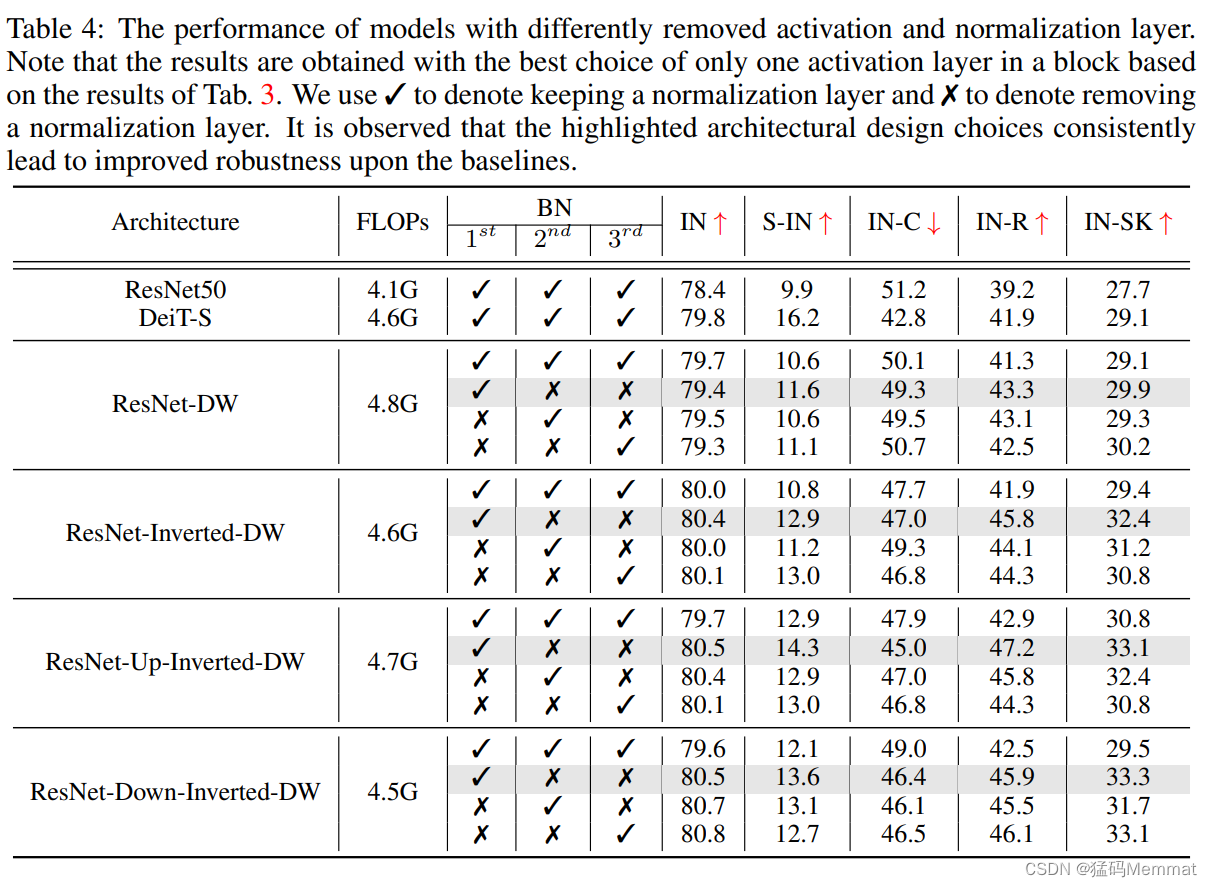
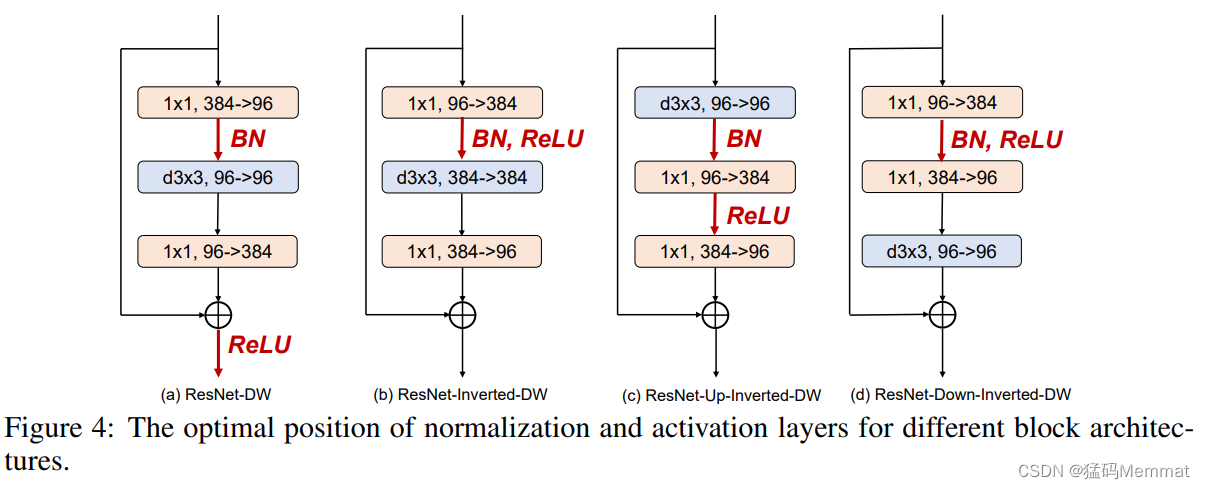
The optimal (最优) position
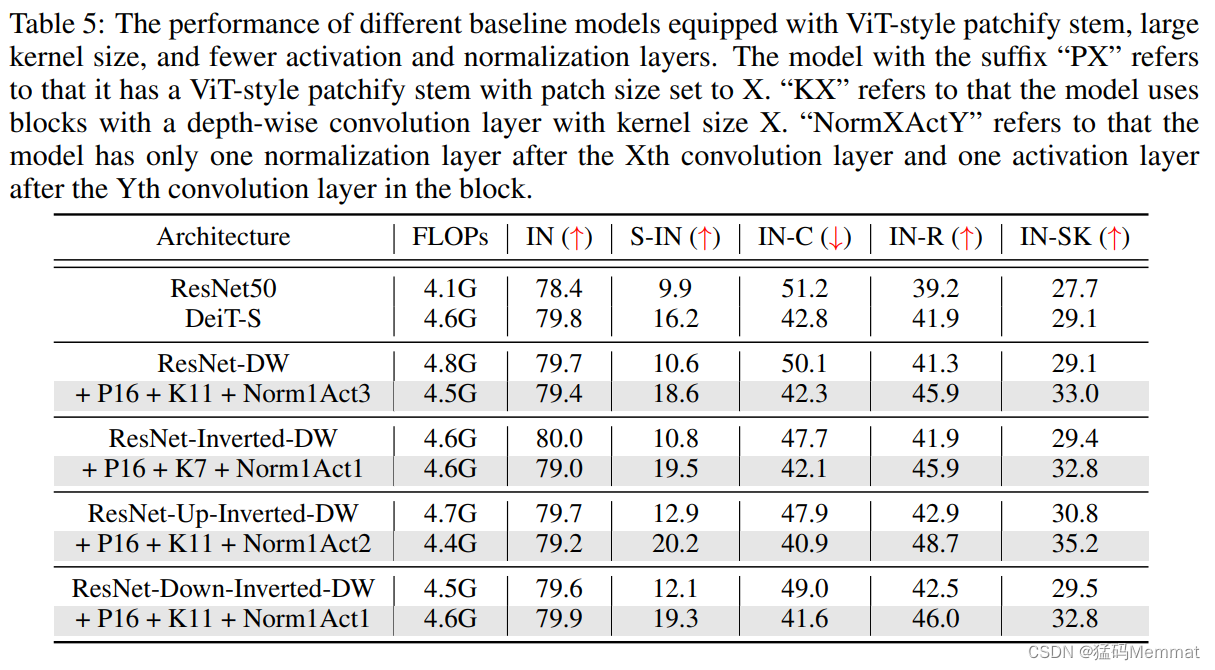
5 Components Combination
explore the impact of combining all the proposed components on the model’s performance.
along with the corresponding (相应) optimal (最优) position for placing the normalization and activation layer
An exception (异常) here is ResNet-Inverted-DW
we empirically (经验) found that using a too-large kernel size
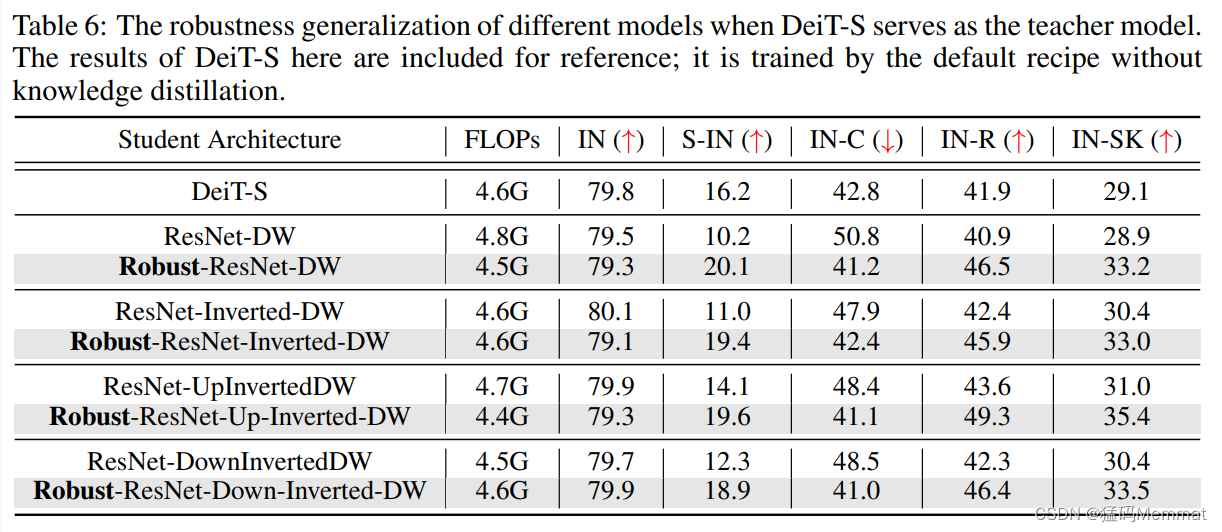
6 Knowledge Distillation
when the model roles are switched (互换), the student model DeiT-S remarkably outperforms the teacher model ResNet-50 on a range of robustness benchmarks
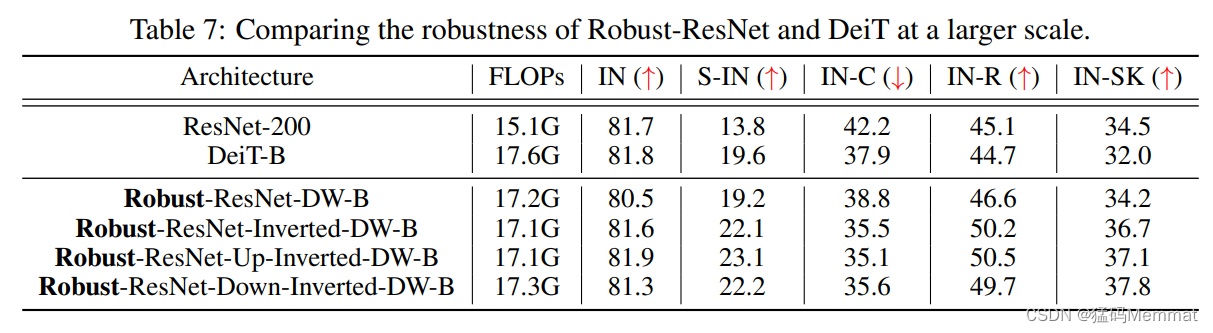
7 Larger Models
To demonstrate (演示) the effectiveness of our proposed models on larger scales
8 Conclusion
By incorporating (合并) these designs into ResNet,
we have developed a CNN architecture that can match or even surpass (超越) the robustness of a Vision Transformer model of comparable size.
We hope our findings prompt researchers to reevaluate(重新评估)the robustness comparison between Transformers and CNNs, and inspire further investigations (调查) into
developing more resilient (弹性) architecture designs
Acknowledgement
This work is supported by a gift from Open Philanthropy (慈善), TPU Research Cloud (TRC) program, and Google Cloud Research Credits program.
Reference
https://github.com/UCSC-VLAA/RobustCNN
https://arxiv.org/pdf/2206.03452.pdf
欢迎在评论区提问和讨论原Paper