Abstract
研究如何在高密度人群场景中实现精准的实例定位,以及如何缓解传统模型由于目标遮挡、图像模糊等而降低特征提取能力的问题。为此,我们提出了一 Dilated Convolutional Swin Transformer(DCST)对于拥挤的人群场景
Specifically, a window-based vision transformer is introduced into the crowd localization task, which effectively improves the capacity of representation learning. 然后,将设计良好的扩张卷积模块插入transformer的不同阶段,以增强大范围上下文信息。
1 Introduction
2 Related Works
3 Approach

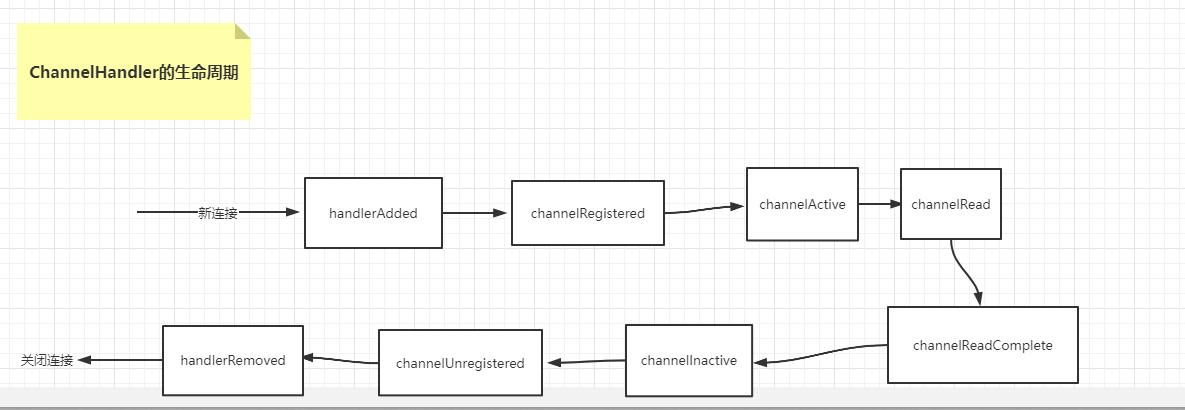
Dilated Convolutional Shift Window Vit (DCST)
A. Vision Transformer (ViT)
1) Patch embeddings:
Specifically, the operation of patch embeddings is formulated as follows:
z 0 = [ i c l a s s ; i p 1 E ; i p 2 E ; . . . ; i p N E ] + E p o s z_0 = [i_{class};i^1_p\textbf{E}; i^2_p\textbf{E};...;i^N_p\textbf{E}] + \textbf{E}_{pos} z0=[iclass;ip1E;ip2E;...;ipNE]+Epos
where i c l a s s i_{class} iclass is the embedded patches z 0 0 z^0_0 z00, and E \textbf{E} E denotes the process of the learnable embeddings ( E ∈ R ( P 2 × C ) × D , E ∈ R ( N + 1 ) × D \textbf{E}\in R^{(P^2\times C)\times D}, \textbf{E}\in R^{(N+1)\times D} E∈R(P2×C)×D,E∈R(N+1)×D).
2) Transformer Encoder:
Given a L L L layers of Transformer Encoder, MSA and MLP are formulated as:
z l ′ = M S A ( L N ( z l − 1 ) ) + z l − 1 , l = 1 , . . . , L , z'_l = MSA(LN(z_{l-1}))+z_{l-1}, l=1,...,L, zl′=MSA(LN(zl−1))+zl−1,l=1,...,L,
z l = M L P ( L N ( z l ′ ) ) + z l ′ , l = 1 , . . . , L , z_l = MLP(LN(z'_l))+z'_l, l=1,...,L, zl=MLP(LN(zl′))+zl′,l=1,...,L,
其中 L N LN LN表示层规范化
B. Swin Transformer
Swin Transformer在非重叠窗口中计算自注意力。为了编码上下文信息,连续层中的窗口分区是不同的。因此,大范围的信息在整个网络中通过局部自注意力模块进行转换。
与ViT中的MSA不同,Swin Transformer Blocks使用shifted-window MSA来计算局部self-attention。
C. Dilated Convolutional Swin Transformer
虽然Swin Transformer在分层结构中设计了顺序层的移位方案,但是大范围的空间上下文信息仍然编码不好。为了缓解这个问题,,我们提出了一种Dilated Convolutional Swin Transformer (DCST),用以放大空间图像的各个感受野。To be specific, the Dilated Convolutional Block is designed and inserted into betwwen different stages of Swin Transformer.
Dilated Convolution 增大感受野
Dilated Convolutional Block (DCB)
the number of H 4 × W 4 \frac H 4 \times \frac W 4 4H×4W C C C-dimension tokens is reshaped as a feature map with the size of H 4 × W 4 × C \frac H 4 \times \frac W 4 \times C 4H×4W×C. After this, two dilated convolutional with Batch Normalization and ReLU are applied to extract large-range spatial features.
D. Network Configurations
在此篇文章中,编码器使用提出的DCST,解码器基于FPN。
Encoder: DCST 在DCST, Swin Transformer 是 Swin-B,有4个stages,分别有2, 2, 18, 2个Swin Transformer Blocks。在Stage3和4之后添加有Dilated Convolutional Block(DCB)。DCB中两个扩张卷积的扩张率为2和3。
Decoder: FPN
针对DCST的四个极端,设计了四头的FPN。最后对获得的高质量输出,应用一个卷积层和两个反卷积层来产生和原始输入大小相同的1通道特征图。并采用sigmoid 激活来使结果规范化为 ( − 1 , 1 ) (-1,1) (−1,1)区间,并命名为score map。
E. Loss Function
采用标准均方误差损失函数来训练模型。
F. Implementation Details
略