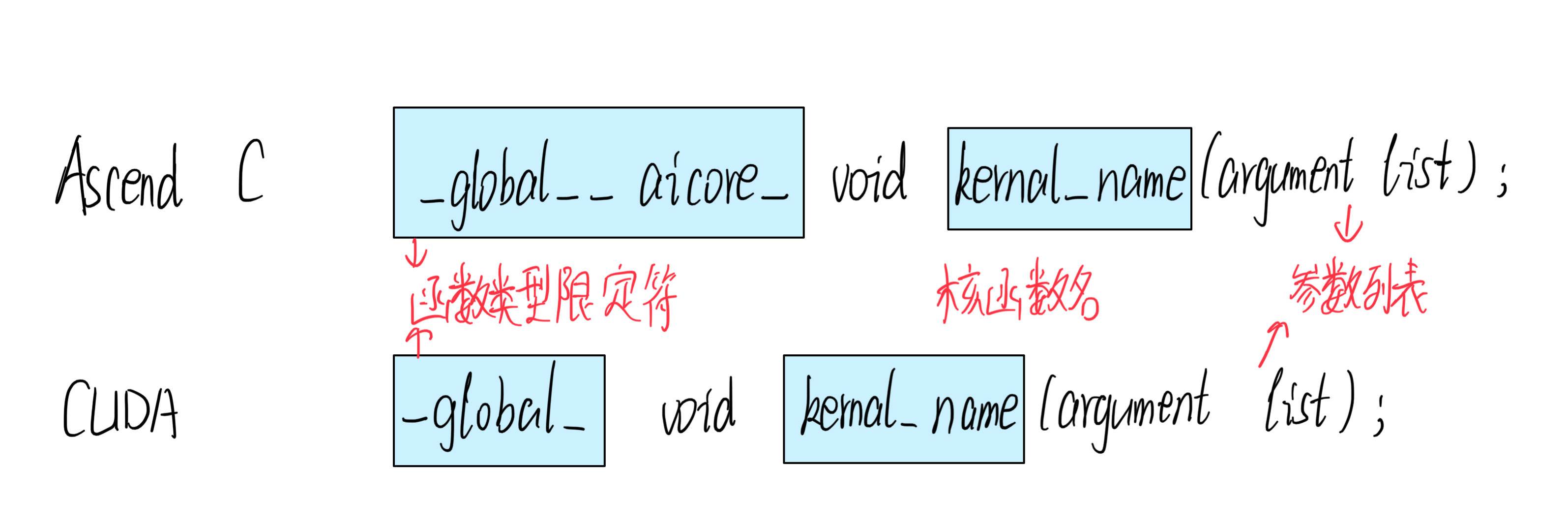
1 Transformer的并行计算
对于Transformer比传统序列模型RNN/LSTM具备优势的第一大原因就是强大的并行计算能力.
- 对于RNN来说,任意时刻t的输入是时刻t的输入x(t)和上一时刻的隐藏层输出h(t-1),经过运算后得到当前时刻隐藏层的输出h(t),这个h(t)也即将作为下一时刻t+1的输入的一部分。
- 以上计算过程是RNN的本质特征,RNN的历史信息是需要通过这个时间步一步一步向后传递的。而这就意味着RNN序列后面的信息只能等到前面的计算结束后,将历史信息通过hidden state传递给后面才能开始计算,形成链式的序列依赖关系,无法实现并行。
- 对于Transformer结构来说, 在self-attention层, 无论序列的长度是多少, 都可以一次性计算所有单词之间的注意力关系,这个attention的计算是同步的,可以实现并行。
transformer">2 Transformer架构的并行化过程
transformerencoder">2.1 Transformer架构中Encoder的并行化
首先Transformer的并行化主要体现在Encoder模块上
-
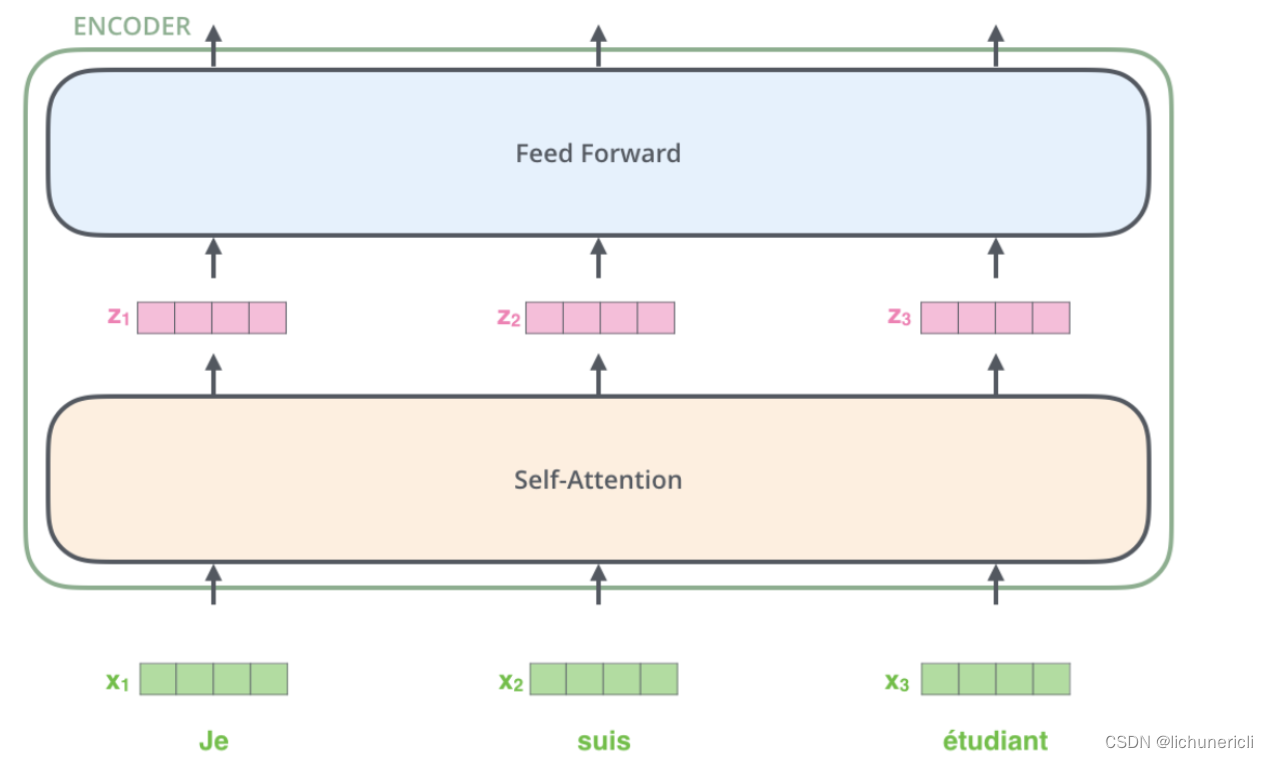
上图最底层绿色的部分, 整个序列所有的token可以并行的进行Embedding操作, 这一层的处理是没有依赖关系的.
-
上图第二层土黄色的部分, 也就是Transformer中最重要的self-attention部分, 这里对于任意一个单词比如x1, 要计算x1对于其他所有token的注意力分布, 得到z1. 这个过程是具有依赖性的, 必须等到序列中所有的单词完成Embedding才可以进行. 因此这一步是不能并行处理的. 但是从另一个角度看, 我们真实计算注意力分布的时候, 采用的都是矩阵运算, 也就是可以一次性的计算出所有token的注意力张量, 从这个角度看也算是实现了并行, 只是矩阵运算的"并行"和词嵌入的"并行"概念上不同而已.
-
上图第三层蓝色的部分, 也就是前馈全连接层, 对于不同的向量z之间也是没有依赖关系的, 所以这一层是可以实现并行化处理的. 也就是所有的向量z输入Feed Forward网络的计算可以同步进行, 互不干扰.
transformerdecoder">2.2 Transformer架构中Decoder的并行化
其次Transformer的并行化也部分的体现在Decoder模块上.
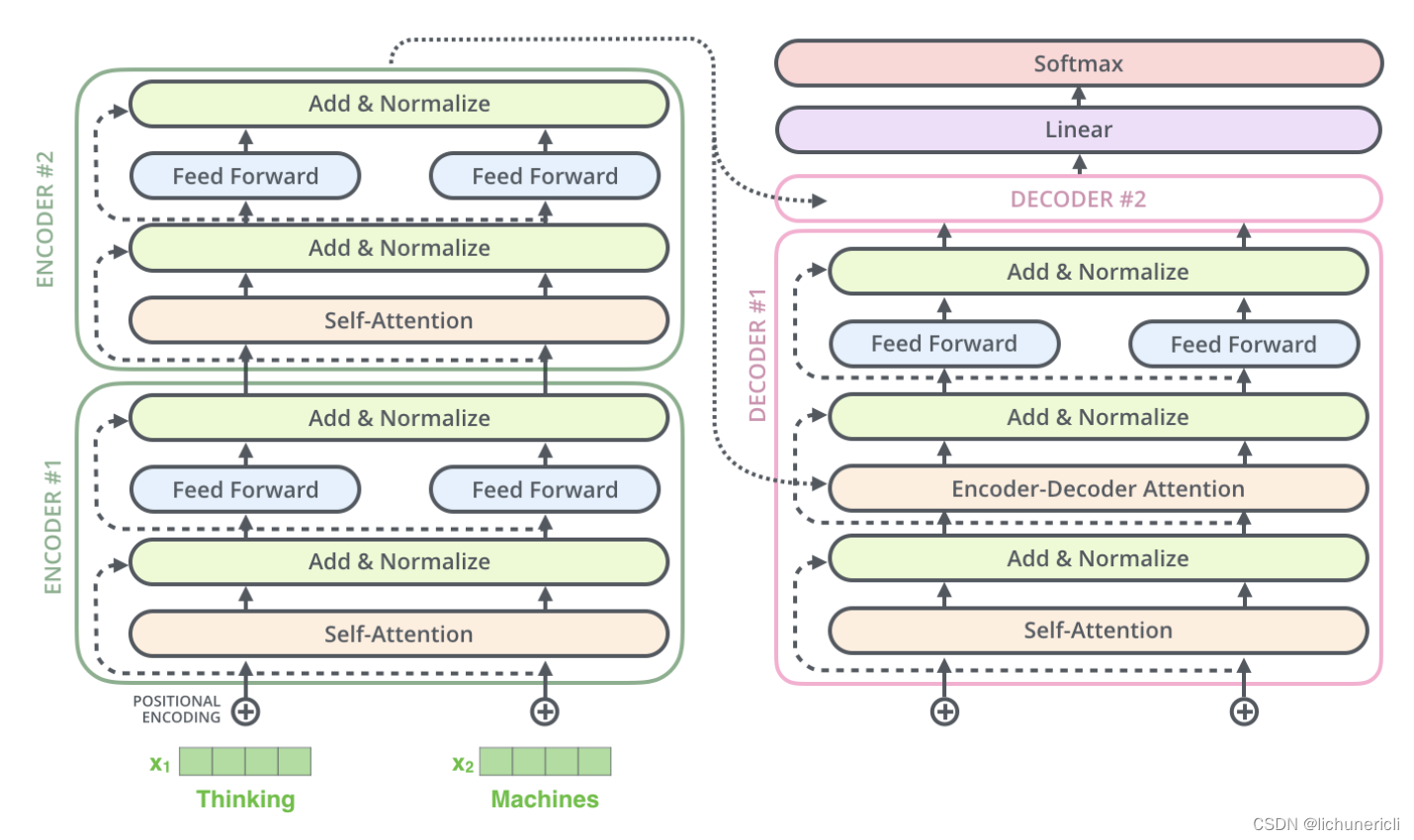
-
Decoder模块在训练阶段采用了并行化处理. 其中Self-Attention和Encoder-Decoder Attention两个子层的并行化也是在进行矩阵乘法, 和Encoder的理解是一致的. 在进行Embedding和Feed Forward的处理时, 因为各个token之间没有依赖关系, 所以也是可以完全并行化处理的, 这里和Encoder的理解也是一致的.
-
Decoder模块在预测阶段基本上不认为采用了并行化处理. 因为第一个time step的输入只是一个"SOS", 后续每一个time step的输入也只是依次添加之前所有的预测token.
-
注意: 最重要的区别是训练阶段目标文本如果有20个token, 在训练过程中是一次性的输入给Decoder端, 可以做到一些子层的并行化处理. 但是在预测阶段, 如果预测的结果语句总共有20个token, 则需要重复处理20次循环的过程, 每次的输入添加进去一个token, 每次的输入序列比上一次多一个token, 所以不认为是并行处理.
transformer">3 Transformer的特征抽取能力
对于Transformer比传统序列模型RNN/LSTM具备优势的第二大原因就是强大的特征抽取能力.
- Transformer因为采用了Multi-head Attention结构和计算机制, 拥有比RNN/LSTM更强大的特征抽取能力, 这里并不仅仅由理论分析得来, 而是大量的试验数据和对比结果, 清楚的展示了Transformer的特征抽取能力远远胜于RNN/LSTM.
- 注意: 不是越先进的模型就越无敌, 在很多具体的应用中RNN/LSTM依然大有用武之地, 要具体问题具体分析.
transformerseq2seq">4 Transformer可以代替seq2seq
4.1 seq2seq的两大缺陷
-
seq2seq架构的第一大缺陷是将Encoder端的所有信息压缩成一个固定长度的语义向量中, 用这个固定的向量来代表编码器端的全部信息. 这样既会造成信息的损耗, 也无法让Decoder端在解码的时候去用注意力聚焦哪些是更重要的信息.
-
seq2seq架构的第二大缺陷是无法并行, 本质上和RNN/LSTM无法并行的原因一样.
transformer">4.2 Transformer的改进
- Transformer架构同时解决了seq2seq的两大缺陷, 既可以并行计算, 又应用Multi-head Attention机制来解决Encoder固定编码的问题, 让Decoder在解码的每一步可以通过注意力去关注编码器输出中最重要的那些部分.
5 小结
- Transformer相比于RNN/LSTM的优势和原因.
- 第一大优势是并行计算的优势.
- 第二大优势是特征提取能力强.
- Transformer架构中Encoder模块的并行化机制.
- Encoder模块在训练阶段和测试阶段都可以实现完全相同的并行化.
- Encoder模块在Embedding层, Feed Forward层, Add & Norm层都是可以并行化的.
- Encoder模块在self-attention层, 因为各个token之间存在依赖关系, 无法独立计算, 不是真正意义上的并行化.
- Encoder模块在self-attention层, 因为采用了矩阵运算的实现方式, 可以一次性的完成所有注意力张量的计算, 也是另一种"并行化"的体现.
-
Transformer架构中Decoder模块的并行化机制.
- Decoder模块在训练阶段可以实现并行化.
- Decoder模块在训练阶段的Embedding层, Feed Forward层, Add & Norm层都是可以并行化的.
- Decoder模块在self-attention层, 以及Encoder-Decoder Attention层, 因为各个token之间存在依赖关系, 无法独立计算, 不是真正意义上的并行化.
- Decoder模块在self-attention层, 以及Encoder-Decoder Attention层, 因为采用了矩阵运算的实现方式, 可以一次性的完成所有注意力张量的计算, 也是另一种"并行化"的体现.
- Decoder模块在预测计算不能并行化处理.
-
seq2seq架构的两大缺陷.
- 第一个缺陷是Encoder端的所有信息被压缩成一个固定的输出张量, 当序列长度较长时会造成比较严重的信息损耗.
- 第二个缺陷是无法并行计算.
-
Transformer架构对seq2seq两大缺陷的改进.
- Transformer应用Multi-head Attention机制让编码器信息可以更好的展示给解码器.
- Transformer可以实现Encoder端的并行计算.