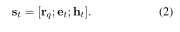- 文献题目:VideoBERT: A Joint Model for Video and Language Representation Learning
- 代码:https://github.com/ammesatyajit/VideoBERT
摘要
- 自我监督学习对于利用 YouTube 等平台上可用的大量未标记数据变得越来越重要。尽管大多数现有方法都学习低级表示,但我们提出了一种联合视觉语言模型来学习高级特征而无需任何明确的监督。特别是,受其最近在语言建模方面的成功启发,我们基于 BERT 模型来学习视觉和语言标记序列上的双向联合分布,这些标记分别来自视频数据的矢量量化和现成的语音识别输出。我们在许多任务中使用 VideoBERT,包括动作分类和视频字幕。我们表明它可以直接应用于开放词汇分类,并确认大量的训练数据和跨模态信息对性能至关重要。此外,我们在视频字幕方面的表现优于最新状态,定量结果验证了该模型学习了高级语义特征。
引言
- 深度学习可以从标记数据中受益很多 [24],但这很难大规模获取。 因此,最近人们对“自我监督学习”产生了很多兴趣,我们在各种“代理任务”上训练模型,我们希望这将导致发现可用于下游任务的特征或表示。 在图像和视频领域已经提出了各种各样的此类代理任务。 然而,这些方法中的大多数都关注低级特征(例如纹理)和短时间尺度(例如持续一秒或更短的运动模式)。 我们有兴趣发现与在较长时间尺度(例如分钟)上展开的动作和事件相对应的高级语义特征,因为这样的表示对于各种视频理解任务很有用。
- 在本文中,我们利用人类语言已经进化出描述高级对象和事件的词语这一关键见解,从而提供了“自我”监督的自然来源。 特别是,我们提出了一种简单的方法,通过结合三种现成的方法来模拟视觉域和语言域之间的关系:将语音转换为文本的自动语音识别 (ASR) 系统; 矢量量化 (VQ) 应用于源自预训练视频分类模型的低级时空视觉特征; 以及最近提出的 BERT 模型 [6],用于学习离散标记序列上的联合分布。
- 更准确地说,我们的方法是应用 BERT 来学习形式为
p
(
x
,
y
)
p(x, y)
p(x,y) 的模型,其中
x
x
x 是“视觉单词”序列,
y
y
y 是口语单词序列。 给定这样一个联合模型,我们可以轻松处理各种有趣的任务。 例如,我们可以执行文本到视频的预测,它可以用来自动说明一组指令(例如食谱),如图 1 和 2 的顶部示例所示。我们还可以执行更传统的密集视频字幕 [10] 的视频到文本任务,如图 6 所示。在第 4.6 节中,我们展示了我们的视频字幕方法显着优于以前的最新技术[ 39] 在 YouCook II 数据集 [38] 上。

- 图 1:VideoBERT 文本到视频的生成和未来预测。 (上)给定一些分成句子的食谱文本
y
=
y
1
:
T
y = y_1:T
y=y1:T ,我们通过使用 VideoBERT 计算
x
t
∗
=
a
r
g
m
a
x
k
p
(
x
t
=
k
∣
y
)
x_t ^*= argmax_k p(x_t = k|y)
xt∗=argmaxkp(xt=k∣y) 来生成视频标记序列
x
=
x
1
:
T
x = x_{1:T}
x=x1:T。 (下)给定一个视频代币,我们展示了 VideoBERT 在不同时间尺度上预测的前三个未来代币。 在这种情况下,VideoBERT 预测一碗面粉和可可粉可能会在烤箱中烘烤,并可能变成巧克力蛋糕或纸杯蛋糕。 我们使用最接近特征空间质心的训练集中的图像来可视化视频标记。

- 图 2:VideoBERT 的其他文本到视频生成和未来预测示例,详见图 1

- 图 6:VideoBERT 和 S3D 基线生成的字幕示例。 在最后一个示例中,VideoBERT 未能利用完整的时间上下文,因为它错过了纸巾帧。
- 我们还可以以“单峰”方式使用我们的模型。 例如,隐含的边际分布 p ( x ) p(x) p(x) 是视觉词的语言模型,我们可以将其用于长期预测。 这在图 1 和图 2 的底部示例中进行了说明。当然,未来存在不确定性,但该模型可以在比其他视频深度生成模型,例如基于 VAE 或 GAN 的那些(参见例如 [4, 5, 13, 27]),它们倾向于预测场景低级别方面的微小变化,例如少量对象的位置或姿势。
- 总之,我们在本文中的主要贡献是一种学习高级视频表示的简单方法,该表示捕获具有语义意义和时间长程结构。 本文的其余部分详细描述了这一贡献。 特别是,第 2 节简要回顾了相关工作; 第 3 节描述了我们如何将自然语言建模的最新进展应用于视频领域; 第 4 节介绍了活动识别和视频字幕任务的结果; 第 5 节结束。
相关工作
- 监督学习。 一些最成功的视频表示学习方法利用大型标记数据集(例如 [9、19、36、7])来训练卷积神经网络进行视频分类。 然而,收集此类标签数据的成本非常高,并且相应的标签词汇通常很小,无法表示多种动作的细微差别(例如,“sipping”与“drinking”略有不同,“drinking”与“gulping”略有不同)。 此外,这些方法旨在表示短视频剪辑,通常为几秒长。 我们工作的主要区别在于我们专注于视频中事件的长期演变,我们不使用手动提供的标签。
- 无监督学习。 最近,已经提出了多种从视频中学习密度模型的方法。 有些人使用单个静态随机变量,然后使用 RNN 将其“解码”成序列,使用 VAE 风格的损失 [32, 35] 或 GAN 风格的损失 [31, 17]。 最近的工作使用时间随机变量,例如 [4] 的 SV2P 模型和 [5] 的 SVGLP 模型。 还有各种基于 GAN 的方法,例如 [13] 的 SAVP 方法和 [27] 的 MoCoGAN 方法。 我们与这项工作的不同之处在于我们使用 BERT 模型,没有任何显式的随机潜在变量,应用于从视频派生的视觉标记。 因此,我们的模型不是像素的生成模型,而是从像素派生的特征的生成模型,这是一种已在其他工作中使用的方法(例如,[30])。
- 自我监督学习。 为了避免学习联合模型 p ( x 1 : T ) p(x_1:T) p(x1:T) 的困难,学习 p ( x t + 1 : T ∣ x 1 : t ) p(x_{t+1}:T |x_{1:t}) p(xt+1:T∣x1:t) 形式的条件模型变得很流行,我们将信号分成两个或更多块 ,例如灰度和颜色,或前一帧和下一帧(例如,[18]),并尝试从另一个预测一个(参见例如,[23] 的概述)。 我们的方法是相似的,除了我们使用量化的视觉词而不是像素。 此外,尽管我们学习了一组条件分布,但我们的模型是一个适当的联合生成模型,如第 3 节所述。
- 跨模式学习。 视频的多模态特性也是学习视频表示的广泛监督来源,我们的论文以此为基础。 由于大多数视频包含同步的音频和视觉信号,这两种模式可以相互监督以学习强大的自监督视频表示 [3,20,21]。 在这项工作中,我们使用语音(由 ASR 提供)而不是低级声音作为跨模态监督的来源。
- 自然语言模型。 我们以 NLP 社区的最新进展为基础,其中 ELMO [22] 和 BERT [6] 等大型语言模型在单词级别(例如, POS 标记)和句子级别(例如语义分类)。 然后将 BERT 模型扩展到对多语言数据进行预训练 [12]。 我们的论文建立在 BERT 模型之上,以捕捉语言和视觉领域的结构。
- 图像和视频字幕。 最近有很多关于图像字幕的工作(例如,参见 [11, 8, 15]),它是 p ( y ∣ x ) p(y|x) p(y∣x) 形式的模型,其中 y y y 是手动提供的字幕, x x x 是图像。 也有一些关于视频字幕的工作,使用手动提供的时间分割或估计分割(参见例如 [10, 39])。 正如我们在第 4.6 节中讨论的那样,我们使用我们的联合 p ( x , y ) p(x,y) p(x,y) 模型并将其应用于视频字幕,并获得最先进的结果。
- 教学视频。 各种论文(例如 [16, 2, 10, 38, 39])已经训练了模型来分析教学视频,例如烹饪。 我们与这项工作的不同之处在于我们不使用任何手动标记,并且我们学习了单词和(离散化)视觉信号的大规模生成模型。
模型
- 在本节中,我们简要总结 BERT 模型,然后描述我们如何将其扩展为联合建模视频和语言数据。
BERT模型
- BERT [6] 提出通过使用“掩码语言模型”训练目标来学习语言表示。 更详细地说,令
x
=
{
x
1
,
.
.
.
,
x
L
}
x = \{x_1, . . . , x_L\}
x={x1,...,xL} 是一组离散标记,
x
l
∈
X
x_l ∈ X
xl∈X 。 我们可以在这个集合上定义一个联合概率分布,如下所示:

- 其中 φ l ( x ) φ_l(x) φl(x) 是第 l l l 个势函数,参数为 θ θ θ, Z Z Z 是配分函数。
- 上述模型是置换不变的。 为了捕获顺序信息,我们可以“标记”每个单词在句子中的位置。 BERT 模型为每个词标记以及这些标签学习嵌入,然后对嵌入向量求和以获得每个标记的连续表示。 每个位置的对数势(能量)函数定义为

- 其中
x
l
x_l
xl 是第
l
l
l 个令牌(及其标签)的 one-hot 向量,并且

- 函数
f
(
x
\
l
)
f(x\backslash l)
f(x\l) 是一个多层双向 Transformer 模型 [28],它采用
L
×
D
1
L × D_1
L×D1 张量,包含对应于
x
\
l
x\backslash l
x\l 的 D1 维嵌入向量,并返回
L
×
D
2
L × D_2
L×D2 张量,其中
D
2
D_2
D2 是每个变压器节点的输出大小。 详见[6]。 该模型经过训练以近似最大化伪对数似然。

- 在实践中,我们可以通过采样位置和训练句子来随机优化 logloss(根据 f f f 函数预测的 softmax 计算)。
- BERT 可以通过将它们连接在一起来扩展为对两个句子进行建模。 然而,我们通常不仅对简单地对扩展序列建模感兴趣,而且对两个句子之间的关系感兴趣(例如,这是一对连续的还是随机选择的句子)。 BERT 通过在每个序列前面加上一个特殊的分类标记 [CLS],并用一个特殊的分隔标记 [SEP] 连接句子来实现这一点。 对应于 [CLS] 标记的最终隐藏状态用作聚合序列表示,我们从中预测分类任务的标签,否则可能会被忽略。 除了使用 [SEP] 标记来区分句子之外,BERT 还可以选择用它来自的句子标记每个标记。 对应的联合模型可以写成 p ( x , y , c ) p(x, y, c) p(x,y,c),其中 x x x 是第一个句子, y y y 是第二个句子, c = { 0 , 1 } c = \{0, 1\} c={0,1} 是一个标签,指示句子在源文档中是分开的还是连续的。
- 为了与原始论文保持一致,我们还在序列末尾添加了一个 [SEP] 标记,尽管它并不是严格需要的。 因此,典型的掩蔽训练句对可能如下所示: [CLS] let’s make a traditional [MASK] cuisine [SEP] orange chicken with [MASK] sauce [SEP]。 在这种情况下,相应的类标签将是 c = 1 c = 1 c=1,表示 x x x 和 y y y 是连续的。
VideoBERT模型
- 为了将 BERT 扩展到视频,我们仍然可以利用预训练的语言模型和可扩展的实现进行推理和学习,我们决定进行最小的更改,并将原始视觉数据转换为离散的令牌序列。 为此,我们建议通过对使用预训练模型的视频派生的特征应用分层向量量化来生成“视觉词”序列。 有关详细信息,请参阅第 4.2 节。 除了简单之外,这种方法还鼓励模型专注于视频中的高级语义和更长期的时间动态。 这与大多数现有的视频表示学习的自我监督方法形成对比,后者学习低级属性,如局部纹理和运动,如第 2 节所述。
- 我们可以将语言句子(源自使用 ASR 的视频)与视觉句子相结合,生成如下数据: [CLS] orange chicken with [MASK] sauce [>] v01 [MASK] v08 v72 [SEP],其中 v01 和 v08 是视觉标记,[>] 是我们引入的特殊标记,用于结合文本和视频句子。 参见图 3 中的说明。
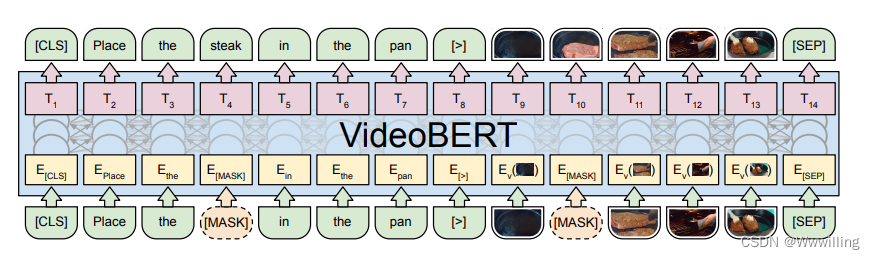
- 图 3:VideoBERT 在视频和文本掩码标记预测或完形填空任务上下文中的图示。 此任务还允许使用纯文本和纯视频数据进行训练,并且 VideoBERT 还可以使用语言-视觉对齐分类目标进行训练(此处未显示,详见文本)。
- 虽然这个完形填空任务自然地扩展到语言和视觉标记序列,但应用 BERT 使用的下一句预测任务并不那么简单。 我们提出了一个语言视觉对齐任务,我们使用 [CLS] 标记的最终隐藏状态来预测语言句子是否与视觉句子在时间上对齐。 请注意,这是语义相关性的嘈杂指标,因为即使在教学视频中,说话者也可能指的是视觉上不存在的东西。
- 为了解决这个问题,我们首先将相邻的句子随机连接成一个长句子,以允许模型学习语义对应,即使两者在时间上没有很好地对齐。 其次,由于即使是相同动作的状态转换速度在不同视频之间也会有很大差异,我们随机选择视频标记的 1 到 5 步的子采样率。 这不仅有助于模型对视频速度的变化更加稳健,而且还允许模型在更大的时间范围内捕获时间动态并学习更长期的状态转换。 我们将对结合视频和文本的其他方式的调查留给未来的工作。
- 总体而言,我们有对应于不同输入数据模式的三种训练方案:纯文本、纯视频和视频文本。 对于纯文本和纯视频,标准掩码完成目标用于训练模型。 对于文本视频,我们使用上述语言视觉对齐分类目标。 总体培训目标是各个目标的加权总和。 文本目标迫使 VideoBERT 在语言建模方面做得很好; 视频目标迫使它学习“视频语言模型”,可用于学习动态和预测; 文本视频目标迫使它学习两个域之间的对应关系。
- 一旦我们训练了模型,我们就可以在各种下游任务中使用它,在这项工作中,我们定量评估了两个应用程序。 在第一个应用程序中,我们将其视为概率模型,并要求它预测或估算已被屏蔽掉的符号。 我们在第 4.4 节中对此进行了说明,我们在其中执行“零样本”分类。 在第二个应用程序中,我们提取 [CLS] 标记的预测表示(源自模型的内部激活),并使用该密集向量作为整个输入的表示。 这可以与源自输入的其他特征相结合,以用于下游监督学习任务。 我们在第 4.6 节中演示了这一点,我们在其中执行视频字幕。