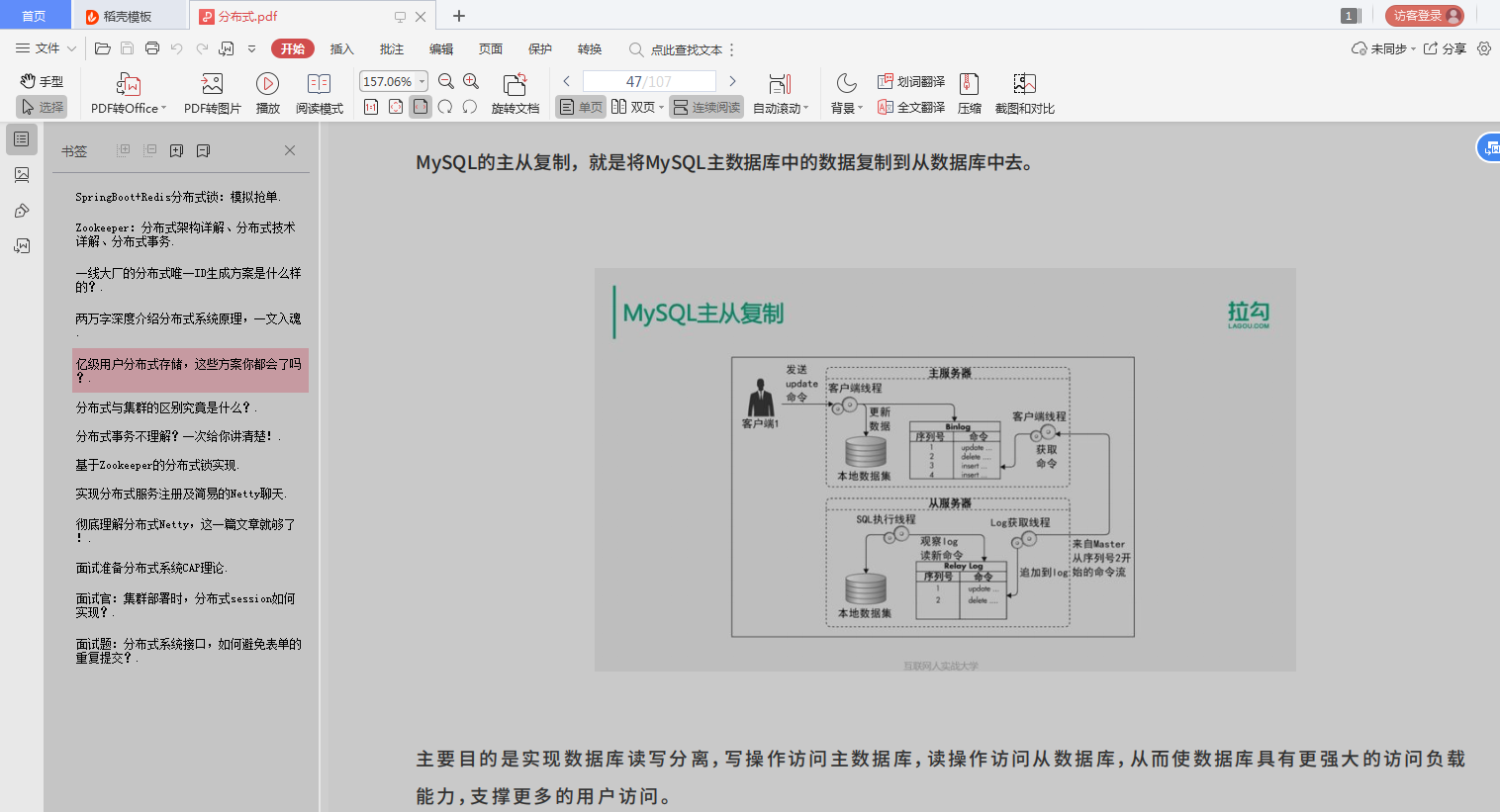
GA-GRU遗传算法优化门控循环单元多变量时间序列预测是一个比较复杂的问题,需要一定的编程和数学基础。下面是一个简单的Python实现,供参考:
首先,我们需要导入相关的库:
```python
import numpy as np
import pandas as pd
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, GRU, Dropout
from tensorflow.keras.optimizers import Adam
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import mean_squared_error
import random
```
然后,我们需要定义一些常量和超参数:
```python
# 数据集路径
data_path = 'data.csv'
# 时间步长
time_steps = 24
# 预测步长
pred_steps = 1
# 隐藏层神经元数量
hidden_units = 32
# 学习率
learning_rate = 0.001
# 迭代次数
epochs = 100
# 种群大小
population_size = 10
# 交叉概率
crossover_rate = 0.8
# 变异概率
mutation_rate = 0.1
# 变异范围
mutation_range = 0.1
```
接着,我们需要读取数据集,并进行预处理:
```python
# 读取数据集
data = pd.read_csv(data_path)
# 将时间戳转换为日期格式
data['date'] = pd.to_datetime(data['date'])
# 将日期作为索引
data.set_index('date', inplace=True)
# 对数据进行归一化
scaler = MinMaxScaler()
data = scaler.fit_transform(data)
# 将数据集划分为训练集和测试集
train_size = int(len(data) * 0.8)
train_data = data[:train_size]
test_data = data[train_size:]
```
接下来,我们需要定义一个函数来生成初始种群:
```python
def generate_population(population_size):
population = []
for i in range(population_size):
# 随机生成每个基因的权重
weights = {
'input': np.random.uniform(-1, 1, (train_data.shape[1], hidden_units)),
'recurrent': np.random.uniform(-1, 1, (hidden_units, hidden_units)),
'bias': np.random.uniform(-1, 1, (hidden_units,))
}
population.append(weights)
return population
```
然后,我们需要定义一个函数来计算每个个体的适应度:
```python
def calculate_fitness(individual):
# 构建模型
model = Sequential([
GRU(hidden_units, input_shape=(time_steps, train_data.shape[1]), recurrent_initializer='glorot_uniform',
recurrent_activation='sigmoid', recurrent_dropout=0, unroll=False, use_bias=True),
Dropout(0.2),
Dense(train_data.shape[1])
])
model.compile(optimizer=Adam(learning_rate), loss='mse')
# 设置权重
model.layers[0].set_weights([individual['input'], individual['recurrent'], individual['bias']])
# 训练模型
history = model.fit(train_X, train_y, epochs=epochs, verbose=0)
# 计算适应度
y_pred = model.predict(test_X)
mse = mean_squared_error(test_y, y_pred)
fitness = 1 / (mse + 1e-6)
return fitness
```
接下来,我们需要定义一个函数来进行选择操作:
```python
def selection(population):
fitness = [calculate_fitness(individual) for individual in population]
total_fitness = sum(fitness)
probabilities = [f / total_fitness for f in fitness]
selected_population = []
for i in range(population_size):
selected_individual = random.choices(population, probabilities)[0]
selected_population.append(selected_individual)
return selected_population
```
然后,我们需要定义一个函数来进行交叉操作:
```python
def crossover(parent1, parent2):
child1 = {
'input': np.zeros_like(parent1['input']),
'recurrent': np.zeros_like(parent1['recurrent']),
'bias': np.zeros_like(parent1['bias'])
}
child2 = {
'input': np.zeros_like(parent2['input']),
'recurrent': np.zeros_like(parent2['recurrent']),
'bias': np.zeros_like(parent2['bias'])
}
for i in range(train_data.shape[1]):
for j in range(hidden_units):
if random.random() < crossover_rate:
child1['input'][i][j] = parent2['input'][i][j]
child2['input'][i][j] = parent1['input'][i][j]
else:
child1['input'][i][j] = parent1['input'][i][j]
child2['input'][i][j] = parent2['input'][i][j]
for i in range(hidden_units):
for j in range(hidden_units):
if random.random() < crossover_rate:
child1['recurrent'][i][j] = parent2['recurrent'][i][j]
child2['recurrent'][i][j] = parent1['recurrent'][i][j]
else:
child1['recurrent'][i][j] = parent1['recurrent'][i][j]
child2['recurrent'][i][j] = parent2['recurrent'][i][j]
for i in range(hidden_units):
if random.random() < crossover_rate:
child1['bias'][i] = parent2['bias'][i]
child2['bias'][i] = parent1['bias'][i]
else:
child1['bias'][i] = parent1['bias'][i]
child2['bias'][i] = parent2['bias'][i]
return child1, child2
```
接下来,我们需要定义一个函数来进行变异操作:
```python
def mutation(individual):
mutated_individual = {
'input': np.copy(individual['input']),
'recurrent': np.copy(individual['recurrent']),
'bias': np.copy(individual['bias'])
}
for