Pipeline
pipeline() 的作用是使用预训练模型进行推断。
不同类型的任务所下载的默认预训练模型可以在 Transformers 库的源码
[transformers/__init__.py at main · huggingface/transformers · GitHub]中的 SUPPORTED_TASKS 定义。
参数Parameters
Batch size
推理时没必要。By default, pipelines will not batch inference for reasons explained in detail here. The reason is that batching is not necessarily faster, and can actually be quite slower in some cases.
[parameters]
pipline用法
使用本地模型进行推理
from transformers import AutoModelForSequenceClassification
from transformers import AutoTokenizer
from transformers import pipeline
model_path = r"../pretrained_model/IDEA-CCNL(Erlangshen-Roberta-110M-Sentiment)"
model = AutoModelForSequenceClassification.from_pretrained(model_path)
tokenizer = AutoTokenizer.from_pretrained(model_path)
classifier = pipeline("sentiment-analysis", model=model, tokenizer=tokenizer)
result = classifier("今天心情很好")
print(result)
# [{'label': 'Positive', 'score': 0.9374911785125732}][Pipelines for inference]
其它
[Using pipelines on a dataset]
使用 ONNX 和 Optimum 对 Transformers pipline 加速推理
Onnx:Fine tune your model for size, accuracy, resource utilization, and performance.[Learn more about ONNX]
HuggingFace Optimum是Transformers的扩展,它提供了性能优化工具的统一 API,以实现在加速硬件上训练和运行模型的最高效率,包括在Graphcore IPU和Habana Gaudi上优化性能的工具包。Optimum可通过其模块将模型从 PyTorch 或 TensorFlow 导出为序列化格式,例如 ONNX 和 TFLite exporters。Optimum还提供了一套性能优化工具,可以在目标硬件上以最高效率训练和运行模型,可用于加速训练、量化、图形优化,现在还可用于推理以及对Transformer pipeline的支持。Deploy your ONNX model using runtimes designed to accelerate inferencing. Optimum can be used for converting, quantization, graph optimization, accelerated training & inference with support for transformers pipelines.[Learn more about Optimum]
Note: ONNX 不是一个Runtime,ONNX 只是一种表示,可与 Runtimes如ONNX Runtime(ORT)等运行时一起使用。[受支持的加速器列表]
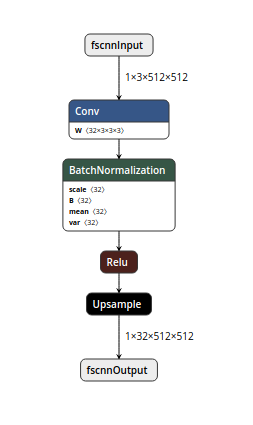
When a model is exported to the ONNX format, these operators are used to construct a computational graph (often called an intermediate representation) which represents the flow of data through the neural network.
pseudo ONNX graph, visualized with NETRON:
a typical developer journey of how you can leverage Optimum with ONNX:

安装依赖
$pip install optimum[onnxruntime]
下面将创建 3 个不同的模型。普通转换模型、优化模型和量化模型。
Transformer模型导出为普通onnx及推理
Exporting a Transformers model to ONNX with optimum.onnxruntime
from optimum.onnxruntime import ORTModelForSequenceClassification
from transformers import AutoTokenizer
model_checkpoint = "distilbert_base_uncased_squad"
save_directory = "onnx/"
# Load a model from transformers and export it to ONNX
ort_model = ORTModelForSequenceClassification.from_pretrained(model_checkpoint, export=True)
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)
# Save the onnx model and tokenizer
ort_model.save_pretrained(save_directory)
tokenizer.save_pretrained(save_directory)[Export to ONNX with-optimumonnxruntime]
其它导出方式参考
[Export to ONNX]
[Convert Transformers to ONNX with Hugging Face Optimum][Exportwith torch.onnx (low-level);Export with transformers.onnx (mid-level);Export with Optimum (high-level)]
ONNX模型推理inference
from transformers import AutoTokenizer
from optimum.onnxruntime import ORTModelForQuestionAnswering
tokenizer = AutoTokenizer.from_pretrained("distilbert_base_uncased_squad_onnx")
model = ORTModelForQuestionAnswering.from_pretrained("distilbert_base_uncased_squad_onnx")
inputs = tokenizer("What am I using?", "Using DistilBERT with ONNX Runtime!", return_tensors="pt")
outputs = model(**inputs)模型保存为ONNX并通过pipline推理
只需将AutoModelForXxx类替换为ORTModelForXxxOptimum 中相应的类即可
from pathlib import Path
from transformers import AutoTokenizer, pipeline
from optimum.onnxruntime import ORTModelForQuestionAnswering
model_id = "deepset/roberta-base-squad2"
onnx_path = Path("onnx")
task = "question-answering"
# load vanilla transformers and convert to onnx
model = ORTModelForQuestionAnswering.from_pretrained(model_id, from_transformers=True)
tokenizer = AutoTokenizer.from_pretrained(model_id)
# save onnx checkpoint and tokenizer
model.save_pretrained(onnx_path)
tokenizer.save_pretrained(onnx_path)
# test the model with using transformers pipeline, with handle_impossible_answer for squad_v2
optimum_qa = pipeline(task, model=model, tokenizer=tokenizer, handle_impossible_answer=True)
prediction = optimum_qa(question="What's my name?", context="My name is Philipp and I live in Nuremberg.")
print(prediction)
# {'score': 0.9041663408279419, 'start': 11, 'end': 18, 'answer': 'Philipp'}
使用ORTOptimizer优化模型
在我们保存 onnx 检查点后,我们现在可以使用ORTOptimizer应用图优化,例如算子融合operator fusion(算子融合是指将多个算子合并成一个更大的算子,以减少计算图中的算子节点数量和计算量。其中算子是指执行某种操作的函数,例如卷积、池化、激活函数等)、常量折叠constant folding(在模型优化过程中将常量值直接嵌入计算图中,以减少计算图中的常量节点数量和计算量monica),来减少计算图的复杂度、模型的内存占用和计算时间,从而提高模型的执行速度和效率,以加速延迟和推理。此外,它还可以自动识别和解决模型中的性能瓶颈,以进一步提高模型的性能。
from optimum.onnxruntime import ORTOptimizer
from optimum.onnxruntime.configuration import OptimizationConfig
# create ORTOptimizer and define optimization configuration
optimizer = ORTOptimizer.from_pretrained(model_id, feature=task)
optimization_config = OptimizationConfig(optimization_level=99) # enable all optimizations
# apply the optimization configuration to the model
optimizer.export(
onnx_model_path=onnx_path / "model.onnx",
onnx_optimized_model_output_path=onnx_path / "model-optimized.onnx",
optimization_config=optimization_config,
)
推理测试
from optimum.onnxruntime import ORTModelForQuestionAnswering
# load quantized model
opt_model = ORTModelForQuestionAnswering.from_pretrained(onnx_path, file_name="model-optimized.onnx")
# test the quantized model with using transformers pipeline
opt_optimum_qa = pipeline(task, model=opt_model, tokenizer=tokenizer, handle_impossible_answer=True)
prediction = opt_optimum_qa(question="What's my name?", context="My name is Philipp and I live in Nuremberg.")
print(prediction)
# {'score': 0.9041663408279419, 'start': 11, 'end': 18, 'answer': 'Philipp'}
使用ORTQuantizer来应用动态量化
优化模型后,我们可以通过使用ORTQuantizer量化模型并进一步加速。具体来说,它使用了多种量化技术,如动态量化、静态量化[Quantization]等,来将模型中的浮点数转换为整数或低精度浮点数,从而减小模型大小并加速延迟和推理。Quantization is a technique to reduce the computational and memory costs of running inference by representing the weights and activations with low-precision data types like 8-bit integer (int8) instead of the usual 32-bit floating point (float32). Reducing the number of bits means the resulting model requires less memory storage, consumes less energy (in theory), and operations like matrix multiplication can be performed much faster with integer arithmetic.
示例:这里使用avx512_vnni,因为由支持 avx512 的 intel Cascade-Lake CPU 提供支持。
from optimum.onnxruntime import ORTQuantizer
from optimum.onnxruntime.configuration import AutoQuantizationConfig
# create ORTQuantizer and define quantization configuration
quantizer = ORTQuantizer.from_pretrained(model_id, feature=task)
qconfig = AutoQuantizationConfig.avx512_vnni(is_static=False, per_channel=True)
# 或者类似qconfig = AutoQuantizationConfig.arm64(is_static=False, per_channel=False)
# apply the quantization configuration to the model
quantizer.export(
onnx_model_path=onnx_path / "model-optimized.onnx",
onnx_quantized_model_output_path=onnx_path / "model-quantized.onnx",
quantization_config=qconfig,
)
# 或者类似quantizer.quantize(save_dir=save_directory, quantization_config=qconfig)
模型大小变化:
# Vanilla Onnx Model file size: 473.31 MB
# Quantized Onnx Model file size: 291.77 MB
加载量化模型并使用pipline进行推理
# load quantized model
quantized_model = ORTModelForQuestionAnswering.from_pretrained(onnx_path, file_name="model-quantized.onnx")
# test the quantized model with using transformers pipeline
quantized_optimum_qa = pipeline(task, model=quantized_model, tokenizer=tokenizer, handle_impossible_answer=True)
prediction = quantized_optimum_qa(question="What's my name?", context="My name is Philipp and I live in Nuremberg.")
print(prediction)
# {'score': 0.9246969819068909, 'start': 11, 'end': 18, 'answer': 'Philipp'}
性能测试
优化&量化后的模型从延迟117.61ms加速至64.94ms大约2 倍,同时f1值能保持原始模型的99.61%。
from:LLM:Transformers模型推理和加速_-柚子皮-的博客-CSDN博客
ref:[Pipeline 使用]
[Accelerated Inference with Optimum and Transformers Pipelines]
[optimum官方文档🤗 Optimum]

