目录
- 自然语言模型发展历程
- 2003 年 Bengio 提出神经网络语言模型 NNLM,统一了 NLP 的特征形式——Embedding;
- 2013 年 Mikolov 提出词向量 Word2vec,延续 NNLM 又引入了大规模预训练(Pretrain)的思路;
- 2017 年 Vaswani 提出 Transformer 模型,实现用一个模型处理多种 NLP 任务。
- 发展
- 模型介绍
- Transformer
- 基础
- Transformer 结构
- GPT
- Bert
- 模型小结
- References
自然语言模型发展历程
2003 年 Bengio 提出神经网络语言模型 NNLM,统一了 NLP 的特征形式——Embedding;
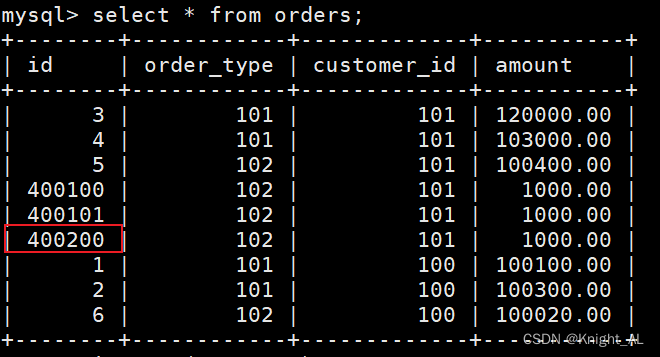
学习任务是输入某个句中"Bert"单词前面句子的 t-1 个单词,要求网络正确预测单词 Bert,即最大化:
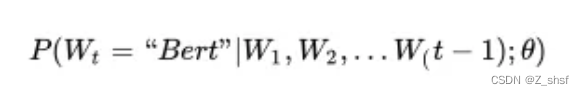
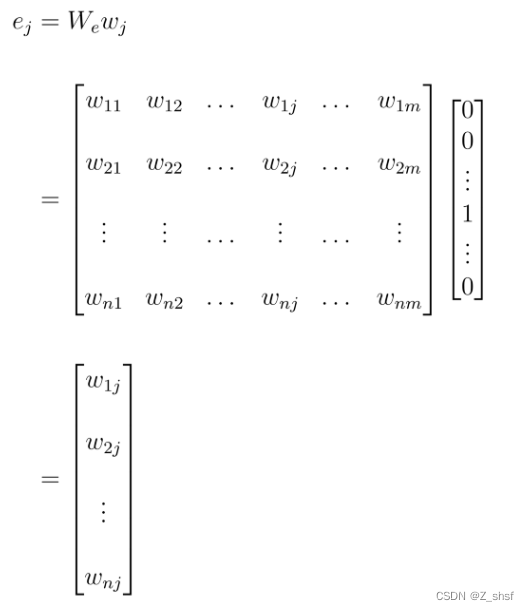
前面任意单词W用One-hot编码(比如:0001000)作为原始单词输入,之后乘以矩阵 Q 后获得向量,每个单词的拼接,上接隐层,然后接 softmax 去预测后面应该后续接哪个单词。这其实就是单词对应的 Word Embedding 值,那个矩阵 Q 包含 V 行,V 代表词典大小,每一行内容代表对应单词的 Word embedding 值。只不过 Q 的内容也是网络参数,需要学习获得,训练刚开始用随机值初始化矩阵 Q,当这个网络训练好之后,矩阵 Q 的内容被正确赋值,每一行代表一个单词对应的 Word embedding 值。[更详细的解释在后文介绍模型时会再讲]
2013 年 Mikolov 提出词向量 Word2vec,延续 NNLM 又引入了大规模预训练(Pretrain)的思路;
Word2Vec 有两种训练方法,1. CBOW,核心思想是从一个句子里面把一个词抠掉,用这个词的上文和下文去预测被抠掉的这个词;2. Skip-gram,和 CBOW 正好反过来,输入某个单词,要求网络预测它的上下文单词。使用 Word2Vec 或者 Glove(后面出的类似工具),通过做语言模型任务,就可以获得每个单词的 Word Embedding
2017 年 Vaswani 提出 Transformer 模型,实现用一个模型处理多种 NLP 任务。
Transformer 是个叠加的“自注意力机制(Self Attention)”构成的深度网络,是目前 NLP 里最强的特征提取器
基于 Transformer 架构,2018 年底开始出现一大批预训练语言模型,刷新众多 NLP 任务,形成新的里程碑事件。3 个预训练代表性模型 BERT、XLNet 和 MPNet。
Bert
BERT 本质上是一个自编码(Auto Encoder)语言模型,使用 3 亿多词语训练,采用 12 层双向 Transformer 架构。注意,BERT 只使用了 Transformer 的编码器部分,可以理解为 BERT 旨在学习庞大文本的内部语义信息。由于架构采用 12 层双向 Transformer 且训练目标包含还原mask 位置的信息,BERT 被称为去噪自编码语言模型(DAE)。而在 BERT 之前,NLP 领域的语言模型几乎是 Auto Regression(自回归)类型,即当前位置的字符预测Ti需要编码之前T(0:i-1) tokens 的语义信息,使得模型训练 / 预测只能单向进行。具体训练目标之一,是被称为掩码语言模型的 MLM。即输入一句话,给其中 15% 的字打上 “mask” 标记,经过 Embedding 输入和 12 层 Transformer 深度理解,来预测 “mask” 标记的地方原本是哪个字。虽然效果好,BERT 的缺点也很明显。从建模本身来看,随机选取 15% 的字符 mask 忽视了被 mask 字符之间可能存在语义关联的现象,从而丢失了部分上下文信息。同时,微调阶段没有 mask 标记,导致预训练与微调的不一致。
XLNet 原理及 PLM 简述
和 BERT 不同,XLNet 本质上是用自回归语言模型来同时编码双向语义信息的思路,可以克服 BERT 存在的依赖缺失和训练 / 微调不一致的问题。同时为了弥补自回归模型训练时无法同时看到上下文的缺陷,XLNet 提出了 PLM 排列语言模型的训练方式。
PLM,排列语言模型 - Permutation Language Model, 对于一个长度为 N 的序列,我们知道其存在N! 种因式分解顺序,通过一次采样一种序列的因式分解组合,每个 token 总是能够在不同的序列中观察到其他所有 token;同时模型参数对于所有的因式分解顺序共享,因此从期望的角度上看,XLNet 模型能够双向地编码上下文。
那 XLNet 是如何在保持输入顺序不变的同时,对序列进行乱序编码的呢?通过 Attention 掩码机制,将当前 token 及其之后的 token(不该看到的部分)嵌入信息用 attention-mask 掩盖。具体实现上,使用了一种双流自注意力机制。
XLNET 将自注意力机制拆分为 Query 流和 Content 流。Query 流中当前 token 只能关注到前面的 token 和自身的位置信息,Content 流中当前 token 可以关注到自身。具体来看,XLNET 将序列拆分为 2 部分,序列的后部分(约占句长的 1/K,K 为超参数)为需要预测的部分,前部分为已知上下文。已知的上下文不做预测,因此只计算 content 流注意力,每个 token 都编码之前 token 以及自身的完整信息。从预测部分开始,每个 token 同时计算 Query 流和 Content 流注意力:Query 流的输出用于预训练做预测,Content 流的输出提供给后续待预测 token 计算 Query 流,这就保证了当预测当前 token 时,它无法看到自身编码;当前 token 预测结束后,将其 Content 流作为上下文部分的编码提供给后续需要预测的 token。预训练过程计算 2 种注意力,微调过程去除了 Query 流,只保留 Content 流,因为不需要对 token 进行词表空间的预测,而是需要编码整个上下文语义用于下游任务。
前面提到 Auto Regression 模型的缺点是只能单向编码,但它能够编码被预测的 token 之间的联系,即克服了 BERT 被 mask 字符间信息丢失的缺点。其次,通过上文的 PLM 模型弥补了自回归语言模型只能单向编码的缺点。AR 模型在预训练和下游任务中都没有对输入序列进行损坏(遮盖部分 token,引入噪声),消除了模型在预训练和微调过程中的差异。
虽然在期望上看,PLM 几乎实现了双向编码功能的自回归模型,但是针对某一个因式分解序列来说,被预测的 token 依然只能关注到它前面的序列,导致模型依然无法看到完整序列信息和位置信息
MPNet:Masked and Permuted Pre-training for Language Understanding
MPNet 的创新点在于位置补偿(position compensation)首先,作者通过重新排列和切分输入序列中的 tokens,将 MLM 和 PLM 统一为非预测部分(non-predicted)和预测部分(predicted),为缓解 BERT-mask 可能丢失依赖信息的问题,MPNet 沿用了 XLNet 的自回归结构,同时为弥补 XLNet 无法捕捉全部序列位置信息的缺陷,添加了「位置补偿」:针对需要预测的 token,额外添加了它们的位置信息。使得自回归过程中,在任意一个位置 i,除了可以看到之前部分的 token 编码,还能看到序列所有 token 的位置编码(类似于 BERT)。
MPNet 使用自回归编码,避免了 BERT 做 Mask 时可能丢失被 Mask 的 token 的彼此关联信息和 pretrain(有 mask)、finetune(无 mask)不一致的问题;通过位置补偿,又解决了 XLNet 无法看到全局位置信息的缺陷。
发展
前期 BERT 到 RoBERTa,GPT 到 GPT2 效果的提升,已经证明更多数据可以跑出更强大更通用的预训练模型。近年来英伟达、谷歌、Open-AI 相继放出大模型 MegatronLM(83 亿参数)、T5(110 亿)、GPT3(1500 亿),GPT3有1750亿个参数(1.75e+11),GPT4有超过100万亿个参数(1e+15)
模型介绍
Transformer
基础
如果从头开始构建模型,则需要决定如何对句子进行标记化,设置词汇集,并为每个标记分配索引。概率语言模型给出了下一个单词之前的单词序列来预测下一个单词。例如

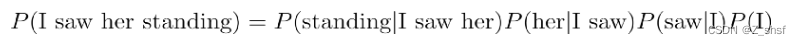
考虑到词汇量大(英文 100000 不仅包括单词,还包括标点符号和特殊字符)计算联合概率维数过高,语言模型中的另一个困难是有些词表达了相似的意思。当模型预测下一个单词时,相似的单词应该有相似的概率。 如果我们使用one-hot向量来表示每个单词,那么每个单词就会彼此独立。此外,我们需要向量的大小与词汇表中的单词数相同,维数太大。因此定义了一个转化矩阵(embeding matrix),将高维的vector转换到低维上。
此外,相似的单词会有更高的相似度(余弦相似度),我们可以通过两个单词向量之间的点积来计算。它们有相似的权重,因为相似的单词应该对联合概率计算有相似的影响。
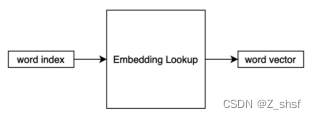
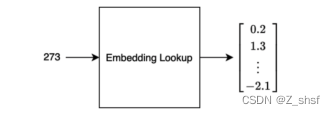
这种词表示方式为“分布式表示”,而不是局部表示(即单一热表示)。在嵌入矩阵(层)的实际实现中,我们只是根据单词index在矩阵中查找一个向量。因此,有时称这种操作为“embedding lookup”。
具有相似语义、意义和语法角色的单词具有相似的特征向量。由于概率函数是这些特征值的函数,特征的小变化只会引起概率的小变化。使用embedded lookup,自由参数的数量(矩阵权重)仅与词汇表中的单词数量成线性比例。相同的嵌入向量用于相同的单词,而不管它们在句子中的哪个位置,因此解决了维数过高的问题。
Transformer 结构

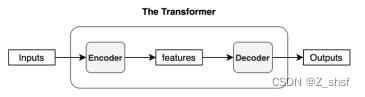
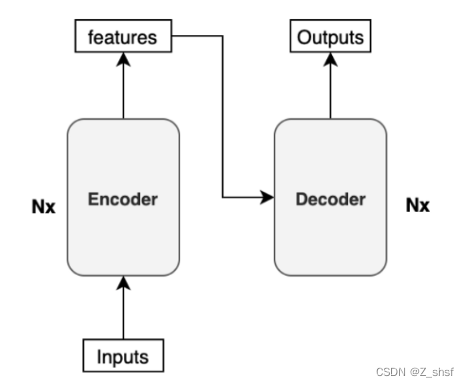
encoder和decoder 是由多个enc/dec blocks组成的,假设有N个,用Nx标识,则模型为
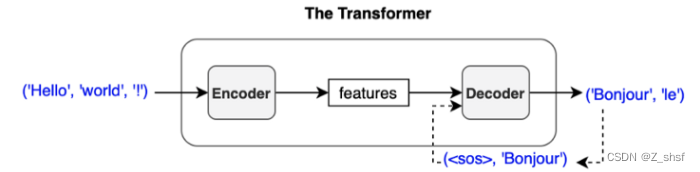
Sentence -> distinct elements(tokens)->embedding vector作为encoder输入
这里的重点是转换器的输入不是输入文本的字符,而是embedded vectors。每个向量表示一个标记的语义和位置。编码器对这些向量执行线性代数运算,从整个句子中提取每个标记的上下文,并通过多个编码器块为目标任务丰富嵌入向量的有用信息。
重复上面过程,直到
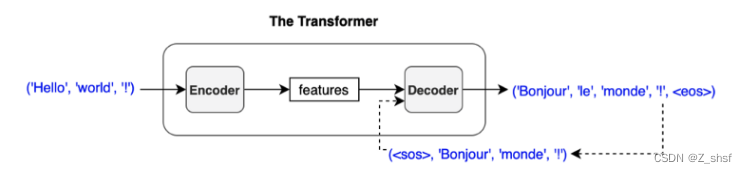
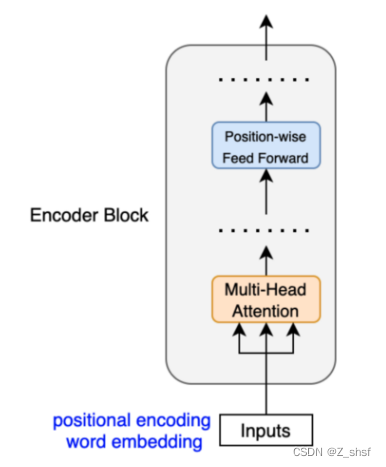
编码器块使用自注意机制,用整个句子的上下文信息来丰富每个标记(embeding vector)。
Self-attention机制
自注意力机制重点在于学习输入序列自身的内部信息。具体地,每个token 可以观察到序列中其他所有token 的信息,并通过” 注意力 “交互,其余的token会产生不同大小地权重(整个过程类似加权)。最终自注意力层的输出涵盖了序列所有token 的语义信息,实现了双向编码上下文。同时,这种双向性使得模型可以同时观测序列的所有位置,解决了 RNN 等递归模型无法高效并行的瓶颈。
根据周围的标记,每个标记可以有多个语义和/或功能。因此,自注意机制采用多个头部(8个并行注意计算),以便模型可以挖掘不同的嵌入子空间。Multi-Head Attention
位置前馈网络(FFN)有一个线性层ReLU和另一个线性层,它以相同的权重独立处理每个embeding vector。因此,每个embeding vector(带有来自多头注意力的上下文信息)都要经过位置前馈层进行进一步转换。 Position-wise Feed Forward
x表示embeding vector 则FFN网络表示为:
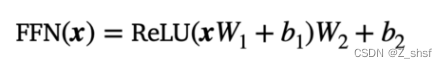
Encoder 和encoder之间用residual connections 联接,并每层做一次归一化,
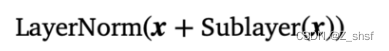
因此 encoder的结构为:
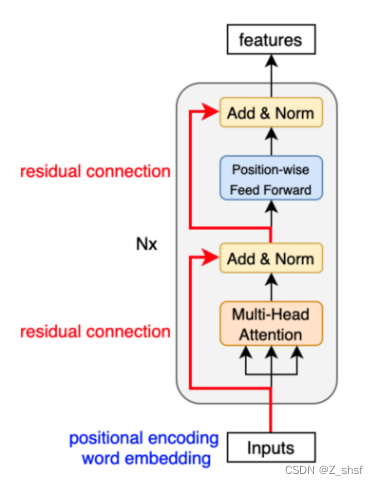
Transformer 整体架构:
 transformer" />
transformer" />
GPT_78">GPT
Generative Pre-Trained Transformer,其基本模型架构基于上述transformer模型
训练主要分为两个部分:1. 无监督的预训练; 2.有监督的tuning. 即先基于大语料训练出基础模型,再根据特定领域业务需求进行微调。
无监督的预训练目标函数:

有监督的微调阶段 目标函数

整体目标函数
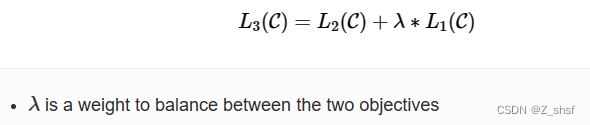
整体模型架构,以及依据不同task做微调时所需的输入转换如下图
 GPT" />
GPT" />
层数影响 和不同task下与LSTM性能对比
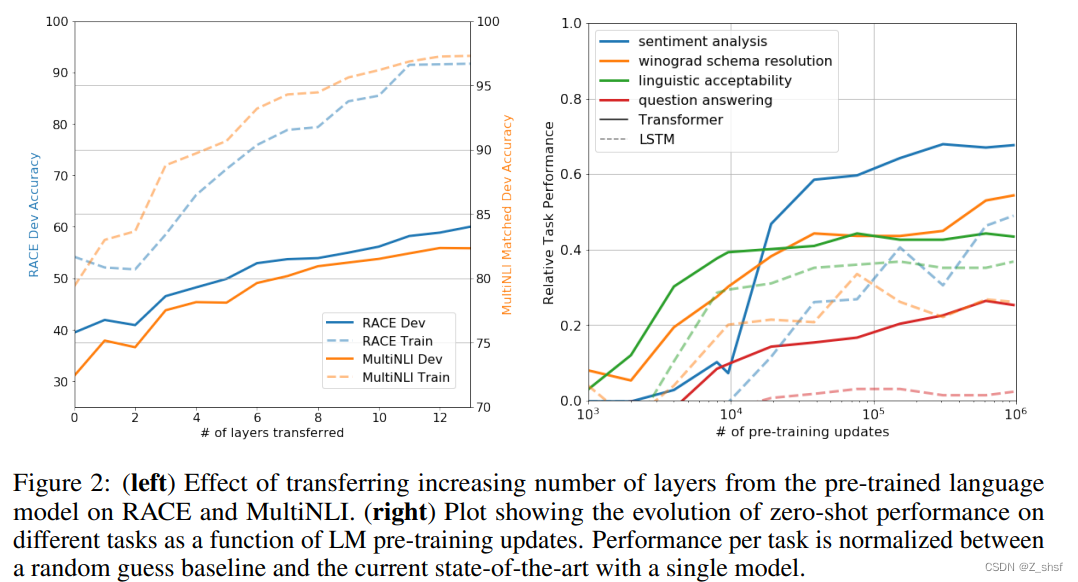
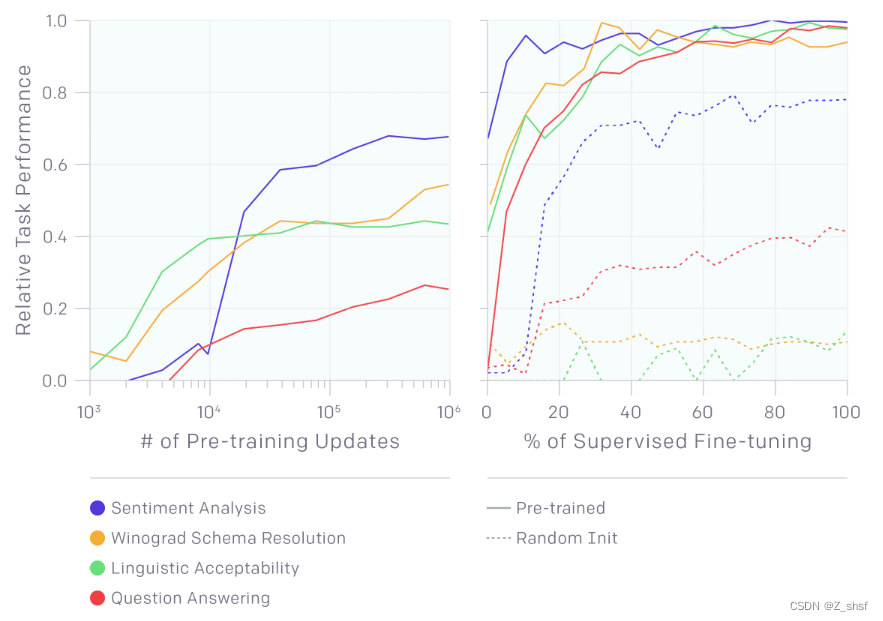
为什么需要第一步无监督预训练呢,下图给出了解释
Bert
Bert (Bidirectional Encoder Representations from Transformers)采用和 GPT 完全相同的两阶段模型,1.语言模型预训练;2.Fine-Tuning 模式解决下游任务。和 GPT 的最主要不同在于在预训练阶段采用了类似 ELMO 的双向语言模型。
Bert处理流程如图
 bert" />
bert" />
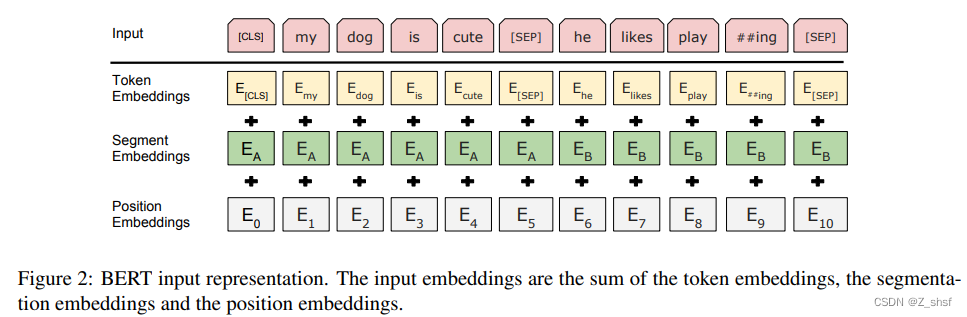
输入表示结构
性能表现
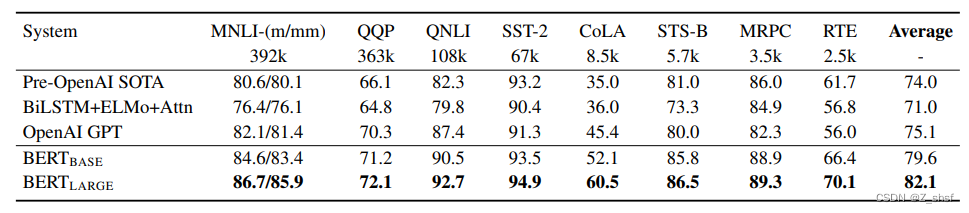
模型小结
Bert 和 ELMO 及 GPT 关系,若把 GPT 预训练阶段换成双向语言模型,即为 Bert;若ELMO 的特征抽取器换成 Transformer,也是Bert。因此Bert 最关键两点,1.特征抽取器采用 Transformer;2.预训练的时候采用双向语言模型。而特征抽取和预训练也是NLP一直以来发展最关键的两点。
References
[1] J. L. Ba, J. R. Kiros, and G. E. Hinton. Layer normalization. arXiv preprint arXiv:1607.06450, 2016. [3] Y. Bengio, P. Lamblin, D. Popovici, and H. Larochelle. Greedy layer-wise training of deep networks. In Advances in neural information processing systems, pages 153–160, 2007.
[2] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin.Attention is all you need. In Advances in Neural Information Processing Systems, pages 6000–6010, 2017.
[3] Radford, Alec and Karthik Narasimhan. “Improving Language Understanding by Generative Pre-Training.” (2018).
[4] Devlin, Jacob et al. “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding.” ArXiv abs/1810.04805 (2019): n. pag.
[5] Transformer’s Encoder-Decoder: Let’s Understand The Model Architecture - KiKaBeN
[6] 从BERT、XLNet到MPNet,细看NLP预训练模型发展变迁史 | 码农家园 (codenong.com)
[7] Transformer’s Encoder-Decoder: Let’s Understand The Model Architecture - KiKaBeN
[8] Improving language understanding with unsupervised learning (openai.com)
[9] 从Word Embedding到Bert模型——自然语言处理预训练技术发展史 | 机器之心 (jiqizhixin.com)