目录
- 简介
- 模型
- Vanilla Transformer
- recurrence mechanism
- 相对位置编码
- pytorch实现——batch_size为第一维度
- 参考资料
简介
RNN及其变体是训练语言模型(Language Modeling)的经典结构,其优点就是能够学习到序列之间的依赖关系,缺点:1)随着序列长度的增加,序列之间的依赖关系信息会逐渐丢失;2)单向;3)计算速度慢,只能step by step。截止到Transformer-XL,单向学习似乎是LM任务绕不过去的坎,XLNet以PLM任务为目标,才比较隐蔽的解决单向学习语言模型的问题。
为了解决RNN存在的问题,Transformer-XL(XL表示extra long)沿用Transformer 中Decoder的结构,以及采用“相对位置编码+多头注意力机制”, 实现“捕获长距离依赖关系的目标”。
模型
Vanilla Transformer
Transformer-XL引入的循环机制,参考了Vanilla Transformer的思想,因此先介绍下Vanilla Transformer模型。Vanilla对于长输入,在训练阶段,会将输入割裂成独立的几个部分(segment),然后分别处理。在推断阶段,每次取segment长度的输入进行处理,输出一个预测词,然后向右移动一个位置。如下图所示:

这样做有明显的缺点:1)编码或者推断过程,最多只能看到segment length的信息,当原始输入中存在长距离依赖关系时,会学习不足;2)割裂处理每一部分,产生了碎片化问题;3)在推断阶段,每次都从头计算,计算效率非常低。
recurrence mechanism
Transformer-XL继续沿用“attention”机制的优势, 并且为了捕获长距离依赖,同时引入RNN中的“循环机制”, 但是与RNN有所不同,Transformer-XL的循环机制的粒度是“segment”(后面称为切片),而RNN中以字为粒度的。另外一个显著不同点是,计算第
i
+
1
i+1
i+1切片的第
N
N
N层隐向量时,需要用到第
i
i
i 个切片的第
N
−
1
N-1
N−1层隐向量信息、以及第
i
+
1
i+1
i+1切片的第
N
−
1
N-1
N−1层隐向量。注意是“前一个切片的下一层的隐向量”,如下所示:
 transformer-XL" />
transformer-XL" />
即对于第
i
+
1
i+1
i+1切片的最后一层隐向量的最后一个位置,可以看到
N
∗
L
N* L
N∗L范围的信息,
L
L
L表示切片长度。 引入循环机制,使得信息可以在不同的segment之间流动,避免了碎片化。
相对位置编码
标准Transformer采用的是sin-cos绝对位置编码(多头注意力机制是没有考虑输入序列的位置信息的,因此必须额外的引入位置信息,否则就类似词袋模型了),但由于没有引用“循环机制”,因此可以不采用相对位置的编码方式。而Transformer-XL由于引入了循环机制,因此必须考虑切片之间的相对位置信息,否则每一切片的同一位置信息是一致的,这显然不合理。假设某一切片内存在
i
,
j
i, j
i,j两个位置,则这两个位置的:
a
i
,
j
a
b
s
=
q
i
T
∗
k
j
=
(
W
q
∗
(
E
(
x
i
)
+
U
i
)
)
T
∗
(
W
k
∗
(
E
(
x
j
)
+
U
j
)
)
=
E
x
i
T
∗
W
q
T
∗
W
k
∗
E
x
j
+
E
x
i
T
∗
W
q
T
∗
W
k
∗
U
j
+
U
i
T
∗
W
q
T
∗
W
k
∗
E
x
j
+
U
i
T
∗
W
q
T
∗
W
k
∗
U
j
a_{i,j}^{abs} = q_i^T * k_j = (W_q * (E(x_i) + U_i))^T * (W_k * (E(x_j) + U_j)) \newline = E_{x_i}^T * W_q^T * W_k * E_{x_j} \newline + E_{x_i}^T * W_q^T * W_k * U_j \newline + U_i^T * W_q^T * W_k * E_{x_j} \newline + U_i^T * W_q^T * W_k * U_j
ai,jabs=qiT∗kj=(Wq∗(E(xi)+Ui))T∗(Wk∗(E(xj)+Uj))=ExiT∗WqT∗Wk∗Exj+ExiT∗WqT∗Wk∗Uj+UiT∗WqT∗Wk∗Exj+UiT∗WqT∗Wk∗Uj
其中
U
U
U表示PositionalEmbedding矩阵,该矩阵就是Transformer中使用的PE,是不需要学习的。论文对上面的四个子项进行优化,优化后如下
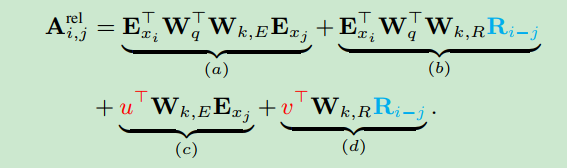
其中
u
T
u^T
uT、
v
T
v^T
vT、
W
k
,
R
W_{k, R}
Wk,R、
W
k
,
E
W_{k, E}
Wk,E、
W
q
T
W_q^T
WqT是学习参数,
R
R
R矩阵是PE矩阵,不需要学习。将(a)、(c)项合并, (b)、(d)项合并,如下:
A
i
,
j
r
e
l
=
(
E
x
i
T
∗
W
q
T
+
u
T
)
∗
W
k
,
E
E
x
j
+
(
E
x
i
T
∗
W
q
T
+
v
T
)
W
k
,
R
R
i
−
j
A_{i,j}^{rel} = (E_{x_i}^T * W_q^T + u^T) * W_{k, E} E_{x_j} + (E_{x_i}^T * W_q^T + v^T)W_{k,R}R_{i-j}
Ai,jrel=(ExiT∗WqT+uT)∗Wk,EExj+(ExiT∗WqT+vT)Wk,RRi−j
第一项中不涉及相对位置信息,直接进行矩阵计算就可以,第二项中由于包含 R i − j R_{i-j} Ri−j,因此需要进行相对位置转换。
对于
E
x
i
T
∗
W
q
T
∗
W
k
,
R
∗
R
i
−
j
E_{x_i}^T * W_q^T * W_{k,R} *R_{i-j}
ExiT∗WqT∗Wk,R∗Ri−j项,
R
i
−
j
R_{i-j}
Ri−j是位置矩阵中某一位置的值,
E
x
i
T
E_{x_i}^T
ExiT是某一位置的词嵌入向量或者隐向量, $W_q^T $会对值进行映射,
W
k
,
R
W_{k,R}
Wk,R 对位置信息进行映射,因此该项的值关键是要确定查询向量q与键向量k的相对位置关系。
假设当前输入段的长度为 L L L,缓存的Memory长度为 M M M,则该项的shape为 L ∗ ( M + L ) L * (M+L) L∗(M+L), R i − j R_{i-j} Ri−j取值范围为 [ 0 , L + M − 1 ] [0, L+M-1] [0,L+M−1], 则: B L , L + M s h i f t = [ E x 0 T ∗ W q T ∗ W k , R ∗ R M ⋯ E x 0 T ∗ W q T ∗ W k , R ∗ R 1 E x 0 T ∗ W q T ∗ W k , R ∗ R 0 ⋯ E x 0 T ∗ W q T ∗ W k , R ∗ R L − 1 E x 1 T ∗ W q T ∗ W k , R ∗ R M + 1 ⋯ E x 1 T ∗ W q T ∗ W k , R ∗ R 2 E x 1 T ∗ W q T ∗ W k , R ∗ R 1 ⋯ E x 1 T ∗ W q T ∗ W k , R ∗ R L − 2 ⋮ ⋱ ⋮ ⋮ ⋱ ⋮ E x L − 1 T ∗ W q T ∗ W k , R ∗ R L + M − 1 ⋯ E x L − 1 T ∗ W q T ∗ W k , R ∗ R L − 1 E x L − 1 T ∗ W q T ∗ W k , R ∗ R L − 2 ⋯ E x L − 1 T ∗ W q T ∗ W k , R ∗ R 0 ] B_{L, L+M}^{shift}=\begin{bmatrix} E_{x_0}^T * W_q^T * W_{k, R} * R_M & \cdots & E_{x_0}^T * W_q^T * W_{k, R} * R_1 & E_{x_0}^T * W_q^T * W_{k, R} * R_0 &\cdots & E_{x_0}^T * W_q^T * W_{k, R} * R_{L-1} \\ E_{x_1}^T * W_q^T * W_{k, R} * R_{M+1}& \cdots & E_{x_1}^T * W_q^T * W_{k, R} * R_{2} & E_{x_1}^T * W_q^T * W_{k, R} * R_1 & \cdots & E_{x_1}^T * W_q^T * W_{k, R} * R_{L-2}\\ \vdots&\ddots&\vdots &\vdots &\ddots &\vdots\\ E_{x_{L-1}}^T * W_q^T * W_{k, R} * R_{L+M-1} & \cdots & E_{x_{L-1}}^T * W_q^T * W_{k, R} * R_{L-1} & E_{x_{L-1}}^T * W_q^T * W_{k, R} * R_{L - 2} & \cdots & E_{x_{L-1}}^T * W_q^T * W_{k, R} * R_0 \end{bmatrix} BL,L+Mshift=⎣⎢⎢⎢⎡Ex0T∗WqT∗Wk,R∗RMEx1T∗WqT∗Wk,R∗RM+1⋮ExL−1T∗WqT∗Wk,R∗RL+M−1⋯⋯⋱⋯Ex0T∗WqT∗Wk,R∗R1Ex1T∗WqT∗Wk,R∗R2⋮ExL−1T∗WqT∗Wk,R∗RL−1Ex0T∗WqT∗Wk,R∗R0Ex1T∗WqT∗Wk,R∗R1⋮ExL−1T∗WqT∗Wk,R∗RL−2⋯⋯⋱⋯Ex0T∗WqT∗Wk,R∗RL−1Ex1T∗WqT∗Wk,R∗RL−2⋮ExL−1T∗WqT∗Wk,R∗R0⎦⎥⎥⎥⎤
对于第一行 q 0 q_0 q0,即 L L L段的第一个元素,它与 L + M L+M L+M中所有元素的相对位置关系为:“ M M M、…、 1 1 1、 0 0 0… L − 1 L-1 L−1”。 同理第二行的相对位置关系为“ M + 1 M+1 M+1、…、 2 2 2、 1 1 1… L − 2 L-2 L−2”, 最后一个元素 q L − 1 q_{L-1} qL−1的相对位置关系为“ M + L − 1 M+L-1 M+L−1、…、 L L L、 L − 1 L-1 L−1… 0 0 0”。
上面的
B
s
h
i
f
t
B^{shift}
Bshift是最终需要的,但直接使用torch.matmul(w_head_q, r_head_k)得到的是如下的绝对位置
B
a
b
s
B^{abs}
Babs:

将绝对位置转换成相对位置的核心实现如下, 可阅读参考资料三帮助理解(个人没有理解这种转换的数学原理,有理解的大神请留言):
def _rel_shift(self, x, zero_triu=False):
"""参数x是BD项的注意力得分, 参数zero_triu用于控制subsequence mask,即当前单词只能看到之前出现的信息,不能看到之后的单词"""
zero_pad = torch.zeros((x.size(0), 1, *x.size()[2:]),
device=x.device, dtype=x.dtype)
x_padded = torch.cat([zero_pad, x], dim=1)
x_padded = x_padded.view(x.size(1) + 1, x.size(0), *x.size()[2:])
x = x_padded[1:].view_as(x)
if zero_triu:
ones = torch.ones((x.size(0), x.size(1)))
x = x * torch.tril(ones, x.size(1) - x.size(0))[:,:,None,None]
return x
下面对源码中的相对位置多头注意力进行加标注,帮助理解:
class RelPartialLearnableMultiHeadAttn(RelMultiHeadAttn):
def __init__(self, *args, **kwargs):
super(RelPartialLearnableMultiHeadAttn, self).__init__(*args, **kwargs)
# 相当于W_{k, R}, 用于对PE中的位置信息进行映射
self.r_net = nn.Linear(self.d_model, self.n_head * self.d_head, bias=False)
def forward(self, w, r, r_w_bias, r_r_bias, attn_mask=None, mems=None):
"""
w: 嵌入向量或者隐向量
r:**反向的绝对位置嵌入向量**, 可参考MemTransformerLM中_forward方法中:pos_seq = torch.arange(klen-1, -1, -1.0, device=word_emb.device, dtype=word_emb.dtype), 并且说明位置向量的长度与klen相等
r_w_bias: 可学习参数u
r_r_bias: 科学系参数v
attn_mask: 注意力遮掩矩阵
mems: 之前段的缓存信息
"""
qlen, rlen, bsz = w.size(0), r.size(0), w.size(1)
if mems is not None:
cat = torch.cat([mems, w], 0)
if self.pre_lnorm:
w_heads = self.qkv_net(self.layer_norm(cat))
else:
w_heads = self.qkv_net(cat) # 计算q, k, v
r_head_k = self.r_net(r) # 计算 W_{k, R} * R_{i, j}
w_head_q, w_head_k, w_head_v = torch.chunk(w_heads, 3, dim=-1)
w_head_q = w_head_q[-qlen:] # 需要切片, 因为查询段的长度此时为 : (内存段长度 + 查询段长度)
else:
if self.pre_lnorm:
w_heads = self.qkv_net(self.layer_norm(w))
else:
w_heads = self.qkv_net(w)
r_head_k = self.r_net(r)
w_head_q, w_head_k, w_head_v = torch.chunk(w_heads, 3, dim=-1)
klen = w_head_k.size(0) # klen = qlen + mems.size(0) if mems is not None else qlen
w_head_q = w_head_q.view(qlen, bsz, self.n_head, self.d_head) # qlen x bsz x n_head x d_head
w_head_k = w_head_k.view(klen, bsz, self.n_head, self.d_head) # klen x bsz x n_head x d_head
w_head_v = w_head_v.view(klen, bsz, self.n_head, self.d_head) # klen x bsz x n_head x d_head
r_head_k = r_head_k.view(rlen, self.n_head, self.d_head) # rlen x n_head x d_head
#### compute attention score
# w_head_q 相当于 E_{x_i}^T * W_q^T, w_head_k 相当于 E_{k, E} * E_{x_j}
rw_head_q = w_head_q + r_w_bias # qlen x bsz x n_head x d_head
AC = torch.einsum('ibnd,jbnd->ijbn', (rw_head_q, w_head_k)) # qlen x klen x bsz x n_head
rr_head_q = w_head_q + r_r_bias
# BD矩阵乘机在这里是**绝对位置**, 需要转换成相对位置
BD = torch.einsum('ibnd,jnd->ijbn', (rr_head_q, r_head_k)) # qlen x klen x bsz x n_head
# 转换成相对位置
BD = self._rel_shift(BD)
# [qlen x klen x bsz x n_head]
attn_score = AC + BD
attn_score.mul_(self.scale) # 缩放
#### compute attention probability
# 注意力遮掩, 后面就是标准的多头注意力计算流程
if attn_mask is not None and attn_mask.any().item():
if attn_mask.dim() == 2:
attn_score = attn_score.float().masked_fill(
attn_mask[None,:,:,None], -float('inf')).type_as(attn_score)
elif attn_mask.dim() == 3:
attn_score = attn_score.float().masked_fill(
attn_mask[:,:,:,None], -float('inf')).type_as(attn_score)
# [qlen x klen x bsz x n_head]
attn_prob = F.softmax(attn_score, dim=1)
attn_prob = self.dropatt(attn_prob)
#### compute attention vector
attn_vec = torch.einsum('ijbn,jbnd->ibnd', (attn_prob, w_head_v))
# [qlen x bsz x n_head x d_head]
attn_vec = attn_vec.contiguous().view(
attn_vec.size(0), attn_vec.size(1), self.n_head * self.d_head)
##### linear projection
attn_out = self.o_net(attn_vec)
attn_out = self.drop(attn_out)
if self.pre_lnorm:
##### residual connection
output = w + attn_out
else:
##### residual connection + layer normalization
output = self.layer_norm(w + attn_out)
return output
pytorch实现——batch_size为第一维度
import torch
import torch.nn as nn
import torch.nn.functional as F
class PositionalEmbedding(nn.Module):
""" absolute sinusoidal position embedding. """
def __init__(self, d_emb):
""" d_emb denotes the dim of position embedding. """
super(PositionalEmbedding, self).__init__()
self.inv_freq = 1 / 10000 ** (torch.arange(0.0, d_emb, 2) / d_emb)
self.register_buffer('inv_frep', self.inv_freq)
def forward(self, pos_seq, batch_size=None):
angles = torch.outer(pos_seq, self.inv_freq)
pe = torch.cat([angles.sin(), angles.cos()], dim=1)
if batch_size is None:
return pe.unsqueeze(0)
else:
return pe.unsqueeze(0).expand(batch_size, -1, -1)
class PosWiseFeedForward(nn.Module):
""" Position-wise Feed Forward network. """
def __init__(self, d_model, dff):
super(PosWiseFeedForward, self).__init__()
self.layers = nn.Sequential(
nn.Linear(d_model, dff, bias=False),
nn.ReLU(),
nn.Linear(dff, d_model, bias=False),
)
self.layer_norm = nn.LayerNorm(d_model)
def forward(self, x):
output = self.layer_norm(x + self.layers(x))
return output
class MultiHeadAttention(nn.Module):
""" standard multi-head attention in transformer. """
def __init__(self, d_model, num_heads, d_head):
super(MultiHeadAttention, self).__init__()
self.d_model = d_model
self.num_heads = num_heads
self.d_head = d_head
self.WQ = nn.Linear(d_model, num_heads * d_head, bias=False)
self.WKV = nn.Linear(d_model, 2 * num_heads * d_head, bias=False)
self.fc = nn.Linear(num_heads * d_head, d_model, bias=False)
self.layer_norm = nn.LayerNorm(d_model)
self.scale_factor = 1 / d_head ** 0.5
def forward(self, hidden_states, memory=None, attention_mask=None):
# hidden_states.shape: (batch_size, seq_len, d_model)
if memory is not None:
concat_hidden_states = torch.cat([memory, hidden_states], dim=1)
else:
concat_hidden_states = hidden_states
batch_size, q_len = hidden_states.size(0), hidden_states.size(1)
q = self.WQ(hidden_states)
k, v = torch.chunk(self.WKV(concat_hidden_states), chunks=2, dim=-1)
q = q.view(batch_size, q_len, self.num_heads, self.d_head)
k = k.view(batch_size, -1, self.num_heads, self.d_head)
v = v.view(batch_size, -1, self.num_heads, self.d_head)
# attention_scores.shape: (batch_size, num_heads, q_len, k_len)
attention_scores = torch.einsum('bqnd, bknd -> bnqk', q, k)
attention_scores.mul_(self.scale_factor)
if attention_mask is not None and attention_mask.any().item():
if attention_mask.dim() == 2:
attention_scores.masked_fill_(attention_mask[None, None, :, :], float("-inf"))
elif attention_mask.dim() == 3:
attention_scores.masked_fill_(attention_mask[:, None, :, :], float("-inf"))
# attention_weights.shape: (batch_size, num_head, q_len, k_len)
attention_weights = F.softmax(attention_scores, dim=-1)
# k.shape: (batch_size, k_len, num_heads, d_head)
# context_vectors.shape: (batch_size, q_len, num_head, d_head)
context_vectors = torch.einsum('bnqk, bknd -> bqnd', attention_weights, v)
context_vectors = context_vectors.contiguous().view(batch_size, -1, self.num_heads * self.d_model)
# context_vectors.shape: (batch_size, q_len, d_model)
context_vectors = self.fc(context_vectors)
outputs = self.layer_norm(hidden_states + context_vectors)
return outputs
class RelMultiHeadAttention(nn.Module):
def __init__(self, d_model, num_heads, d_head):
super(RelMultiHeadAttention, self).__init__()
self.d_model = d_model
self.num_heads = num_heads
self.d_head = d_head
self.WQKV = nn.Linear(d_model, 3 * num_heads * d_head, bias=False)
self.fc = nn.Linear(num_heads * d_head, d_model)
self.layer_norm = nn.LayerNorm(d_model)
self.scale_factor = 1 / d_head ** 0.5
def _rel_shift(self, x, zero_triu=False):
"""
convert absolute into relative position
:param x: attention score
:param zero_triu: whether or not mask upper triangular matrix, equal to subsequence mask
"""
# zero_pad.shape: (batch_size, num_heads, q_len, 1)
zero_pad = torch.zeros(x.size(0), x.size(1), x.size(2), 1, device=x.device, dtype=x.dtype)
# x_padded.shape: (batch_size, num_heads, q_len, k_len + 1)
x_padded = torch.cat([zero_pad, x], dim=-1)
# x_padded.shape: (batch_size, num_heads, k_len + 1, q_len)
x_padded = x_padded.view(x.size(0), x.size(1), x.size(3) + 1, x.size(2))
# x.shape: (batch_size, num_heads, q_len, k_len)
x = x_padded[:, :, 1:, :].view_as(x)
if zero_triu:
ones = torch.ones(x.size(2), x.size(3))
x *= torch.tril(ones, x.size(3) - x.size(2))[None, None, :, :]
return x
def forward(self, w, r, memory, attention_mask):
""" w denotes previous hidden states, r denotes relative position embedding ."""
raise NotImplementedError
class RelPartialLearnableMultiHeadAttention(RelMultiHeadAttention):
def __init__(self, *args, **kwargs):
super(RelPartialLearnableMultiHeadAttention, self).__init__(*args, **kwargs)
# project absolute position embedding
self.Wkr = nn.Linear(self.d_model, self.num_heads * self.d_head, bias=False)
def forward(self, w, r, r_w_bias, r_r_bias, memory=None, attention_mask=None):
"""
Args:
w (batch_size, q_len, d_model): denotes word embedding or hidden states
r (pos_seq_len, d_model): ** denotes reverse absolute position embedding **
r_w_bias (num_heads, d_head): denotes learnable parameter u in paper, for i in [0, q_len-1], r_w_bias tie weights
r_r_bias (num_heads, d_head): denotes learnable parameter v in paper, for i in [0, q_len-1], r_r_bias tie weights
memory: previous segment's hidden states
attention_mask : mask attentions
Returns:
hidden states(batch_size, q_len, d_model)
"""
batch_size = w.size(0)
q_len = w.size(1)
r_len = r.size(1)
if memory is not None:
# concat.shape: (batch_size, q_len + len(memory), d_model)
concat = torch.cat([memory, w], dim=1)
# w_heads_qkv.shape: (batch_size, q_len + len(memory), 3 * num_heads * d_head)
w_heads_qkv = self.WQKV(concat)
# r_head_k.shape: (r_len, num_heads * d_head)
r_head_k = self.Wkr(r) # calculate W_{k, R} * R
# (batch_size, q_len + len(memory), num_heads * d_head)
w_head_q, w_head_k, w_head_v = torch.chunk(w_heads_qkv, chunks=3, dim=-1)
# w_head_q.shape: (batch_size, q_len, num_heads * d_head)
w_head_q = w_head_q[:, -q_len:, :]
else:
# qkv_heads.shape: (batch_size, q_len, 3 * num_heads * d_head)
w_heads_qkv = self.WQKV(w)
# r_head_k.shape: (r_len, num_heads * d_head)
r_head_k = self.Wkr(r)
w_head_q, w_head_k, w_head_v = torch.chunk(w_heads_qkv, 3, dim=-1)
k_len = w_head_k.size(1)
w_head_q = w_head_q.reshape((batch_size, self.num_heads, q_len, self.d_head))
w_head_k = w_head_k.reshape((batch_size, self.num_heads, k_len, self.d_head))
w_head_v = w_head_v.reshape((batch_size, self.num_heads, k_len, self.d_head))
r_head_k = r_head_k.view(self.num_heads, r_len, self.d_head)
# compute attention score
# rw_head_q.shape: (batch_size, num_heads, q_len, d_head)
# w_head_q 相当于 E_{x_i}^T * W_q^T
rw_head_q = w_head_q + r_w_bias[None, :, None, :].expand(batch_size, -1, q_len, -1)
# w_head_k 相当于 E_{k, E} * E_{x_j}
# AC.shape: (batch_size, num_heads, q_len, k_len)
AC = torch.einsum('bnqd, bnkd -> bnqk', rw_head_q, w_head_k)
# now BD that is created by torch.matmul(rr_head_q, w_head_k) is based on absolute position, should be
# converted into basing on relative position
rr_head_q = w_head_q + r_r_bias[None, :, None, :].expand(batch_size, -1, q_len, -1)
# BD.shape: (batch_size, num_heads, q_len, k_len)
BD = torch.einsum('bnqd, nkd -> bnqk', rr_head_q, r_head_k)
# convert absolute position into relative position
BD = self._rel_shift(BD)
# attention_score.shape: (batch_size, num_heads, q_len, k_len)
attention_score = AC + BD
attention_score.mul_(self.scale_factor)
if attention_mask is not None and attention_mask.any().item():
if attention_mask.dim() == 2:
attention_score = attention_score.float().\
masked_fill(attention_mask[None, None, :, :], -float('inf')).type_as(attention_score)
elif attention_mask.dim() == 3:
attention_score = attention_score.float().masked_fill(
attention_mask[:, None, :, :], -float('inf')).type_as(attention_score)
# attention_weights.shape: (batch_size, num_heads, q_len, k_len)
attention_weights = F.softmax(attention_score, dim=-1)
attention_vectors = torch.einsum('bnqk, bnkd -> bqnd', attention_weights, w_head_v)
attention_vectors = attention_vectors.contiguous().view(batch_size, -1, self.num_heads * self.d_head)
# outputs.shape: (batch_size, q_len, d_model)
outputs = self.fc(attention_vectors)
return self.layer_norm(w + outputs)
class RelPartialLearnableDecoderLayer(nn.Module):
def __init__(self, d_model, num_heads, d_head, dff):
super(RelPartialLearnableDecoderLayer, self).__init__()
self.attn_layer = RelPartialLearnableMultiHeadAttention(d_model, num_heads, d_head)
self.ff_layer = PosWiseFeedForward(d_model, dff)
def forward(self, x, r, r_w_bias, r_r_bias, memory=None, attention_mask=None):
outputs = self.attn_layer(x, r, r_w_bias, r_r_bias, memory, attention_mask)
outputs = self.ff_layer(outputs)
return outputs
class MemTransformerLM(nn.Module):
def __init__(self, vocab_size, num_layers, d_model, num_heads, d_head, dff, same_length=False):
"""
same_length denotes whether each token use same length memory or not.
"""
super(MemTransformerLM, self).__init__()
self.num_layers = num_layers
self.d_model = d_model
self.num_heads = num_heads
self.d_head = d_head
self.same_length = same_length
self.embedding = nn.Embedding(vocab_size, d_model) # assume d_emb = d_model
self.layers = nn.ModuleList([RelPartialLearnableDecoderLayer(d_model, num_heads, d_head, dff)
for _ in range(num_layers)])
self.fc = nn.Linear(d_model, vocab_size, bias=False)
self._create_params()
def _create_params(self):
self.pe = PositionalEmbedding(self.d_model)
self.r_w_bias = nn.Parameter(torch.zeros(self.num_heads, self.d_head))
self.r_r_bias = nn.Parameter(torch.zeros(self.num_heads, self.d_head))
return
def init_memory(self):
""" initialize memory """
mems = list()
params = next(self.parameters())
for _ in range(self.num_layers + 1):
mems.append(torch.empty(0, dtype=params.dtype, device=params.device))
return mems
def _update_memory(self, hidden_states, memories, q_len):
"""
hidden_states.shape: (num_layers + 1, batch_size, q_len, d_model)
memory.shape: (num_layers + 1, batch_size, q_len, d_model)
"""
if memories is None:
return
assert len(hidden_states) == len(memories), 'len(hidden_state) != len(memory)'
# should stop calculating memory's gradients.
with torch.no_grad():
new_mems = []
for idx in range(len(hidden_states)):
concat = torch.cat([memories[idx], hidden_states[idx]], dim=1)
new_mems.append(concat[:, -q_len:, :].detach())
return new_mems
def _forward(self, decoder_input, memories=None):
batch_size, q_len = decoder_input.size(0), decoder_input.size(1)
# word_embedding.shape: (batch_size, q_len, d_model)
word_embedding = self.embedding(decoder_input)
m_len = memories[0].size(1) if memories is not None and memories[0].numel() > 0 else 0
k_len = m_len + q_len
if self.same_length:
ones = torch.ones(q_len, k_len, dtype=word_embedding.dtype, device=word_embedding.device)
mask_shift_len = q_len
attention_mask = (torch.triu(ones, 1 + m_len) + torch.tril(ones, -mask_shift_len)).byte()[None, :, :]
else:
attention_mask = torch.triu(
word_embedding.new_ones(q_len, k_len), diagonal=m_len + 1).to(torch.int8)[None, :, :]
hidden_states = list()
# **** note: the input's absolute positions should reversed. ****
pos_seq = torch.arange(k_len-1, -1.0, -1.0, dtype=word_embedding.dtype, device=word_embedding.device)
# pe.shape: (batch_size, k_len, d_model)
pe = self.pe(pos_seq)
# hidden states includes word embedding
hidden_states.append(word_embedding)
outputs = word_embedding
for layer_idx, layer in enumerate(self.layers):
mem_i = None if memories is None else memories[layer_idx]
outputs = layer(outputs, pe, self.r_w_bias, self.r_r_bias, memory=mem_i, attention_mask=attention_mask)
hidden_states.append(outputs)
new_memories = self._update_memory(hidden_states, memories, q_len)
return outputs, new_memories
def forward(self, decoder_input, target, memories):
if not memories:
memories = self.init_memory()
# outputs.shape: (batch_size, q_len, d_model)
outputs, new_memories = self._forward(decoder_input, memories)
# outputs.shape: (batch_size, q_len, vocab_size)
outputs = self.fc(outputs)
loss_ = F.cross_entropy(outputs.view(-1, outputs.size(-1)), target.view(-1), reduction='mean')
if new_memories is None:
return [loss_]
else:
return [loss_] + new_memories
if __name__ == '__main__':
num_layers = 2
vocab_size = 1000
d_model = 512
nums_head = 8
d_head = 64
dff = 1024
model = MemTransformerLM(vocab_size, num_layers, d_model, nums_head, d_head, dff)
batch_size = 1
segment_len = 4
segment = 10
x = torch.randint(0, vocab_size, (1, segment_len * segment))
y = torch.cat([x, torch.zeros(1, 1)], dim=1)[:, 1:].to(torch.long)
mems = None
for idx in range(segment):
inp = x[:, idx * segment_len: (idx + 1) * segment_len]
tgt = y[:, idx * segment_len: (idx + 1) * segment_len]
outputs = model(inp, tgt, mems)
mems = outputs[1:]
参考资料
- 论文 《Transformer-XL: Attentive Language ModelsBeyond a Fixed-Length Context》
- https://blog.csdn.net/Magical_Bubble/article/details/89060213
- https://zhuanlan.zhihu.com/p/74485142




