—0526在啃黄瓜,已经看了一会沐沐叻。
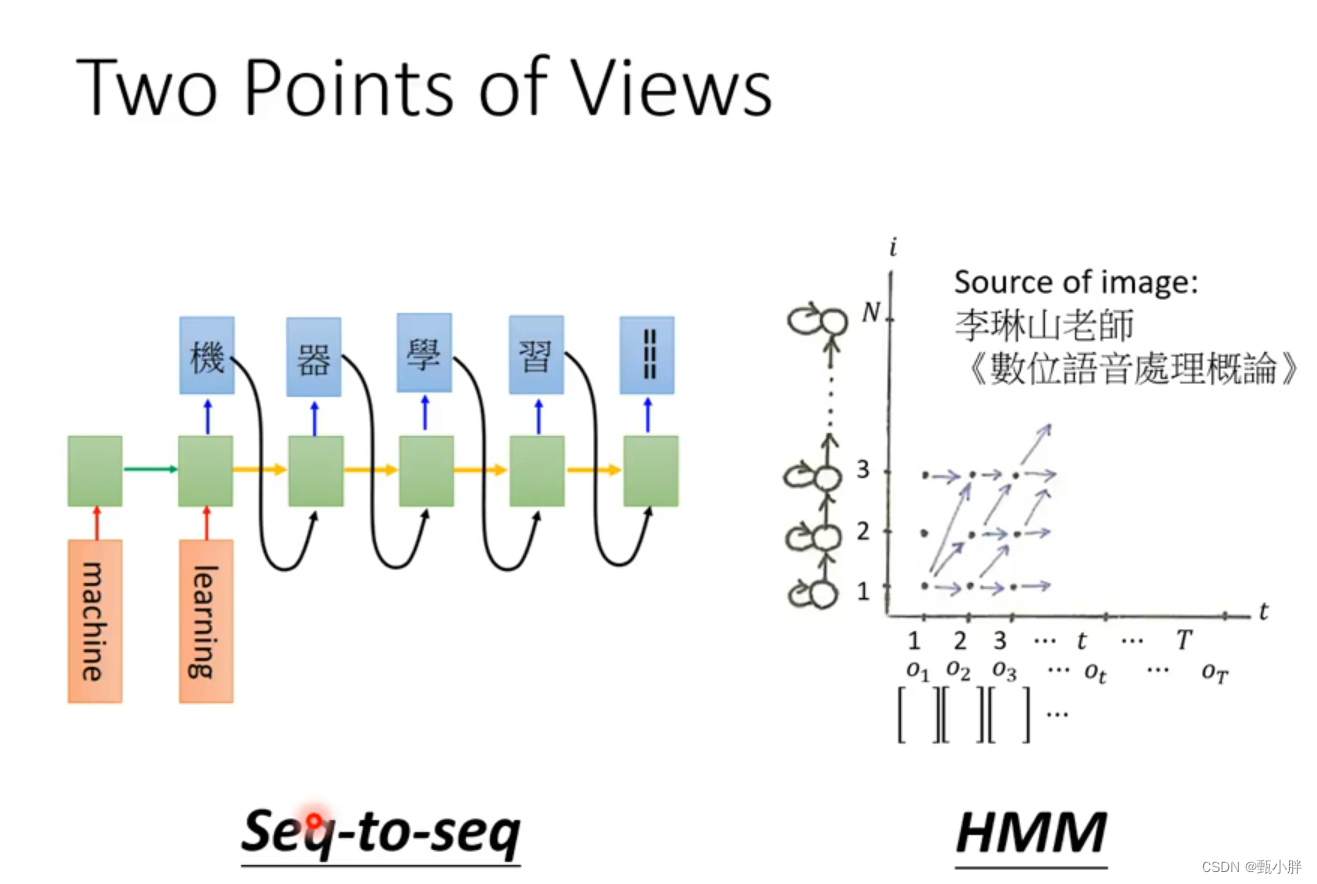
1、Trandformer
看着看着简直要喷黄瓜了hhhhhhhh。
Tranformer也挺简单的,我一张ppt就讲完了。
不过这张ppt做的挺好的hhhh
-------0600看完了transformer,但对应代码还没看,看了多头的代码。打算先code一下。
越来越觉得数学美了(主要是自己渐渐能看懂了),美就美在明确、简洁。
2、多头注意力

我只想说,ipad+pencil真的是学习dl神奇。维度之间的事情,用笔画一画就可以解决了。
—0720
数学推导太爽了!!收拾宿舍去!
----0816回来把的多头注意力的代码写完了、趴一会,去看看夏一部分了。
–0830开始开始!
3\多头自注意力机制
其实就是把q,和k-v都换成是自己。
刚刚的多头注意力,q是x,k-v是y。也就是q和k-v不一样。
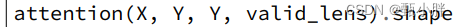
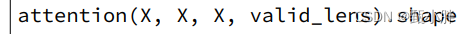
—0905听着听着感觉代码量好大哇~但也正是提高的机会呢!
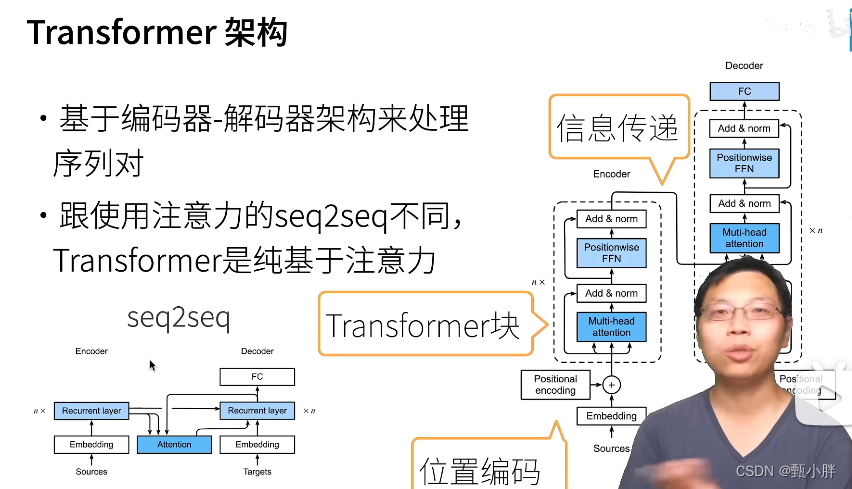
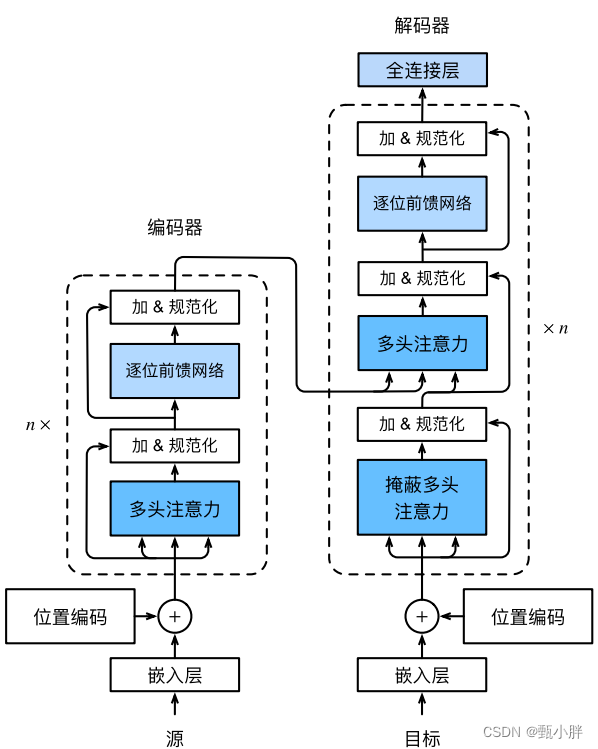
4、Transformer
1\Transformer 完全基于注意力机制,没有任何卷积或者循环神经网络的操作。
这段文字好精华啊
总结一下:
1、编码器两个模块:多头注意力+逐位前馈网络
(1)多头注意力是自注意力,后面再加上残差和规范化(layer-normalization),而且输入和输出的shape是相同的,这样可以保证能够重复n次。
(2)逐位前馈网络
这个其实就是两层全连接,为了解决3位其中不确定的n的问题,也就是全连接啦
2、解码器三个模块:
(1)掩蔽多头注意力:和encoder比,多了掩蔽,主要是因为我们不能提前知道后面的东西.用mask实现就好。后面进行残差+layer_normalization
(2)【new-old】这个模块是encoder中么有的,但是在seq2seq模型里还是比较常见的。这个模块的Attention不是自注意力,而是普通的注意力。Q选取刚刚的masked-multi-attention的输出,而K-V选取编码器的输出。后面再加上残差和layer-normalization。
(3)第三个模块还是逐位前馈网络,实现一个三个维度的全连接。
最后通过一个FC得到结果。

5\疑问:基于位置的前馈网络,还是不懂为啥,不过李沐大大也没解释hhhhhhhhhh说,就是个全连接hhhhh
他的意思莫非是展开了,然后用一个mlp直接一起处理不同sample的steps?然后这个MLP的输入信息是还有sequence信息的???一会再查查叭。
啊这。。查了一下,好像就也只是。。。简单全连接的感觉

6、层规范化
在自然语言处理任务中,输入的通常是变长序列,批量规范化,不如层规范化好。
层规范化,就是基于特征维度进行规范化,也就是说,不同batch的seq长度可能不同,虽然认为pre了相同长度,但还是有pad存在,所以不同sample之间不好做规范化,可以一句话内自己进行规范,也就是层规范化。
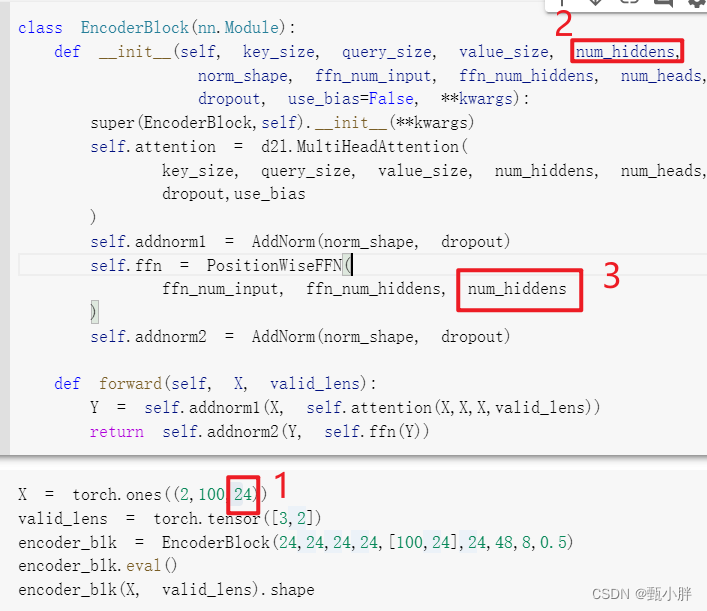
7\num_hiddens
num_hiddens(如标号2所示)的数量就是X的dim【2】(如标号1所示)的大小——也就是用多少个neuron表示一个token。为了做n层,输入输出的shape应该是相同的,所以最后的第三位也要转换成num_hiddens那么大(如标号3所示)
**
补充:其实这个num_hiddens就是embedding的那个num_hiddens,也就是表示一个token的神经元的个数啦。 我感觉这里ffn的第一个参数写的是input而不是num_hiddens可能是随意写的,或者是为了后期的灵活性?至少从现在看来,他这里的使用ffn_num_input的大小都和num_hiddens是一样的,(因为最初shi的输入是经过embedding来的,最后一维度大小为num_hiddens;后面的输出由于ffn的output的大小为num_hiddens,所以后面的第三维度的大小也都为num_hiddens)。这里看,着实没有必要单独写这个ffn_num_input,不知道是不是为了后期操作呢???
**
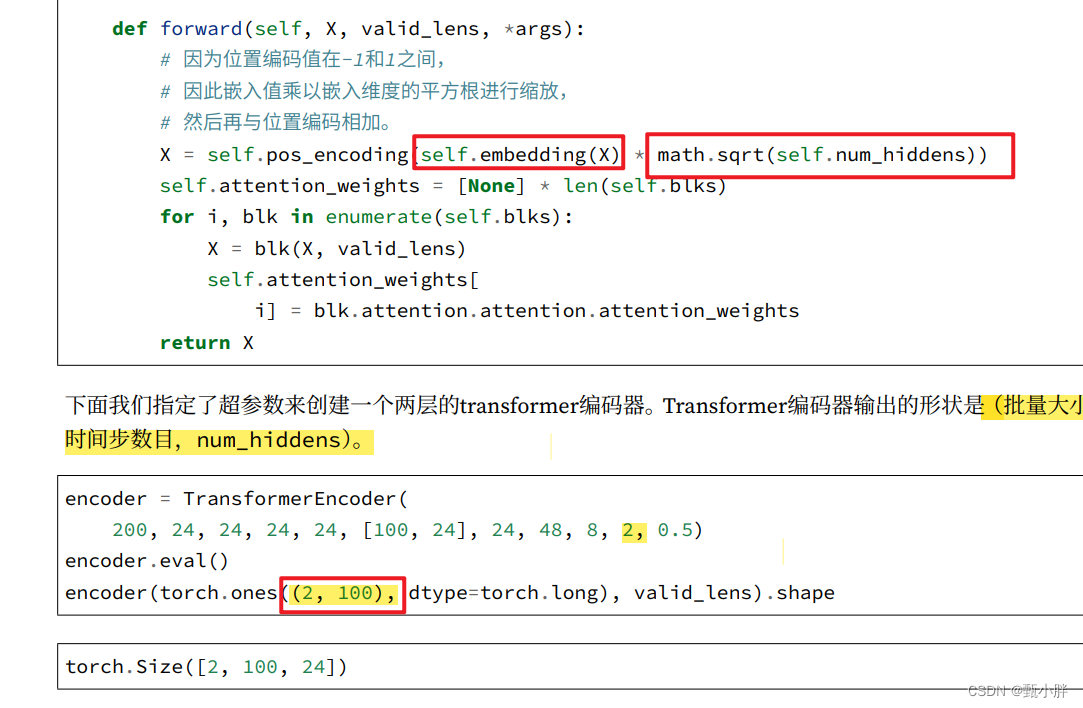
对输入嵌入进行缩放

pos_encoding是做一个位置码+原来x的embedding的操作,但我感觉是embedding时做了scale,导致的X的每个量太小了,再加上pos又都在-1和1之间,会导致pos占主导地位,而本身X的信息不matter,所以先把X放大些,调整一下和pos信息的比例。
—1024休息一下下。。
TransformerEncoder测试
TransformerEncoder之所以传入的是二维的(batch,steps),是因为我们在这个TransformerEncoder里面内置了embedding层,可以将其变为num_hiddens个。
-------1051去打饭干饭啦!!!!!!
-------1356
看一个小时,争取把bert看完,就去做核酸啦~
本来这里有点不清楚,又看了一遍,懂了。
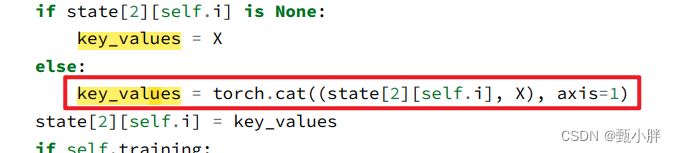
在预测的时候,我们的注意力是去看之前的输入和现在的输入,
我们在这里把他们cat起来,然后赋给key_values。一点点叠。
i表示第i个块,所以每个块都是分别叠的。
—1549做完核酸回来啦~顺便快把bert的代码视频看完了!!!棒棒!!!先看完最后一点
----1554顺便把微调看了叭!!但我感觉自己基本也知道啦!
—1622感觉要下雨了诶,想去跑个步!!!BERT微调也看完了哦!!一会把两课的QA看了!
—1829外面太阳好大,一会再去跑步。
—1838两个Q&A都看完啦~敲敲代码啦
8decoder的第二个attention做了类似于seq2seq的连接
从代码上看,应该是n个encoder和decoder对应的之间都做了query的。
因为在decoder里面之间forloop了num_layers个blk,每个blk都是三个模块,第二个模块介绍一个attention。
刚开始传过来encoder的state;
然后返回decoder i=1的state;
下次再更新为i=2的state
额鹅鹅鹅这么看,就相互查了1次呀。

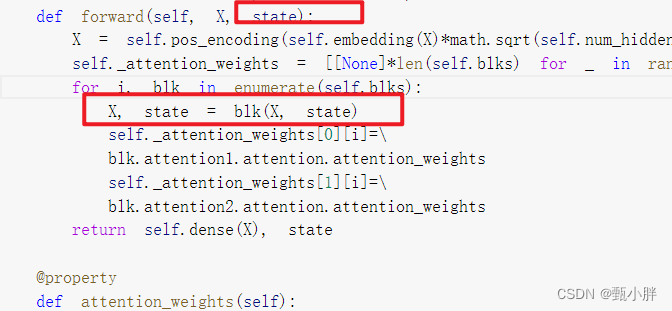
9EncoderDecoder复习
主要是在forward中运行encoder,得到enc_outputs,再放入decoder.init得到dec_state,最后返回decoder结果。
所以,decoder里面的init_state就是根据enc_outputs【&enc_valid_lens】得到decoder初始化的一些信息【dec_state】。
再将dec_state放入decoder,和dec_X一起,得到最后的值。
妙蛙!

----2224嗯嗯搞明白了,transformer的每个decoder都会去查询最后一个encoder的output。代码上也是这个意思,尽管state一直在更新,但其实state[0]和state[1]并没有update,只是state[2]在变。
我在周五答辩,期待回家!
明天把bert代码跑一跑,可以结束沐沐的课,开nlp和读论文啦!!1