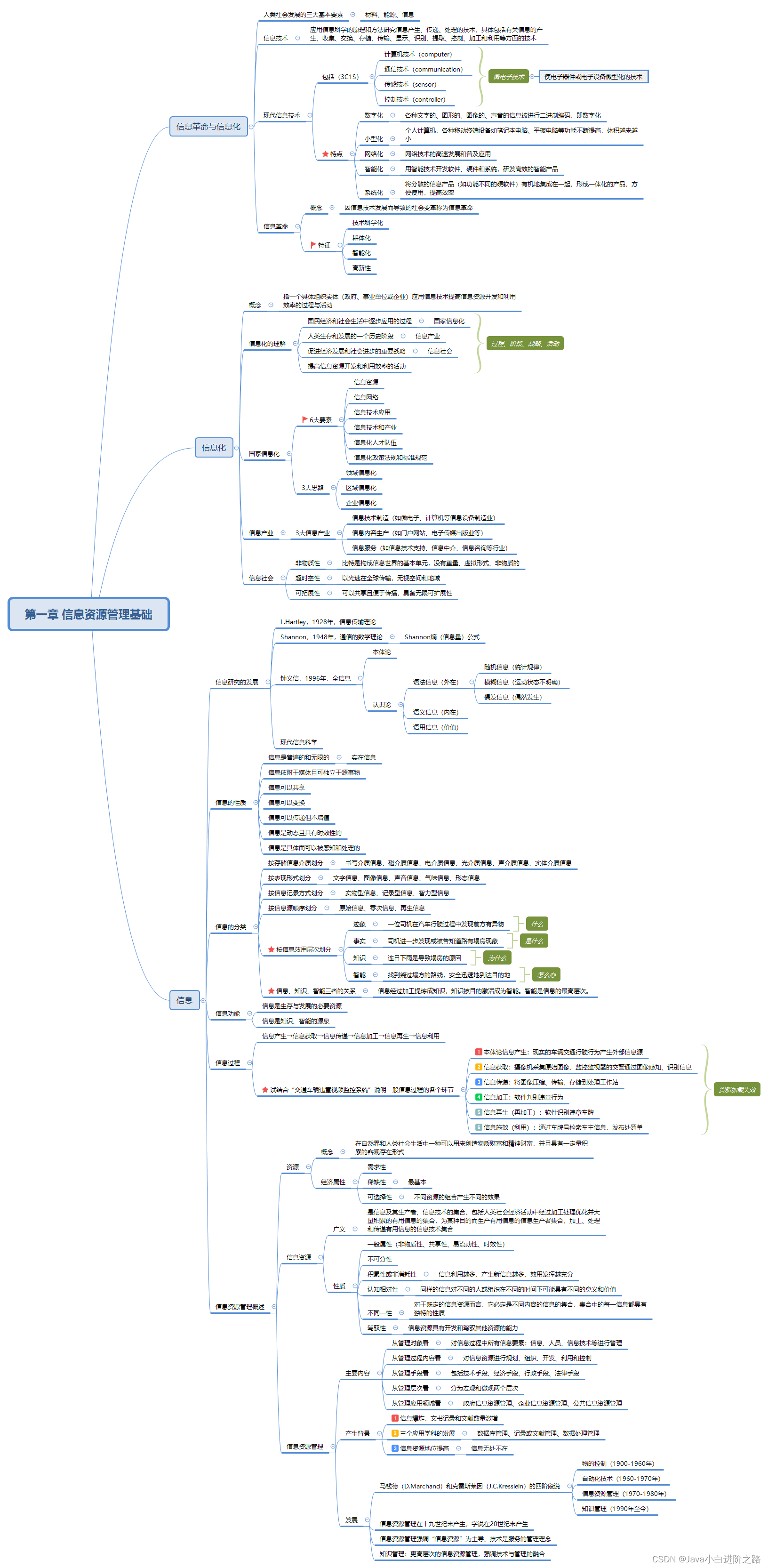
Attention函数的本质可以被描述为一个 Query 到 Key-Value对 的映射,这个映射的目的:为了给重要的部分分配更多的概率权重。
计算过程主要分为以下三步:
- 通过点乘、加法等其他办法计算 Q:query 和 每个K:key 之间的相似度
s i m ( Q , K i ) = { Q T K i (点乘注意力机制 ) v a T tanh ( W a [ Q ; K i ] ) (加法注意力机制 ) sim(Q,K_i)=\begin{cases} Q^TK_i & \text(点乘注意力机制)\\ \\ v^T_a \text{tanh}(W_a[Q; K_i]) & \text(加法注意力机制) \end{cases} sim(Q,Ki)=⎩ ⎨ ⎧QTKivaTtanh(Wa[Q;Ki])(点乘注意力机制)(加法注意力机制) - 利用Softmax函数将权重归一化
a i = s o f t m a x ( f ( Q , K i ) ) = exp ( s i m ( Q , K i ) ) ∑ j exp ( s i m ( Q , K j ) ) a_i = softmax(f(Q,K_i))=\frac{\text{exp}(sim(Q,K_i))}{\sum_j\text{exp}(sim(Q,K_j))} ai=softmax(f(Q,Ki))=∑jexp(sim(Q,Kj))exp(sim(Q,Ki)) - 最后将先前求得的 权重 a i a_i ai 分配给对应的 value并加权求和
1、点乘注意力机制 dot-product attention
点乘注意力机制是将输入序列的 hidden state 和 输出序列的hidden state相乘,即
Q
T
K
i
Q^TK_i
QTKi
scaled dot-product attention 是在点乘注意力机制的基础上,乘上一个缩放因子
1
n
\frac{1}{\sqrt{n}}
n1 ,其中
n
n
n 代表模型的维度。这个缩放因子主要目的是可以将函数值从 softmax 的饱和区 拉回到 非饱和区,这样可以防止出现梯度过小而很难学习的问题。此时 Attention机制 的表达式如下:
A
t
t
e
n
t
i
o
n
(
Q
,
K
,
V
)
=
s
o
f
t
m
a
x
(
Q
K
T
n
)
V
Attention(Q,K,V)=softmax\Bigg( \frac{QK^T}{\sqrt{n}} \Bigg)V
Attention(Q,K,V)=softmax(nQKT)V
输入分别是 Q(query) K(key) V(value)。其意义是为了用 value 求出 query的结果,需要根据 query 和 key来决定注意力应该放在 value 的哪部分。Matmul 是矩阵乘法,Mask 是为了确保预测位置 i i i 的时候仅仅依赖于位置小于 i i i 的输出,确保预测第 i i i 个位置时不会接触到未来的信息。
Attention_22">2、多头注意力机制 MultiHead Attention
多头注意力机制是基于 scaled dot-product attention 而产生的,其原理非常简单,就是把 Q , K , V Q,K,V Q,K,V 进行线性变换的参数 W W W 是不一样的。
h e a d i = A t t e n t i o n ( Q W i Q , K W i K , V W i V ) M u l t i h e a d ( Q , K , V ) = C o n c a t ( h e a d 1 , . . . , h e a d n ) W O head_i = Attention(QW_i^Q, KW_i^K, VW_i^V) \\ Multihead(Q,K,V) = Concat(head_1,...,head_n)W^O headi=Attention(QWiQ,KWiK,VWiV)Multihead(Q,K,V)=Concat(head1,...,headn)WO
自注意力机制就是 K = V = Q K=V=Q K=V=Q 的特殊情况,
Code
import numpy as np
import torch
from torch import nn
from torch.nn import init
class ScaledDotProductAttention(nn.Module):
'''
Scaled dot-product Attention
'''
def __init__(self, d_model, d_k, d_v, h,dropout=.1):
'''
:param d_model: Output dimensionality of the model
:param d_k: Dimensionality of queries and keys
:param d_v: Dimensionality of values
:param h: Number of heads
'''
super(ScaledDotProductAttention, self).__init__()
self.fc_q = nn.Linear(d_model, h * d_k)
self.fc_k = nn.Linear(d_model, h * d_k)
self.fc_v = nn.Linear(d_model, h * d_v)
self.fc_o = nn.Linear(h * d_v, d_model)
self.dropout=nn.Dropout(dropout)
self.d_model = d_model
self.d_k = d_k
self.d_v = d_v
self.h = h
self.init_weights()
def init_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
init.kaiming_normal_(m.weight, mode='fan_out')
if m.bias is not None:
init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
init.constant_(m.weight, 1)
init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
init.normal_(m.weight, std=0.001)
if m.bias is not None:
init.constant_(m.bias, 0)
def forward(self, queries, keys, values, attention_mask=None, attention_weights=None):
'''
Computes
:param queries: Queries (b_s, nq, d_model)
:param keys: Keys (b_s, nk, d_model)
:param values: Values (b_s, nk, d_model)
:param attention_mask: Mask over Attention values (b_s, h, nq, nk). True indicates masking.
:param attention_weights: Multiplicative weights for Attention values (b_s, h, nq, nk).
:return:
'''
b_s, nq = queries.shape[:2]
nk = keys.shape[1]
q = self.fc_q(queries).view(b_s, nq, self.h, self.d_k).permute(0, 2, 1, 3) # (b_s, h, nq, d_k)
k = self.fc_k(keys).view(b_s, nk, self.h, self.d_k).permute(0, 2, 3, 1) # (b_s, h, d_k, nk)
v = self.fc_v(values).view(b_s, nk, self.h, self.d_v).permute(0, 2, 1, 3) # (b_s, h, nk, d_v)
att = torch.matmul(q, k) / np.sqrt(self.d_k) # (b_s, h, nq, nk)
if attention_weights is not None:
att = att * attention_weights
if attention_mask is not None:
att = att.masked_fill(attention_mask, -np.inf)
att = torch.softmax(att, -1)
att=self.dropout(att)
out = torch.matmul(att, v).permute(0, 2, 1, 3).contiguous().view(b_s, nq, self.h * self.d_v) # (b_s, nq, h*d_v)
out = self.fc_o(out) # (b_s, nq, d_model)
return out
if __name__ == '__main__':
input=torch.randn(7,65,512)
sa = ScaledDotProductAttention(d_model=512, d_k=512, d_v=512, h=8)
output=sa(input,input,input)
print(output.shape)