几十年来,理论物理学家一直在努力提出一个宏大的统一理论。通过统一,指的是将被认为是完全不同的两个或多个想法结合起来,将它们的不同方面证明为同一基础现象。一个例子是在19世纪之前,电和磁被看作是无关的现象,但电磁学理论成功地解释了它们,或以某种方式将这两种看似不同的现象统一起来。每当物理学家成功地将一组看似无关的东西统一起来,他们都会得到一个更强大的理论,可以解释更多内容,并且用更少的方法来实现。
我们在谈论计算机视觉时,为什么要谈论物理学呢?在人工智能领域也有类似的“统一”目标。在自然语言处理(NLP)领域,主导的建模架构是Transformer,而在计算机视觉领域,主要是卷积神经网络。然而,近年来情况发生了变化。NLP和CV能否通过基于Transformer的架构实现统一?让我们来看看!
什么是Transformer?
它有两个部分,前馈网络和自注意力。我们不会详细介绍自注意力,但在高层次上,它会将每个令牌与每个其他令牌进行比较,从而将运行时间提高到O(n**2)。总体目标是将n个令牌嵌入输入,并返回n个上下文丰富的嵌入。这个想法进一步形成了广泛使用的多头自注意力(MHSA),其在不同的输入令牌部分上并行使用了多组Q、K和V矩阵。然后在传递到MLP之前将产生的集合连接起来。这种技术非常有效,因为不同的头可以关注令牌之间的短程和长程关系,或者语义和句法关系。
您可能会问,如果这么好用,为什么我们不尝试用MHSA层替换卷积层,看看它是否做得更好?
这正是他们在这篇名为“Bottleneck Transformers for Visual Recognition”的论文中所做的。直接从论文的摘要中提取:“仅通过在ResNet的最后三个瓶颈块中将空间卷积替换为全局自注意,而不进行其他更改,我们的方法在实例分割和物体检测上显著改进了基线,同时减少了参数,延迟的开销最小。”这是多么惊人的事情啊!
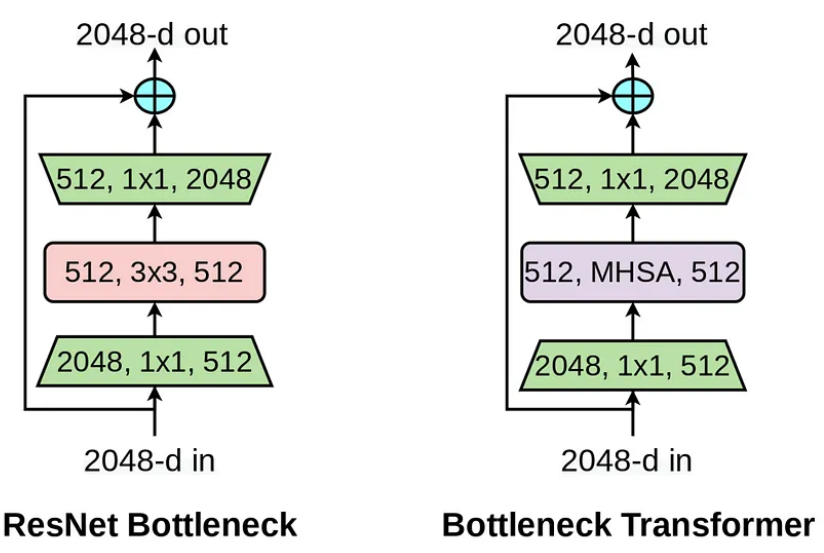
唯一的区别是将3 × 3卷积层替换为MHSA
这可以通过直观地解释来解释,即左上角的感受野和右下角的感受野可能只在堆叠多个卷积层之后才能进行交互。在后期之前,没有全局交互。仅仅堆叠越来越多的层并不是真正需要的,而是需要一种明确的机制来建模全局依赖性,这就是MHSA在这里引入的新变化。
在NLP任务中,建模长程依赖性至关重要,我们很久以来都已经意识到了这一点,但是视觉领域一直只使用卷积,因为我们具有(附近像素比远处像素更重要)的局部性和平移不变性偏见。似乎在架构的某个地方,包含全局交互可以产生奇迹。BoTNET论文谈到了它是一个以CNN为基础的架构,在骨干部分中使用了自注意力。DETR模型(目标检测模型)具有基于CNN的骨干和顶部的变换块。但是,是否可以完全使用Transformer而不使用卷积来构建视觉系统呢?让我们来看看!
ViT
Google发表了一篇名为“一个图像值16x16个单词”的论文,在论文中,出现了一个视觉架构,里面没有一个卷积。一个256x256的图像有成千上万个像素,将每个像素制作成一个令牌,然后在自我关注步骤中使用,这在二次时间内根本不可行。因此,作者采取了将图像分成补丁并将它们通过线性层传递的方法,从而创建出每个补丁的扁平化嵌入,并在后续的变换步骤中使用它们。
从某种意义上说,Transformers缺乏CNN在图像类型数据设计中具有的归纳偏见。它们在将每个令牌与每个其他令牌进行比较方面非常通用,并且没有关于附近像素的任何信息。因此,位置嵌入被添加到线性投影中。即使在这些嵌入中,作者还表明更详细的二维嵌入与一维嵌入没有真正的收益,这显示了这种架构随着时间的推移学习位置的准确性。
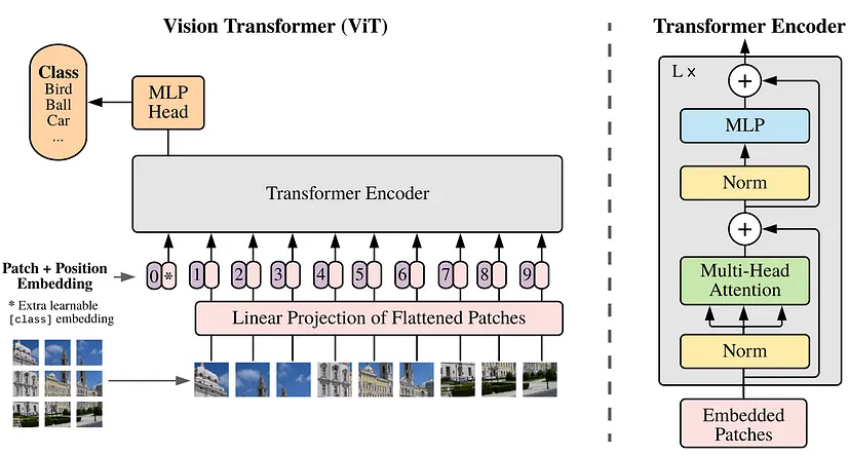
ViT架构,如原始论文所示
论文链接:https://arxiv.org/pdf/2101.11605.pdf
· END ·
HAPPY LIFE

本文仅供学习交流使用,如有侵权请联系作者删除