有关于Transformer、BERT及其各种变体的详细介绍请参照笔者另一篇博客:最火的几个全网络预训练模型梳理整合(BERT、ALBERT、XLNet详解)。
本文基于对T5一文的理解,再重新回顾一下有关于auto-encoder、auto-regressive等常见概念,以及Transformer-based model的decoder结构。
1. Auto-encoder & Auto-regressive Language model
1.1 Auto-encoder
类似于BERT、ALBERT、RoBERTa这类,encoder-only的language model。
优点:
- 能够保证同时上下文。
缺点:
- token之间的条件独立假设。违反自然语言生成的直觉性。
- encoder-only的时候,预训练目标不能和很多生成任务一致。
而结合预训练的时候的objective,像BERT这类Masked Language Model (MLM)又可以叫做denoised Auto-encoder(去噪自编码)。
1.2 Auto-regressive
类似于ELMO、GPT这类,时序LM和decoder-only LM。
传统的时序Language Model ,类似于RNN、ELMO,严格意义上不能叫做decoder;只是后来出现了大量基于transformer的auto-regressive LM,比方说GPT等,它们都是用作文本生成直接解码输出结果。所以在”transformer时代“下,Auto-regressive现在很多时候也被简单地理解为decoder-only。大致概念可以按下图理解:
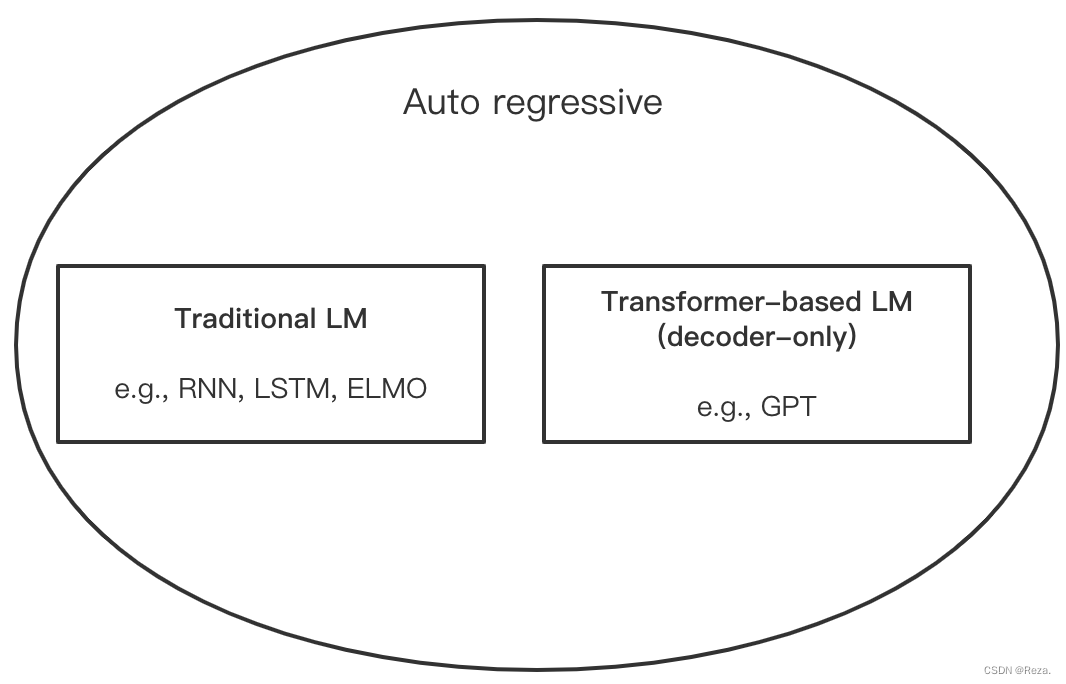
优点:
- 无条件独立假设。
- 预训练可以直接做生成任务,符合下游生成任务的objective。
缺点:
- 不能同时双向编码信息(像ELMO这种是”伪双向“,而且容易“透露答案”)。
而目前自然语言处理的auto-regressive结构,大多基于Transformer;像传统时序LM,ELMO这种也已经快被遗忘了。
2. Transformer-based model 结构概览
如前文所述,我们目前理解LM (autoencoder & autoregressive),大多是基于transformer的结构的。所以这一节暂时不讨论传统时序LM,ELMO这种。
T5一文1曾对Transformer的经典结构进行过概述,主要分为以下三种:
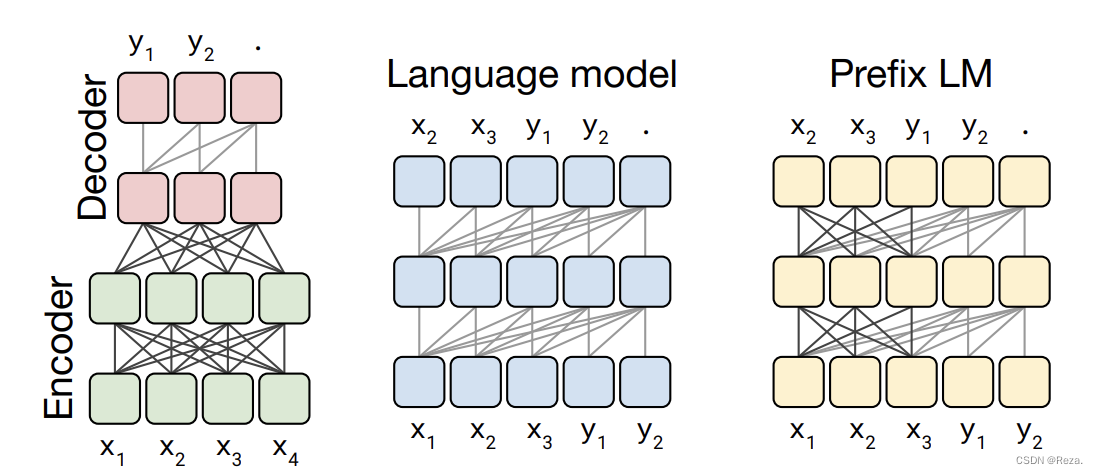
- Encoder-only Language Model:也即Auto-encoder。如第一节所述,特点是,能同时双向编码。代表有:
BERT、RoBERTa等。 - Decoder-only Language Model(上图,中):也即Auto Regressive (不包括传统的时序模型),可以简单理解成只有Decoder。特点是,只能看到前文信息(因为decoder-only)。代表有:
GPT等。 - Encoder-Decoder:也即Auto-encoder + Auto regressive(上图,左)。最原始的Transformer结构,encoder和decoder都有self-attentino支持,decoder还有额外的cross-attention用来结合encoder的输出信息。特点是,encoder能够同时看到上下文双向信息,而decoder只能看到前文信息。代表有:
BART、T5等,这也使得这类模型特别适合生成式任务。 - Prefix LM:可以简单地理解为Encoder-Decoder结构的变形(上图,右)。特点是,一部分像 Encoder 一样,能看到上下文信息;而其余部分则和 Decoder 一样,只能看到过去信息。代表有
UniLM等·。
而Transformer结构,如果想要实现所谓的,“同时上下文信息”、“只看到前文信息”,则需要依赖masked attention,因为transformer的self-attention,默认是全文计算attention,想要部分不可见,就得mask。这一点和传统时序LM不一样,像RNN这种,下一个token依赖于前文的hidden state,天然地就只能看到前文信息。
下面就以Encoder-Decoder LM为例,讲一下如何使用attention,实现encoder看到全文,而decoder只看到前文。
3. Encoder-Decoder的masked attention机制
这里以T5的代码为例。Transformer中的mask其实分为两种:1)padding mask;2)sequence mask。
3.1 Padding mask vs. Sequence mask
padding mask很简单,就是我们常用的同一个batch里面,把那些较短的样本,补至最长的样本长度。因为这些填充的位置,其实是没什么意义的,所以Attention机制不应该把注意力放在这些位置上,自然会在padding 位置进行attention mask。这个操作在encoder和decoder中都有用到,只是一个简单的tensor批量运算操作。
sequence mask是为了使得Decoder只能看见上文信息。所以当前step之后的文本信息,都会被mask掉。这个操作仅在decoder中使用。
总而言之,上述两种mask方式中,sequence mask是用于实现模型是否可见后文信息的关键。
3.2 Encoder
Encoder用的是全部的上下文信息,所以这边的sequence mask全部为0,形状为【batch_size, 1,1, seq_len】:
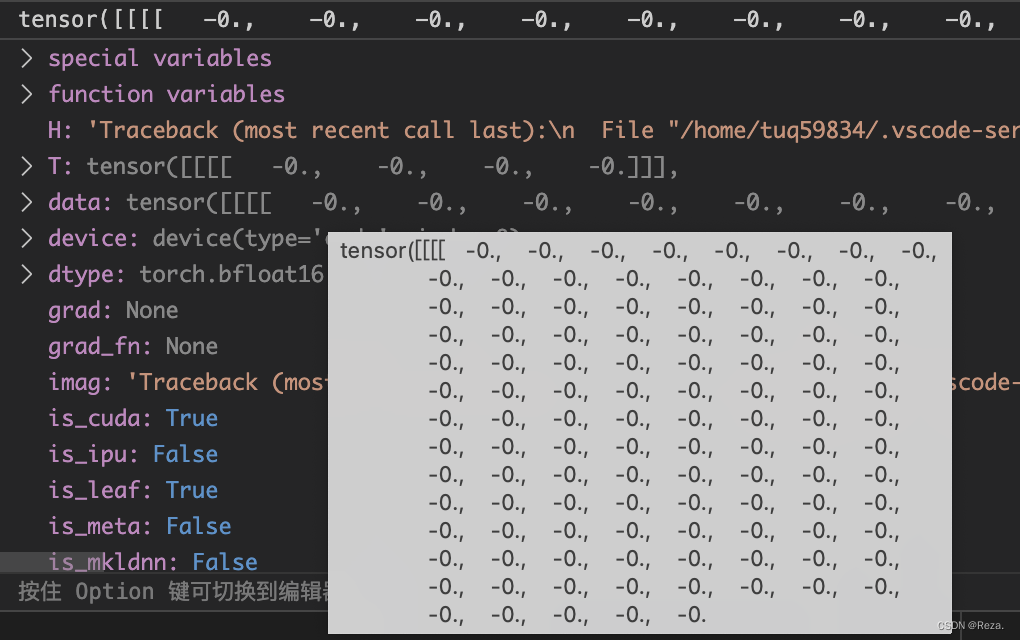
3.3 Decoder
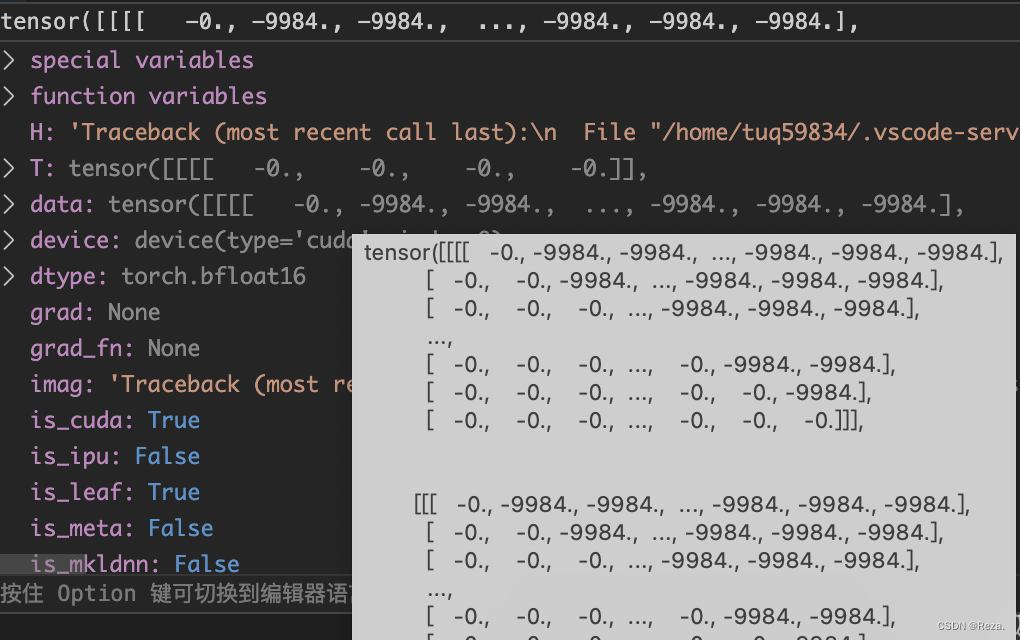
Dncoder用的是前文的信息,所以这边的attention mask是一个矩阵 (seq_len * seq_len),其中下三角全0,迫使模型只能看到输入中的前文信息。如下图所示,sequence mask的实际形状为【batch_size, 1, seq_len, seq_len】
3.4 Encoder 和Decoder的区别
这里最后再简单总结一下Encoder-Decoder结构的LM,其Encoder和Decoder之间的区别。
首先,decoder有三层,sub-layer[1]计算self-attention,sub-layer[2]计算cross- attention,sub-layer[3]则是Linear层把最终hidden印射为vocab_size的logits。
所以decoder相较于encoder,其大部分结构和计算都是一样的,只不过多出这三个部分:
- sequence mask:Decoder在计算sub-layer[1]的self-attention时,有sequence mask机制,确保只看到前文信息;而Encoder没有,计算self-attention时默认看到全文。
- cross-attention:Decoder的sub_layer[2]会计算cross-attention。具体来讲,这一层会使用encoder的output hidden作为k,v,而sub-layer[1]的self-attention的output作为q,来进行self-attention的计算。这是为了让decoder充分融合encoder端的信息,所以名为“cross-attention”。
- linear+softmax:最后sub_layer[3]会有一个映射层,输出每个token的词表概率预测。
参考
- [1] Raffel C, Shazeer N, Roberts A, et al. Exploring the limits of transfer learning with a unified text-to-text transformer[J]. J. Mach. Learn. Res., 2020, 21(140): 1-67.;paper
- [2] 知乎——T5 模型:NLP Text-to-Text 预训练模型超大规模探索
- [3] 知乎——【精华】BERT,Transformer,Attention(中)
- [4] CSDN——最火的几个全网络预训练模型梳理整合(BERT、ALBERT、XLNet详解)